
深入分析 Linux 核心連結串列
一、連結串列資料結構簡介
連結串列是一種常用的組織有序資料的資料結構,它通過指標將一系列資料節點連線成一條資料鏈,是線性表的一種重要實現方式。相對於陣列,連結串列具有更好的動態性,建立連結串列時無需預先知道資料總量,可以隨機分配空間,可以高效地在連結串列中的任意位置實時插入或刪除資料。連結串列的開銷主要是訪問的順序性和組織鏈的空間損失。
通常連結串列資料結構至少應包含兩個域:資料域和指標域,資料域用於儲存資料,指標域用於建立與下一個節點的聯絡。按照指標域的組織以及各個節點之間的聯絡形式,連結串列又可以分為單鏈表、雙鏈表、迴圈連結串列等多種型別,下面分別給出這幾類常見連結串列型別的示意圖:
1.單鏈表

圖1 單鏈表
單鏈表是最簡單的一類連結串列,它的特點是僅有一個指標域指向後繼節點(next),因此,對單鏈表的遍歷只能從頭至尾(通常是NULL空指標)順序進行。
2.雙鏈表
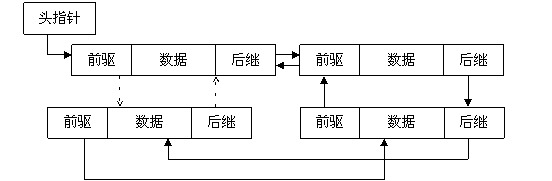
圖2 雙鏈表
通過設計前驅和後繼兩個指標域,雙鏈表可以從兩個方向遍歷,這是它區別於單鏈表的地方。如果打亂前驅、後繼的依賴關係,就可以構成"二叉樹";如果再讓首節點的前驅指向連結串列尾節點、尾節點的後繼指向首節點(如圖2中虛線部分),就構成了迴圈連結串列;如果設計更多的指標域,就可以構成各種複雜的樹狀資料結構。
3.迴圈連結串列
迴圈連結串列的特點是尾節點的後繼指向首節點。前面已經給出了雙迴圈連結串列的示意圖,它的特點是從任意一個節點出發,沿兩個方向的任何一個,都能找到連結串列中的任意一個數據。如果去掉前驅指標,就是單迴圈連結串列。
在Linux核心中使用了大量的連結串列結構來組織資料,包括裝置列表以及各種功能模組中的資料組織。這些連結串列大多采用在[include/linux/list.h]實現的一個相當精彩的連結串列資料結構。本文的後繼部分就將通過示例詳細介紹這一資料結構的組織和使用。
二、Linux 2.6核心連結串列資料結構的實現
儘管這裡使用2.6核心作為講解的基礎,但實際上2.4核心中的連結串列結構和2.6並沒有什麼區別。不同之處在於2.6擴充了兩種連結串列資料結構:連結串列的讀拷貝更新(rcu)和HASH連結串列(hlist)。這兩種擴充套件都是基於最基本的list結構,因此,本文主要介紹基本連結串列結構,然後再簡要介紹一下rcu和hlist。
連結串列資料結構的定義很簡單(節選自[include/linux/list.h],以下所有程式碼,除非加以說明,其餘均取自該檔案):
struct list_head {
struct list_head *next, *prev;
};
list_head結構包含兩個指向list_head結構的指標prev和next,由此可見,核心的連結串列具備雙鏈表功能,實際上,通常它都組織成雙迴圈連結串列。
和第一節介紹的雙鏈表結構模型不同,這裡的list_head沒有資料域。在Linux核心連結串列中,不是在連結串列結構中包含資料,而是在資料結構中包含連結串列節點。
在資料結構課本中,連結串列的經典定義方式通常是這樣的(以單鏈表為例):
struct list_node {
struct list_node *next;
ElemType data;
};
因為ElemType的緣故,對每一種資料項型別都需要定義各自的連結串列結構。有經驗的C++程式設計師應該知道,標準模板庫中的採用的是C++ Template,利用模板抽象出和資料項型別無關的連結串列操作介面。
在Linux核心連結串列中,需要用連結串列組織起來的資料通常會包含一個struct list_head成員,例如在[include/linux/netfilter.h]中定義了一個nf_sockopt_ops結構來描述Netfilter為某一協議族準備的getsockopt/setsockopt介面,其中就有一個(struct list_head list)成員,各個協議族的nf_sockopt_ops結構都通過這個list成員組織在一個連結串列中,表頭是定義在[net/core/netfilter.c]中的nf_sockopts(struct list_head)。從下圖中我們可以看到,這種通用的連結串列結構避免了為每個資料項型別定義自己的連結串列的麻煩。Linux的簡捷實用、不求完美和標準的風格,在這裡體現得相當充分。
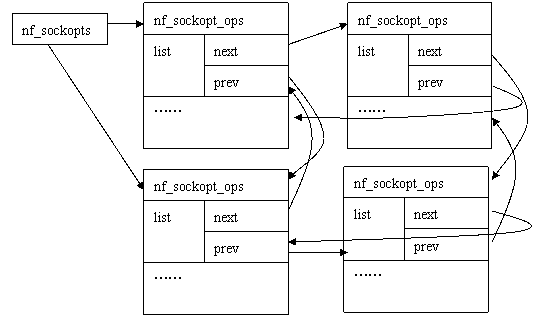
圖3 nf_sockopts連結串列示意圖
三、連結串列操作介面
1. 宣告和初始化
實際上Linux只定義了連結串列節點,並沒有專門定義連結串列頭,那麼一個連結串列結構是如何建立起來的呢?讓我們來看看LIST_HEAD()這個巨集:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name)
當我們用LIST_HEAD(nf_sockopts)宣告一個名為nf_sockopts的連結串列頭時,它的next、prev指標都初始化為指向自己,這樣,我們就有了一個空連結串列,因為Linux用頭指標的next是否指向自己來判斷連結串列是否為空:
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
除了用LIST_HEAD()巨集在宣告的時候初始化一個連結串列以外,Linux還提供了一個INIT_LIST_HEAD巨集用於執行時初始化連結串列:
#define INIT_LIST_HEAD(ptr) do { \
(ptr)->next = (ptr); (ptr)->prev = (ptr); \
} while (0)
我們用INIT_LIST_HEAD(&nf_sockopts)來使用它。
2. 插入/刪除/合併
a) 插入
對連結串列的插入操作有兩種:在表頭插入和在表尾插入。Linux為此提供了兩個介面:
static inline void list_add(struct list_head *new, struct list_head *head);
static inline void list_add_tail(struct list_head *new, struct list_head *head);
因為Linux連結串列是迴圈表,且表頭的next、prev分別指向連結串列中的第一個和最末一個節點,所以,list_add和list_add_tail的區別並不大,實際上,Linux分別用
__list_add(new, head, head->next);
__list_add(new, head->prev, head);
來實現兩個介面,可見,在表頭插入是插入在head之後,而在表尾插入是插入在head->prev之後。
假設有一個新nf_sockopt_ops結構變數new_sockopt需要新增到nf_sockopts連結串列頭,我們應當這樣操作:
list_add(&new_sockopt.list, &nf_sockopts);
從這裡我們看出,nf_sockopts連結串列中記錄的並不是new_sockopt的地址,而是其中的list元素的地址。如何通過連結串列訪問到new_sockopt呢?下面會有詳細介紹。
b) 刪除
static inline void list_del(struct list_head *entry);
當我們需要刪除nf_sockopts連結串列中新增的new_sockopt項時,我們這麼操作:
list_del(&new_sockopt.list);
被剔除下來的new_sockopt.list,prev、next指標分別被設為LIST_POSITION2和LIST_POSITION1兩個特殊值,這樣設定是為了保證不在連結串列中的節點項不可訪問–對LIST_POSITION1和LIST_POSITION2的訪問都將引起頁故障。與之相對應,list_del_init()函式將節點從連結串列中解下來之後,呼叫LIST_INIT_HEAD()將節點置為空鏈狀態。
c) 搬移
Linux提供了將原本屬於一個連結串列的節點移動到另一個連結串列的操作,並根據插入到新連結串列的位置分為兩類:
static inline void list_move(struct list_head *list, struct list_head *head);
static inline void list_move_tail(struct list_head *list, struct list_head *head);
例如list_move(&new_sockopt.list,&nf_sockopts)會把new_sockopt從它所在的連結串列上刪除,並將其再鏈入nf_sockopts的表頭。
d) 合併
除了針對節點的插入、刪除操作,Linux連結串列還提供了整個連結串列的插入功能:
static inline void list_splice(struct list_head *list, struct list_head *head);
假設當前有兩個連結串列,表頭分別是list1和list2(都是struct list_head變數),當呼叫list_splice(&list1,&list2)時,只要list1非空,list1連結串列的內容將被掛接在list2連結串列上,位於list2和list2.next(原list2表的第一個節點)之間。新list2連結串列將以原list1表的第一個節點為首節點,而尾節點不變。如圖(虛箭頭為next指標):
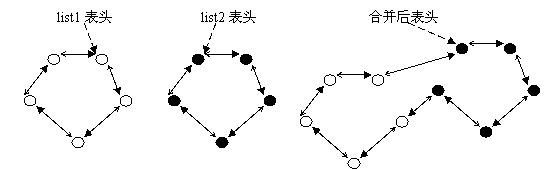
圖4 連結串列合併list_splice(&list1,&list2)
當list1被掛接到list2之後,作為原表頭指標的list1的next、prev仍然指向原來的節點,為了避免引起混亂,Linux提供了一個list_splice_init()函式:
static inline void list_splice_init(struct list_head *list, struct list_head *head);
該函式在將list合併到head連結串列的基礎上,呼叫INIT_LIST_HEAD(list)將list設定為空鏈。
3. 遍歷
遍歷是連結串列最經常的操作之一,為了方便核心應用遍歷連結串列,Linux連結串列將遍歷操作抽象成幾個巨集。在介紹遍歷巨集之前,我們先看看如何從連結串列中訪問到我們真正需要的資料項。
a) 由連結串列節點到資料項變數
我們知道,Linux連結串列中僅儲存了資料項結構中list_head成員變數的地址,那麼我們如何通過這個list_head成員訪問到作為它的所有者的節點資料呢?Linux為此提供了一個list_entry(ptr,type,member)巨集,其中ptr是指向該資料中list_head成員的指標,也就是儲存在連結串列中的地址值,type是資料項的型別,member則是資料項型別定義中list_head成員的變數名,例如,我們要訪問nf_sockopts連結串列中首個nf_sockopt_ops變數,則如此呼叫:
list_entry(nf_sockopts->next, struct nf_sockopt_ops, list);
這裡"list"正是nf_sockopt_ops結構中定義的用於連結串列操作的節點成員變數名。
list_entry的使用相當簡單,相比之下,它的實現則有一些難懂:
#define list_entry(ptr, type, member) container_of(ptr, type, member)
container_of巨集定義在[include/linux/kernel.h]中:
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
offsetof巨集定義在[include/linux/stddef.h]中:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
size_t最終定義為unsigned int(i386)。
這裡使用的是一個利用編譯器技術的小技巧,即先求得結構成員在與結構中的偏移量,然後根據成員變數的地址反過來得出屬主結構變數的地址。
container_of()和offsetof()並不僅用於連結串列操作,這裡最有趣的地方是((type *)0)->member,它將0地址強制"轉換"為type結構的指標,再訪問到type結構中的member成員。在container_of巨集中,它用來給typeof()提供引數(typeof()是gcc的擴充套件,和sizeof()類似),以獲得member成員的資料型別;在offsetof()中,這個member成員的地址實際上就是type資料結構中member成員相對於結構變數的偏移量。
如果這麼說還不好理解的話,不妨看看下面這張圖:
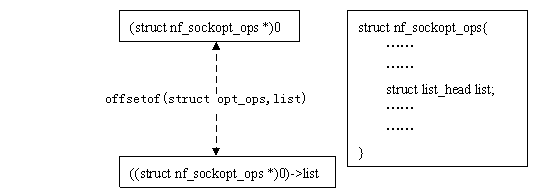
圖5 offsetof()巨集的原理
對於給定一個結構,offsetof(type,member)是一個常量,list_entry()正是利用這個不變的偏移量來求得連結串列資料項的變數地址。
b) 遍歷巨集
在[net/core/netfilter.c]的nf_register_sockopt()函式中有這麼一段話:
……
struct list_head *i;
……
list_for_each(i, &nf_sockopts) {
struct nf_sockopt_ops *ops = (struct nf_sockopt_ops *)i;
……
}
……
函式首先定義一個(struct list_head *)指標變數i,然後呼叫list_for_each(i,&nf_sockopts)進行遍歷。在[include/linux/list.h]中,list_for_each()巨集是這麼定義的:
#define list_for_each(pos, head) \
for (pos = (head)->next, prefetch(pos->next); pos != (head); \
pos = pos->next, prefetch(pos->next))
它實際上是一個for迴圈,利用傳入的pos作為迴圈變數,從表頭head開始,逐項向後(next方向)移動pos,直至又回到head(prefetch()可以不考慮,用於預取以提高遍歷速度)。
那麼在nf_register_sockopt()中實際上就是遍歷nf_sockopts連結串列。為什麼能直接將獲得的list_head成員變數地址當成struct nf_sockopt_ops資料項變數的地址呢?我們注意到在struct nf_sockopt_ops結構中,list是其中的第一項成員,因此,它的地址也就是結構變數的地址。更規範的獲得資料變數地址的用法應該是:
struct nf_sockopt_ops *ops = list_entry(i, struct nf_sockopt_ops, list);
大多數情況下,遍歷連結串列的時候都需要獲得連結串列節點資料項,也就是說list_for_each()和list_entry()總是同時使用。對此Linux給出了一個list_for_each_entry()巨集:
#define list_for_each_entry(pos, head, member) ……
與list_for_each()不同,這裡的pos是資料項結構指標型別,而不是(struct list_head *)。nf_register_sockopt()函式可以利用這個巨集而設計得更簡單:
struct nf_sockopt_ops *ops;
list_for_each_entry(ops,&nf_sockopts,list){
……
}
……
某些應用需要反向遍歷連結串列,Linux提供了list_for_each_prev()和list_for_each_entry_reverse()來完成這一操作,使用方法和上面介紹的list_for_each()、list_for_each_entry()完全相同。
如果遍歷不是從連結串列頭開始,而是從已知的某個節點pos開始,則可以使用list_for_each_entry_continue(pos,head,member)。有時還會出現這種需求,即經過一系列計算後,如果pos有值,則從pos開始遍歷,如果沒有,則從連結串列頭開始,為此,Linux專門提供了一個list_prepare_entry(pos,head,member)巨集,將它的返回值作為list_for_each_entry_continue()的pos引數,就可以滿足這一要求。
4. 安全性考慮
在併發執行的環境下,連結串列操作通常都應該考慮同步安全性問題,為了方便,Linux將這一操作留給應用自己處理。Linux連結串列自己考慮的安全性主要有兩個方面:
a) list_empty()判斷
基本的list_empty()僅以頭指標的next是否指向自己來判斷連結串列是否為空,Linux連結串列另行提供了一個list_empty_careful()巨集,它同時判斷頭指標的next和prev,僅當兩者都指向自己時才返回真。這主要是為了應付另一個cpu正在處理同一個連結串列而造成next、prev不一致的情況。但程式碼註釋也承認,這一安全保障能力有限:除非其他cpu的連結串列操作只有list_del_init(),否則仍然不能保證安全,也就是說,還是需要加鎖保護。
b) 遍歷時節點刪除
前面介紹了用於連結串列遍歷的幾個巨集,它們都是通過移動pos指標來達到遍歷的目的。但如果遍歷的操作中包含刪除pos指標所指向的節點,pos指標的移動就會被中斷,因為list_del(pos)將把pos的next、prev置成LIST_POSITION2和LIST_POSITION1的特殊值。
當然,呼叫者完全可以自己快取next指標使遍歷操作能夠連貫起來,但為了程式設計的一致性,Linux連結串列仍然提供了兩個對應於基本遍歷操作的"_safe"介面:list_for_each_safe(pos, n, head)、list_for_each_entry_safe(pos, n, head, member),它們要求呼叫者另外提供一個與pos同類型的指標n,在for迴圈中暫存pos下一個節點的地址,避免因pos節點被釋放而造成的斷鏈。
四、 擴充套件
1. hlist
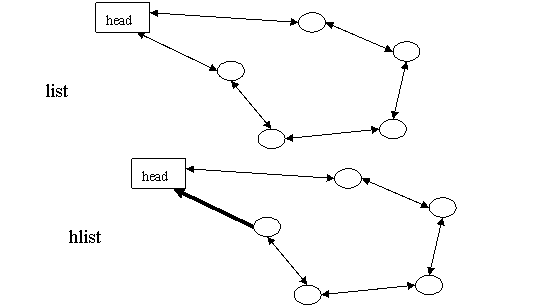
圖6 list和hlist
精益求精的Linux連結串列設計者(因為list.h沒有署名,所以很可能就是Linus Torvalds)認為雙頭(next、prev)的雙鏈表對於HASH表來說"過於浪費",因而另行設計了一套用於HASH表應用的hlist資料結構–單指標表頭雙迴圈連結串列,從上圖可以看出,hlist的表頭僅有一個指向首節點的指標,而沒有指向尾節點的指標,這樣在可能是海量的HASH表中儲存的表頭就能減少一半的空間消耗。
因為表頭和節點的資料結構不同,插入操作如果發生在表頭和首節點之間,以往的方法就行不通了:表頭的first指標必須修改指向新插入的節點,卻不能使用類似list_add()這樣統一的描述。為此,hlist節點的prev不再是指向前一個節點的指標,而是指向前一個節點(可能是表頭)中的next(對於表頭則是first)指標(struct list_head **pprev),從而在表頭插入的操作可以通過一致的"*(node->pprev)"訪問和修改前驅節點的next(或first)指標。
2. read-copy update
在Linux連結串列功能介面中還有一系列以"_rcu"結尾的巨集,與以上介紹的很多函式一一對應。RCU(Read-Copy Update)是2.5/2.6核心中引入的新技術,它通過延遲寫操作來提高同步效能。
我們知道,系統中資料讀取操作遠多於寫操作,而rwlock機制在smp環境下隨著處理機增多效能會迅速下降(見參考資料4)。針對這一應用背景,IBM Linux技術中心的Paul E. McKenney提出了"讀拷貝更新"的技術,並將其應用於Linux核心中。RCU技術的核心是寫操作分為寫-更新兩步,允許讀操作在任何時候無阻訪問,當系統有寫操作時,更新動作一直延遲到對該資料的所有讀操作完成為止。Linux連結串列中的RCU功能只是Linux RCU的很小一部分,對於RCU的實現分析已超出了本文所及,有興趣的讀者可以自行參閱本文的參考資料;而對RCU連結串列的使用和基本連結串列的使用方法基本相同。
第一時間獲取嵌入式乾貨,請加公眾號baiwenkeji
有問題歡迎加WEI信討論交流:13266630429,驗證:CSDN