
[CSAPP大作業] 程式人生-Hello's P2P
本文主要介紹hello程式在linux下是如何從一個.c檔案一步步變成可執行檔案的。對於在執行的過程中可能會出現的一些比較重要的問題,例如虛擬記憶體,IO等操作進行探究。
關鍵詞:程式執行 CSAPP
目 錄
2.2在Ubuntu下預處理的命令............................................................................. - 5 -
5.3 可執行目標檔案hello的格式........................................................................ - 8 -
6.2 簡述殼Shell-bash的作用與處理流程........................................................ - 10 -
6.3 Hello的fork程序建立過程......................................................................... - 10 -
7.2 Intel邏輯地址到線性地址的變換-段式管理............................................... - 11 -
7.3 Hello的線性地址到實體地址的變換-頁式管理.......................................... - 11 -
7.4 TLB與四級頁表支援下的VA到PA的變換................................................ - 11 -
7.5 三級Cache支援下的實體記憶體訪問............................................................. - 11 -
7.6 hello程序fork時的記憶體對映..................................................................... - 11 -
7.7 hello程序execve時的記憶體對映................................................................. - 11 -
7.8 缺頁故障與缺頁中斷處理.............................................................................. - 11 -
8.2 簡述Unix IO介面及其函式.......................................................................... - 13 -
第1章 概述
1.1 Hello簡介
P2P過程:首先先有個hello.c的c程式文字,經過預處理->編譯->彙編->連結四個步驟生成一個hello的二進位制可執行檔案,然後由shell新建一個程序給他執行。
020過程:shell執行他,為其映射出虛擬記憶體,然後在開始執行程序的時候分配並載入實體記憶體,開始執行hello的程式,將其output的東西顯示到螢幕,然後hello程序結束,shell回收記憶體空間。
1.2 環境與工具
硬體環境:X64 CPU Intel Core i7 6700HQ; 3.2GHz; 16G RAM; 1TB HD Disk
軟體環境:Microsoft Windows10 Home 64位; VMware Workstation 14 Pro; Ubuntu 18.04
開發工具:gcc,readelf,edb
1.3 中間結果
| 檔名稱 |
作用 |
| hello.c |
原始碼 |
| hello.i |
預處理之後的文字檔案 |
| hello.s |
編譯之後的彙編檔案 |
| hello.o |
彙編之後的可重定位目標執行 |
| hello |
連線之後的可執行目標檔案 |
1.4 本章小結
本章主要簡單介紹了hello的P2P,020過程,列出了本次實驗資訊:環境、中 間結果。
第2章 預處理
2.1 預處理的概念與作用
預處理是計算機在處理一個程式時所進行的第一步,他直接對.c檔案進行初步處理將處理後的結果儲存在.i檔案中,隨後計算機再利用其它部分接著對.i檔案進行處理。
2.1.1預處理的概念
計算機用前處理器(cpp)來執行預處理操作,操作的物件就是原始程式碼中以字元#開頭的命令,hello.c中就包含了三條這樣會被預處理的語句,如下圖2-1中所示的程式碼;除了呼叫庫這樣的操作之外,程式中的巨集定義也會在預處理的時候處理,如圖2-2所示;最後預處理階段會將程式中的註釋刪除掉,因為這對程式接下來的操作是沒有用的。
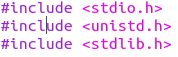

圖2-1 hello.c中的標頭檔案 圖2-2 巨集定義
2.1.2預處理的作用
預處理的過程中,對於引用一些封裝的庫或者程式碼的這些命令來說,他會告訴前處理器讀取標頭檔案中用到的庫的程式碼,將這段程式碼直接插入到程式檔案中;對於巨集定義來說,會完成對巨集定義的替換;註釋會直接刪除掉。最後將處理過後的新的文字儲存在hello.i中,後面計算機將直接對hello.i進行操作。
預處理階段的作用是讓編譯器在隨後對文字進行編譯的過程中,更加方便,因為訪問庫函式這類操作在預處理階段已經完成,減少了編譯器的工作。
2.2在Ubuntu下預處理的命令
首先先來介紹一下如何在shell中執行對.c檔案的預處理操作:
linux> gcc –E –o hello.i hello.c
在這裡運用-o操作,將結果輸出到hello.i檔案中,方便我們對預處理過後的檔案進行檢視。我們可以看一下預處理前後兩個檔案大小的差距,如圖2-3所示,預處理前的hello.c檔案只有534位元組,而預處理後的hello.i檔案有66102位元組。可見預處理工作中對文字做了很大的改動和補充。
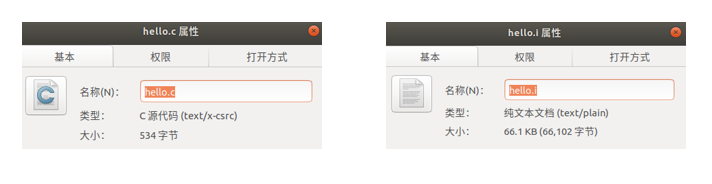
圖2-3 預處理前後文件大小
2.3 Hello的預處理結果解析
我們在2.1節中說到過,預處理只對開頭是#的命令進行操作。也就是說,對於我們程式中定義的變數、寫的函式等這些操作,預處理階段是不會管的,我們首先就來對比一下這一部分。如圖2-4所示,在預處理之前,程式中包含開始的註釋內容、標頭檔案、全域性變數和主函式。而右側是預處理過後的檔案,這裡展示了檔案的最後幾行,可以看到,從全域性變數的定義開始,與預處理之前的檔案完全相同,這與2.1中的概念相符。

圖2-4 預處理前後的程式文字
接下來我們回到hello.i檔案的開頭,從圖2-5中可以看出,hello.i程式中並沒有了註釋部分。最後我們再來看hello.i文字的中間部分,首先我們看到左側的圖中從第13行開始有很多的地址,還有如右側圖中的一些程式碼部分,右側圖中就是一個結構體變數。這說明,預處理階段,前處理器將需要用到的庫的地址和庫中的函式加入到了文字中,與我們原來不需要預處理的程式碼一同構成了hello.i檔案,用來被編譯器繼續進行編譯。

圖2-5 hello.i檔案內容
2.4 本章小結
預處理過程是計算機對程式進行操作的起始過程,在這個過程中前處理器會對hello.c檔案進行初步的解釋,對標頭檔案、巨集定義和註釋進行操作,將程式中涉及到的庫中的程式碼補充到程式中,將註釋這個對於執行沒有用的部分刪除,最後將初步處理完成的文字儲存在hello.i中,方便以後的核心器件直接使用。
第3章 編譯
3.1 編譯的概念與作用
3.1.1編譯的概念
編譯階段是在預處理之後的下一個階段,在預處理階段過後,我們獲得了一個hello.i檔案,編譯階段就是編譯器(ccl)對hello.i檔案進行處理的過程。此階段編譯器會完成對程式碼的語法和語義的分析,生成彙編程式碼,並將這個程式碼儲存在hello.s檔案中。
3.1.2編譯的作用
編譯器會在編譯階段對程式碼的語法進行檢查,如果出現了語法上的錯誤,會在這一階段直接反饋回來,造成編譯的失敗。如果在語法語義等分析過後,不存在問題,編譯器會生成一個過渡的程式碼,也就是彙編程式碼,在隨後的步驟中,彙編器可以繼續對生成的彙編程式碼進行操作。
這裡有一個問題,就是為什麼我們在預處理的過程中生成的比較大的hello.i檔案,在進行完彙編過程後生成的hello.s檔案又變小了。我們可以發現,hello.s檔案中只儲存了標頭檔案之後的彙編程式碼,至於之前加入的標頭檔案的程式碼具體去了哪裡,會在第五章連結進行介紹。
3.2 在Ubuntu下編譯的命令
我們可以利用如下指令來對hello.i文字繼續進行編譯:
linux> gcc –S hello.i –o hello.s
從圖3-1中我們可以看到,利用上述命令編譯過後,我們得到了一個hello.s
檔案。
圖3-1 在Ubuntu下編譯的命令
3.3 Hello的編譯結果解析
我們將程式碼分成資料、賦值、型別轉換、算數操作、控制轉移陣列/指標/結構操作和函式操作這麼幾個部分來具體分析一下。
3.3.1資料
關於資料的定義,我們可以看到hello.c中有一條如圖3-2中的語句,這條語句定義了一個sleepsecs的全域性變數。對應到hello.s檔案中,就是圖中右側的部分。我們可以看到定義的過程中用.globl聲明瞭這是一個全域性變數;.type說明了型別是一個數據;.size說明了這個變數的大小,這裡sleepsecs變數佔了4個位元組。關於.text和.type的具體含義及其作用會在第5章連線中進行講解。
需要注意的一點是其實main函式中還定義了i變數,但是i由於是區域性變數,所以彙編器並沒有單獨的對他進行處理,而是直接將在這個變數放到了暫存器中。具體是如何控制這個變數的,會在下一小節中介紹。

圖3-2 資料的定義
3.3.2賦值
我們從上面的圖中可以看到,在定義sleepsecs變數的過程中,同時對其進行了賦值在hello.s中。圖3-3中的語句就是賦值操作轉化成彙編之後的語句。可以看到一共有三行,第一行聲明瞭變數名,第二行中儲存的是變數的值,第三行中是儲存的位置,也就是.rodata節中(第五章連結的內容)。有一個問題,那就是上圖中的賦值語句中是將2.5賦值給了這個變數,為什麼在彙編之後就變成了2。注意sleepsecs這個變數的型別是整型,但是2.5是一個浮點型,所以只儲存了整數的部分,具體我們會在下一小節中介紹。

圖3-3 sleepsecs的賦值
接下來我們看一下區域性變數i是如何進行賦值的。可以注意到hello.s的36行中有一個對暫存器的定址操作,這個操作將0放入到了這個地址中。可以確定這個就是對變數i的初始化,因為i是區域性變數,所以直接可以在棧中用一個單元儲存這個值,就不需要單獨進行處理了。

圖3-4 區域性變數i的賦值
3.3.3型別轉換
這裡的型別轉換採用的是隱式的轉換。我們可以從上一節的sleepsecs的賦值中可以看出,彙編器並沒有對型別轉換做特別的程式碼上的處理,而是直接將2賦值給了sleepsecs。這說明彙編器在對hello.i檔案進行彙編的過程中,直接在這個過程中進行了程式碼的優化,也就是說在編譯的過程中就完成了浮點型的轉換,將其賦值給了整型,而並沒有在彙編程式碼中通過具體的程式碼實現,所以對於型別轉換而言,是隱式的。
3.3.4算數操作
在hello.c的程式碼中,只涉及到了一處算數操作,就是在for迴圈中每次對i進行的加一操作。在3.3.2節中,我們已經看到了,i儲存在暫存器中儲存的一個地址中,所以如圖3-5所示,對於i的運算,我們可以直接對暫存器儲存的地址中的值進行操作,每次我們將這個值增加1。需要注意的一點是,每次我們進行的是定址操作,是將地址中的值加1,而不是將地址加一。
![]()
圖3-5 算數操作
3.3.5關係
在hello.c中有兩個關係操作,分別如圖3-6所示,一個是不等於操作,另一個是小於操作。具體到彙編程式碼中我們看到他們分別對應了兩句操作。一個是cmpl另一個是一個j加上一些字母。

圖3-6 邏輯操作
這裡就需要用到組合語言的相關知識了。首先cmpl是一個比較函式,這個函式中將比較的結果儲存在條件碼中。條件碼中一共有四位,每一位都有不同的含義。如圖3-7中所示。對於不同的比較結果,操作碼中就儲存了不同的值。關於下一行中儲存的資訊的具體作用,將在下一小節中進行介紹。

圖3-7 操作碼
3.3.6控制轉移
我們看到,上一節中在每一個cmpl的操作之後,都緊跟著一個j的操作,這個j的含義就是jmp,起到控制函式跳轉的作用,j後面跟的引數,就對應了在滿足什麼條件的時候進行跳轉。圖3-8中列出了不同跳轉指令的含義。我們可以看到,對於每一種跳轉指令都對應了跳轉碼的一種形式。所以我們就可以知道,為什麼在上一節中,cmpl和j這兩條語句總是同時出現。是因為在執行條件跳轉的時候,我們必須利用到操作碼中的值。所以在每個條件跳轉之前,都肯定有一個比較指令對操作碼進行設定。

圖3-8 條件跳轉指令
瞭解了條件跳轉指令是如何執行的之後,我們可以看一下hello.s中具體的編譯結果了。我們看圖3-9中,右側的彙編程式碼的29和30行在執行左側程式碼中的if判斷操作,通過3-8中的表格我們可以知道je是相等時跳轉,也就是說,當argc等於3的時候,那麼就跳轉到.L2處執行,否則就繼續向下執行。通過對L2的閱讀以及L3中的操作我們可以知道,這是一個迴圈操作,也就正好對應了左側程式碼中的情況。
通過上面對彙編程式碼的分析,我們可以瞭解彙編是如何控制程式在不同地方進行跳轉的了。

圖3-9 彙編中的條件跳轉
3.3.7陣列/指標/結構操作
hello.c中在輸出的時候呼叫了argv陣列中的元素。如圖3-10所示,我們可以看到,在彙編中,我們已經沒有了陣列、結構等概念,我們有的只是地址和地址中儲存的值。所以對於一個數組的儲存,在彙編中我們只儲存了他的起始地址,對應的也就是argv[0]的地址,對於陣列的中其他元素,我們利用了陣列在申請的過程中肯定是一段連續的地址這樣的性質,直接用起始地址加上偏移量就得到了我們想要的元素的值。

圖3-10 陣列操作
3.3.8函式操作
圖3-11中展示瞭如何對函式進行呼叫。首先我們應該先了解一下呼叫函式的過程中我們會用到哪些東西。
%eax暫存器中儲存了函式的返回值。作為一個函式,我們肯定需要向函式內進行傳參操作,對於引數比較少的情況來說,就直接儲存在特定的暫存器中,如%rdi,%rsi,%rdx,%rcx就分別用來儲存第一至四個引數。X86的及其一共為我們提供了6個暫存器來儲存引數。如果引數多於6個,那麼就只能放在棧中儲存了。
如圖中56行所示,我們直接利用call指令,後面加上呼叫函式的名稱,就直接可以去到被呼叫的函式的位置。在被呼叫的函式執行完畢之後,程式會將函式的返回值存在%eax中,然後執行ret語句,將函式程式返回到呼叫的地方。這樣就完成了整個的函式呼叫。
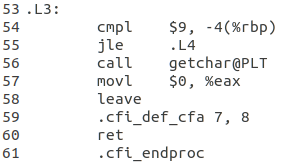
圖3-11 函式操作
3.4 本章小結
本章我們主要介紹了編譯器是如何將文字編譯成彙編程式碼的。可以發現,編譯器並不是死板的按照我們原來文字的順序,逐條語句進行翻譯下來的。編譯器在編譯的過程中,不近會對我們的程式碼做一些隱式的優化,而且會將原來程式碼中用到的跳轉,迴圈等操作操作用控制轉移等方法進行解析。最後生成我們需要的hello.s檔案。
第4章 彙編
4.1 彙編的概念與作用
4.1.1彙編的概念
彙編器(as)將hello.s檔案翻譯成機器語言指令,把這些指令打包成一種叫做可重定位目標程式的格式,並將結果儲存在hello.o中。這裡的hello.o是一個二進位制檔案。
4.1.2彙編的作用
我們知道,彙編程式碼也只是我們人可以看懂的程式碼,而機器並不能讀懂,真正機器可以讀懂並執行的是機器程式碼,也就是二進位制程式碼。彙編的作用就是將我們之前再hello.s中儲存的彙編程式碼翻譯成可以攻機器執行的二進位制程式碼,這樣機器就可以根據這些01程式碼,真正的開始執行我們寫的程式了。
4.2 在Ubuntu下彙編的命令
我們可以利用如下指令來對hello.s進行彙編:
linux> gcc –c hello.s –o hello.o
從圖4-1中我們可以看到,利用上述命令編譯過後,我們得到了一個hello.o
檔案。
圖4-1 Ubuntu下彙編的命令
4.3 可重定位目標elf格式
首先先來了解一下ELF格式中都儲存了哪些檔案,如圖4-2所示,ELF中儲存了很多不同的節的資訊,每一個節中儲存了程式中對應的一些變數或者重定位等這些資訊,至於為什麼要儲存這些資訊,是因為程式在連結的時候會用到這些資訊。這些資訊的含義以及連結的作用我們會在下一章中進行介紹。

圖4-2 典型的ELF可重定位目標檔案
圖4-3 各個節節頭的資訊
根據readelf命令的結果,可以獲得ELF檔案的一些資訊。圖4-3中展示了ELF可重定位檔案中各個節節頭的資訊。偏移量這一欄中儲存了在hello.o這個二進位制檔案中,對應的節儲存在相對於起始地址偏移了這麼多的地方,也就是每一節存在了hello.o中得到哪一個位置上。
圖4-4中儲存了hello.o中的兩個可重定位節中儲存的具體資訊,分別是.rela.text和.tela.eh.frame。
.rela.text中儲存了程式碼的重定位資訊,也就是.text節中的資訊的重定位資訊。可以看到這裡面有.rodata,puts等很多程式碼的重定位資訊。我們就拿第一條的資訊來做分析。首先偏移量中儲存了這個重定位資訊在當前重定位節中的偏移量,也就是這個重定位資訊的儲存位置。第二個是資訊這個裡面儲存了兩個資訊,前面的2個位元組的資訊儲存了這個程式碼在彙編程式碼中被引用的時候的地址相對於所有彙編程式碼的偏移量,也就是這個程式碼具體在那個位置被呼叫了。後面4個位元組儲存了重定位型別,一個是絕對引用,另一個是相對引用。這也與後面一欄的型別相對應。後面的符號值和符號名稱就比較好理解了,儲存了程式碼段中具體符號的資訊。

圖4-4 可重定位節
最後還有一個符號表.symtab的資訊。這個節中存放了在程式中定義和引用的函式和全域性變數的資訊。我們在圖4-5中可以看到,有兩個比較明顯的變數,一個就是sleepsecs,另一個是main。這兩個分別是全域性變數和定義的函式。size這一欄中儲存了他們的大小,可以看到因為main是一個函式,所以內容相對較多,佔得空間比較大。後面的type儲存了變數型別,可以看到main中對應的型別就是FUNC,也就是函式。由於後面的一些符號還沒有進行連結這一步所以暫時沒有資訊。
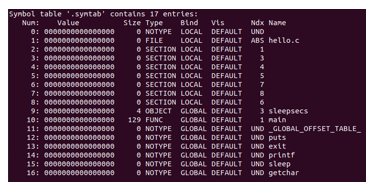
圖4-5 .symtab節
4.4 Hello.o的結果解析
用objdump命令進行反彙編過後,得到了如圖4-6中所示的程式碼:

圖4-6 hello.o的反彙編程式碼
對比第三章中的彙編程式碼可以發現,hello.o的反彙編程式多出來了上圖中框出來的三個部分,我們依次分析一下多了的這些資訊。
首先是紅框中的資訊。紅框中儲存了每一條指令的執行時地址,可以看到main函式的初始地址是0,然後依次向下增加。其實在後面的章節中會講到,這個地址只是一個虛擬地址,而不是程式真正執行的地址。
藍色的框中儲存了一些16進位制的程式碼。可以發現每一個紅框中的指令地址的變化量都是藍色框中一行的位元組數。這就可以確定,藍色框中儲存的是16進位制下的機器指令。我們可以看到地址為1和8的這兩行,都對應了mov操作,所以對應的16進位制的機器碼都是48,這也就說明mov的機器碼是48。
黃色框中的這段程式碼,我們看到底下多了一行資訊。這一行程式碼聲明瞭這個變數的具體型別。同時注意到偏移地址為26的這一指令,這個call操作也不是想第三章一樣直接call對應的函式名字了,而是一個具體的相對地址,能夠讓程式在跑的過程中,直接跳轉到的地方。
總體來說,hello.o檔案的反彙編程式碼中最主要的就是增加了地址這個概念,將程式碼中的一切資訊與地址聯絡起來。這樣做的目的是因為在程式執行的過程中,都是在進行地址操作,所以hello.o檔案可以說更接近了計算機可以執行的檔案。
4.5 本章小結
彙編器將彙編程式碼處理成機器可以看懂的機器碼,也就是二進位制程式碼。二進位制程式碼較彙編程式碼來說,雖然可讀性變得比較差,但是在執行效率方面有了非常大的提升,彙編程式碼雖然已經在原來的文字的基礎上進行了優化,但是還是存在著一些字元等不能夠直接處理的資料。但是二進位制程式碼中,已經將所有的指令、函式名字等量變成了相應的儲存地址,這樣機器就可以直接讀取這些程式碼並執行。所以總的來說hello.o已經非常接近一個機器可以執行的程式碼了。
第5章 連結
5.1 連結的概念與作用
5.1.1連結的概念
連結是通過連結器(ld)將各種程式碼和資料片斷收集並組合成一個單一檔案的過程。這個檔案可以被載入(複製)到記憶體並執行。
5.1.2連結的作用
因為有了連結這個概念的存在,所以我們的程式碼才回變得比較方便和簡潔,同時可移植性強,模組化程度比較高。因為連結的過程可以使我們將程式封裝成很多的模組,我們在變成的過程中只用寫主程式的部分,對於其他的部分我們有些可以直接呼叫模組,就像C中的printf一樣。
作為編譯的多後一步連結,就是處理當前程式呼叫其他模組的操作,將該呼叫的模組中的程式碼組合到相應的可執行檔案中去。
5.2 在Ubuntu下連結的命令
我們可以利用如下指令來對hello.o進行彙編:
linux> ld /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/5/crtbeginT.o -L/usr/lib/gcc/x86_64-linux-gnu/5 hello.o -lc -lgcc -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/gcc/x86_64-linux-gnu/5/crtend.o /usr/lib/x86_64-linux-gnu/crtn.o -o hello
從圖5-1中我們可以看到,利用上述命令編譯過後,我們得到了一個hello.o
檔案。

圖5-1 在Ubuntu下連結的命令
5.3 可執行目標檔案hello的格式

圖5-2 ELF各節資訊
圖5-2中儲存了可執行檔案hello中的各個節的資訊。可以看到hello檔案中的節的數目比hello.o中多了很多,說明在連結過後有很多檔案有添加了進來。下面列出每一節中各個資訊條目的含義:
名稱和大小這個條目中儲存了每一個節的名稱和這個節在重定位檔案種所佔的大小。
地址這個條目中,儲存了各個節在重定位檔案中的具體位置也就是地址。 偏移量這一欄中儲存的是這個節在程式裡面的地址的偏移量,也就是相對地址。
5.4 hello的虛擬地址空間
圖5-3中分別是edb顯示的hello檔案的資訊和5.3中輸出的ELF檔案的資訊。我們可以著重看一下紅框中的部分,這一部分中儲存的ELF頭資訊,也就是ELF檔案最開始存的資料。可以看到通過這兩種方式得到的資訊是完全相同的。再來說一下這個資訊的含義,我們看到右側的ELF頭下面有很多文字註釋,這其實就是ELF頭中儲存的資訊,即ELF整個檔案的基本資訊。

圖5-3 ELF檔案資訊對比
有一個比較奇怪的問題,就是在5.3中我們可以看到,在第17項開始的時候,地址就發生了一個比較大的變化。而edb中也沒有顯示出來這些節的資訊。這是因為這些節中儲存了共享庫中的資訊。在edb中如果想獲得這些資訊,需要單獨進行檢視,如圖5-4所示,就是從.dynamic節開始的資訊。
圖5-4 .dynamic節及其後面節的資訊
5.5 連結的重定位過程分析
首先先看一下main函式中有哪些不一樣的地方,如圖5-5所示,圖中上面的程式是hello.o檔案中main函式中的的一部分程式碼,下面的程式碼是hello檔案中對應部分的反彙編程式碼。可以發現,在連結之前,hello.o中的註釋僅僅是對main函式的一個便宜量,並且相應的彙編程式碼中lea後對於%rip的偏移量也是0,也就是說對於hello.o來說,我們並不能準確的瞭解到這段程式碼的含義。
再看連結之後的反彙編,可以看到反彙編之後,程式碼註釋中的內容直接變成了系統的IO庫中的函式,lea後面跟的偏移量也是正確的偏移量了。接下來的call指令也是一樣,在hello中準確的指明瞭具體呼叫的函式,而hello.o檔案中也只有一個main函式的偏移量。
可以看到,在連結的過程中,連結器會將我們連結的庫函式或者其他檔案在可執行檔案中準確的定位出來。

圖5-5 hello.o與hello的反彙編
可以看到,在hello.o的反彙編程式碼中,只有一個main函式,但是對於hello的反彙編程式碼來說,可以看到很多如_init樣子的函式。這些函式都是在連結的過程中,被載入到可執行檔案中的。
通過上面的對比可以看到,在連結的過程中,連結器會進行如下幾個過程:
將程式碼、符號、變數、函式等進行重定位,使這些元素在可執行檔案中可以有明確的虛擬記憶體地址。具體的執行方式就是用.o檔案中的重定位條目,這個條目告訴連結器應該如何修改這個引用的地址。
將呼叫的函式都載入到可執行檔案中,使其變成一個完整的檔案,在檔案中涉及到的任何符號或者函式等資訊在檔案中都有定義。
接下來分析一下連結器是如何進行重定位的。我們就對圖5-6中紅框中的語句的重定位進行分析。首先左側儲存了hello.o中程式碼節的重定位條目。紅框中的第一個資訊偏移量儲存的是這個符號的出現位置的偏移量,這裡是0x1d,對應於右側紅框中的我們可以看到是這個call函式的位置,這段指令的起始地址是0x1c,由於call函式的機器碼是e8佔了一個位元組,所以真正的符號出現的地址是0x1d,這兩個地址相同,說明這個重定位條目對應的是這個符號。

圖5-6 hello.o的重定位條目
第二個資訊的前兩個位元組儲存了這個符號在符號表中的偏移量,可以看到紅框中的資訊為0xc,對應在符號表中可以看到,puts在符號表中的偏移量是12,對應的十六進位制的值就是0xc,說明了被重定位的符號應該是puts。後面的型別儲存了是相對地址還是絕對地址。

圖5-7 hello.o中的符號表
總體來說,重定位的過程就是應用重定位檔案中儲存的資訊,在對應的符號表和彙編程式碼中將要重定位的符號或者函式的位置準確的放到可執行檔案中。
5.6 hello的執行流程
hello在執行的過程中一共要執行三個大的過程,分別是載入、執行和退出。載入過程的作用是將程式初始化,等初始化完成後,程式才能夠開始正常的執行。如圖5-7所示,由於hello程式只有一個main函式,所以在程式執行的時候主要都是在main函式中。又因為main函式中呼叫了很多其它的庫函式,所以可以看到,在main函式執行的過程中,會出現很多其他的函式。

圖5-7 hello的執行流程
5.7 Hello的動態連結分析
如圖5-8中所示,在執行函式dl_init的前後,地址0x600ff0中的值由0發生了變化。我們可以藉助圖5-2中的資訊,得到這個地址是.got節的開始,而got中是一個全域性函式表。這就說明,這個表中的資訊是在程式執行的過程中動態的連結進來的。也就是說,我們在之前重定位等一系列工作中,用到的地址都是虛擬地址,而我們需要的真實的地址資訊會在程式執行的過程中用動態連結的方式加入到程式中。當我們每次從PLT表中檢視資料的時候,會首先根據PLT表訪問GOT表,得到了真實地址之後再進行操作。

圖5-8 dl_init前後文件變化
分析hello程式的動態連結專案,通過edb除錯,分析在dl_init前後,這些專案的內容變化。要截圖示識說明。
5.8 本章小結
連結的過程,是將原來的只儲存了你寫的函式的程式碼與程式碼用所用的庫函式合併的一個過程。在這個過程中連結器會為每個符號、函式等資訊重新分配虛擬記憶體地址,方法就是用每個.o檔案中的重定位節與其它的節想配合,算出正確的地址。同時,將你會用到的庫函式載入(複製)到可執行檔案中。這些資訊一同構成了一個完整的計算機可以執行的檔案。連結讓我們的程式做到了很好的模組化,我們只需要寫我們的主要程式碼,對於讀入、IO等操作,可以直接與封裝的模組相連結,這樣大大的簡化了程式碼的書寫難度。
第6章 hello程序管理
6.1 程序的概念與作用
6.1.1程序的概念
程序的經典定義就是一個執行中的程式的例項。
6.1.2程序的作用
通過程序這個概念,我們在執行一個程式的過程中會得到一個假象,就好像我們的程式時系統中當前執行的唯一的程式一樣。我們的程式好像是獨佔的使用處理器和記憶體。處理器好像就是無間斷的一條接一條的執行我們程式中的指令。最後我們程式中的程式碼和資料好像是系統記憶體中唯一的物件。
6.2 簡述殼Shell-bash的作用與處理流程
shell是一個linux中提供的應用程式,他在作業系統中為使用者與核心之間提供了一個互動的介面,使用者可以通過這個介面訪問作業系統的核心服務。他的處理流程如下:
- 從介面中讀取使用者的輸入。
- 將輸入的內容轉化成對應的引數。
- 如果是核心命令就直接執行,否則就為其分配新的子程序繼續執行。
- 在執行期間,監控shell介面內是否有鍵盤輸入的命令,如果有需要作出相應的反應
6.3 Hello的fork程序建立過程
首先先來了解一下fork函式的機制。父程序通過呼叫fork函式建立一個新的子程序。新建立的子程序幾乎但不完全與子程序相同。在建立子程序的過程中,核心會將父程序的程式碼、資料段、堆、共享庫以及使用者棧這些資訊全部複製給子程序,同時子程序還可以讀父程序開啟的副本。唯一的不同就是他們的PID,這說明,雖然父程序與子程序所用到的資訊幾乎是完全相同的,但是這兩個程式卻是相互獨立的,各自有自己獨有的使用者棧等資訊。
fork函式雖然只會被呼叫一次,但是在返回的時候卻有兩次。在父程序中,fork函式返回子程序的PID;在子程序中,fork函式返回0。這就提供了一種用fork函式的返回值來區分父程序和子程序的方法。
同時fork在使用的過程中,有一個令人比較頭疼的問題,就是父程序和子程序是併發執行的所以我們不能夠準確的知道那個程序先執行或者先結束。這也就造成了每次執行的輸出結果可能是不同的,也是不可預測的。
圖6-1中展示了一個程式在呼叫了fork函式之後的行為。原程式中,在子程序中新型了++x操作,在父程序中進行了—x操作。通過程序圖我們可以看到,兩個程序的輸出分別為2和0,證實了我們上面說過的兩個程序是獨立的。
圖6-1 一個呼叫fork函式程式碼的程序圖
6.4 Hello的execve過程
execve函式的作用是在當前程序的上下文中載入並執行一個新的程式。與fork函式不同的是,fork函式建立了一個新的程序來執行另一個程式,而execve直接在當前的程序中刪除當前程序中現有的虛擬記憶體段,並穿件一組新的程式碼、資料、堆和使用者棧的段。將棧和堆初始化為0,程式碼段與資料段初始化為可執行檔案中的內容,最後將PC指向_start的地址。在CPU開始引用被對映的虛擬頁的時候,核心才會將需要用到的資料從磁碟中放入記憶體中。
圖6-2中展示了相應的系統映像。
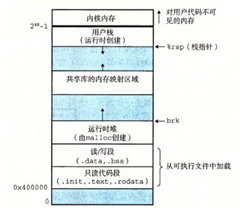
圖6-2 系統映像
6.5 Hello的程序執行
我們在之前的小節中已經提到過了,當前的CPU中並不是只有我們一個程式在執行,這只是一個假象,實際上有很多程序需要執行。要了解具體是怎樣進行的,首先先了解幾個概念。
上下文資訊:上下文就是核心重新啟動一個被搶佔的程序所需要的狀態,它由 通用暫存器、浮點暫存器、程式計數器、使用者棧、狀態暫存器、核心棧和各種內 核數據結構等物件的值構成。
程序時間片:一個程序執行它的控制流的一部分的每一時間段叫做時間片。
使用者模式與核心模式:處理器通常使用一個暫存器提供兩種模式的區分,該寄 存器描述了程序當前享有的特權,當沒有設定模式位時,程序就處於使用者模式中, 使用者模式的程序不允許執行特權指令,也不允許直接引用地址空間中核心區內的 程式碼和資料;設定模式位時,程序處於核心模式,該程序可以執行指令集中的任 何命令,並且可以訪問系統中的任何記憶體位置。
瞭解了一些基本概念之後,我們來分析一下hello程式中的具體執行情況。圖6-3中展示了hello的程式碼中會主動引起中斷的一個程式碼。

圖6-3 hello檔案的部分程式碼
這段程式碼中呼叫了sleep函式, 我們知道這個函式中用到的引數的值為2,所以這個sleep函式的作用就是當執行到這一句的時候,程式會產生一箇中斷,核心會將這個程序掛起,然後執行其它程式,當核心中的計時器到了2秒鐘的時候,會傳一個時間中斷給CPU,這時候CPU會將之前掛起的程序放到執行佇列中繼續執行。
從圖6-4中我們可以比較清晰的看出CPU是如何在程式建進行切換的。假設hello程序在sleep之前一直在順序執行。在執行到sleep函式的時候,切換到核心模式,將hello程序掛起,然後切換到使用者模式執行其它程序。當到了2秒之後,發生一箇中斷,切換到核心模式,繼續執行之前被掛起的程序。最後切換回使用者模式,繼續執行hello程序。

相關推薦
[CSAPP大作業] 程式人生-Hello's P2P
摘 要 本文主要介紹hello程式在linux下是如何從一個.c檔案一步步變成可執行檔案的。對於在執行的過程中可能會出現的一些比較重要的問題,例如虛擬記憶體,IO等操作進行探究。 關鍵詞:程式執行 CSAPP &
HITICS || 2018大作業 程式人生 Hello's P2P
摘 要 本文通過分析一個hello.c的完整的生命週期,從它開始被編譯,到被彙編、連結、在程序中執行,講解了Linux計算機系統執行一個程式的完整過程。 關鍵詞:作業系統,程序,程式的生命週期 目 錄 第1章 概述- 4 - 1.1 Hello簡介 -
「HITCS-2018大作業」程式人生——Hello's P2P
摘 要 Hello,是每個程式設計師都寫過的第一個程式,它是那麼簡單,以至於在程式設計師幾分鐘就學會並拋棄了它;它又是那麼偉大,因為它麻雀雖小,五臟俱全。學習計算機系統以後,再回頭看一看它,才恍然大悟,Hello才是一切的開始…… 本論文旨在通過講述Hello這個程式執行時計算機
HITICS大作業 程式人生-Hello’s P2P
程式人生-Hello’s P2P 摘 要 第1章 概述 1.1 Hello簡介 1.2 環境與工具 1.3 中間結果 1.4 本章小結 第2章 預處理 2.1 預處理的概念與作用 2.2
CSAPP大作業 2018 Hello's P2P
電腦科學與技術學院 2018年12月 摘 要 在電腦科學的發展中,大部分程式猿都是通過hello.c這一簡單的程式來接觸程式設計。然而正是因為hello的單純與淺顯沒有讓程式猿感到“至少40%”的神祕,它便遭遇冷落甚至無視。難道它真的如同它的表象,簡單得不像是實力派嗎?還真不是:僅僅這樣一個
HIT CSAPP 計算機系統大作業 《程式人生 - Hello’s P2P》
HIT CSAPP 計算機系統大作業 《程式人生 - Hello’s P2P》 計算機系統 大作業 題 目 程式人生-Hello’s P2P 專 業 軟體工程 學 號 1173710104 班 級 1737101 學 生 滕濤 指 導 教 師
CSAPP大作業 hello的一生
摘 要 本文在linux作業系統下對C語言程式hello.c的執行全過程進行了分析。分析了從c檔案轉化為可執行檔案過程中的預處理、編譯、彙編和連結階段,和可執行檔案執行過程中的程序管理、儲存空間管理和I/O管理的原理。 第1章 概述 1.1 Hello簡介 Hello的P2P
2018 HIT CSAPP 大作業:Hello的一生
目 錄 第1章 概述 - 4 - 1.1 Hello簡介 - 4 - 1.2 環境與工具 - 4 - 1.3 中間結果 - 4 - 1.4 本章小結 - 5 - 第2章 預處理 - 6 - 2.1 預處理的概念與作用 - 6 - 2.2在Ubuntu下預處理的命令 - 6 - 2.3 H
csapp 大作業 hello的一生
電腦科學與技術學院 2018年12月 摘 要 本文的目的是結合計算機系統,並使用gcc等工具,研究hello程式在ubuntu系統下的生命週期,從而深入理解課本知識,並進行融會貫通,以達到鞏固知識的目的。 關鍵詞:預處理;編譯;彙編;連結;程序;管理; 目 錄 第1章 概述 - 4 - 1.1 HELL
csapp大作業--hello的一生
摘 要 本文以hello程式切入點,研究一個程式從一個高階C語言程式開始,經過預處理、編譯、彙編、連結等到最後變成一個可執行檔案的生命週期,以此來了解系統如何通過硬體和系統軟體的交織、共同協作以達到執行應用程式的最終目的。將全書內容融會貫通,幫助深入理解計算機系統。 關鍵詞:計算機系統;
第一次作業:基於Orange's OS系統的進程模型分析與心得體會
直接 lld turn AR 信息保存 一次 tin 怎麽 ret 1一. 操作系統進程概念模型與進程控制塊概念淺析 1. 什麽是進程? 圖 1 - 1 (WIN10系統任務管理器對進程管理的圖形化界面) 計算機中的程序關於某數據集合上的一次運
哈工大CSAPP大作業
第1章 概述 1.1 Hello簡介 hello的原始碼hello.c檔案,要生成可執行檔案,首先要進行預處理,其次要進行編譯生成彙編程式碼,接著進行彙編處理生成目標檔案,目標檔案通過連結器形成一個可執行檔案,可執行檔案需要一個執行環境,它可以在linux下通過shell進行執行,與計算機其他經常檔案同步
程式人生 HELLO P2P
計算機系統 大作業 題 目 程式人生-Hello’s P2P 專 業 計算機系 學 號 1170301005 班 級 1703010 學 生 白鎮北 指 導 教 師 電腦科學與技術學院 2018年12月 摘 要 摘要是論文內容的高度概括,應具有獨立性和自含性,即
POJ 3686.The Windy's 最小費用最大流
mission event tac prev 思路 n) scrip display table The Windy‘s Time Limit: 5000MS Memory Limit: 65536K Total Submissions:
POJ2289 Jamie's Contact Groups —— 二分圖多重匹配/最大流 + 二分
u+ letter appears i++ ive desc target ups tro 題目鏈接:https://vjudge.net/problem/POJ-2289 Jamie‘s Contact Groups Time Limit: 7000MS
POJ 3422 Kaka's Matrix Travels | 最小費用最大流
ont algo pac scanf 題解 pop dfs cpp clu 題目: 給個n*n的帶正權矩陣,k次從(1,1)走到(n,n),每個格子的權值只能獲得一次,每次只能向右或下走 問獲得最大權值 題解: 求最大權值可以把權值變成負的求最小 然後考慮怎麽約束每個格子
[poj] 3422 Kaka's Matrix Travels || 最小費用最大流
logs 得到 我們 最小費用最大流 str next include ont 價值 原題 給一個N*N的方陣,從[1,1]到[n,n]走K次,走過每個方格加上上面的數,然後這個格上面的數變為0。求可取得的最大的值。 要求最大值,所以把邊權全為負跑最小費用即可。因為只有第一
統計一行文字的單詞個數 (15 分) 本題目要求編寫程式統計一行字元中單詞的個數。所謂“單詞”是指連續不含空格的字串,各單詞之間用空格分隔,空格數可以是多個。 輸入格式: 輸入給出一行字元。 輸出格式: 在一行中輸出單詞個數。 輸入樣例: Let's go to room 209. 輸出樣例
MD,一開始就想著怎麼 用空格和結尾前判斷字母 來計算寫的頭的爆了, 反過來判斷空格後面是否有 =‘ ’就尼瑪容易多了 #include<stdio.h> #include<stdlib.h> #include<string.h> int
HDU2852 KiKi's K-Number (權值線段樹求第k大)
題意:三種操作,0 e 表示插入一個數字e,1 e 表示刪除一個數字e,2 e k 表示查詢比e大的第k個數,刪除和查詢均可能沒有 目標。 思路:建一棵權值線段樹,維護每個數字區間中數字的數量。 查詢時,先查出1到e的數字數量n,然後查詢第k+n大。 #include<cs
HIT CSAPP 2018 計算機系統大作業
摘 要 本文通過合理運用這個學期在計算機系統課程上學習的知識,分析研究hello程式在Linux下從程式碼到程式,從出生到終止的過程,通過熟練使用各種工具,學習Linux框架下整個程式的宣告週期,加深對課本知識的印象。 關鍵字