
移植Linux核心連結串列
Linux核心原始碼中的連結串列是一個雙向迴圈連結串列,該連結串列的設計具有優秀的封裝性和可擴充套件性。本文將從2.6.39版本核心的核心連結串列移植到Windows平臺的visual studio2010環境中。連結串列的原始碼位於核心原始碼的include/linux/list.h中。移植的步驟如下:
(1)去除依賴的標頭檔案
list.h依賴的標頭檔案如下:
#include <linux/types.h>
#include <linux/stddef.h>
#include <linux/poison.h>
#include <linux/prefetch.h> 依次進入這4個頭檔案,提取檔案內的有被list使用到的程式碼:
//types.h:
struct list_head {
struct list_head *next, *prev;
};
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};//stddef.h:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) offsetof巨集可參考offsetof和container_of一般它和container_of巨集配合使用。核心的container_of原型如下:
#define container_of(ptr, type, member) ({ \
const typeof(((type*)0)->member)* __mptr = (ptr); \
(type*)((char*)__mptr - offsetof(type, member)); })因為typeof是GNU C編譯器的關鍵字,微軟編譯器並不支援,所以不能使用該關鍵字,即沒有型別檢查的功能:
#define m_container(ptr, type, member) ((type *)( (char *)ptr - offsetof(type,member)))//poison.h:
#define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
#define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)list的刪除節點函式list_del()的實現中最後將被刪除的節點的next和pre指標分別為LIST_POISON1和LIST_POISON2,所以可以將這兩個巨集修改為:
#define LIST_POISON1 ((void *) 0x00)
#define LIST_POISON2 ((void *) 0x00)//prefetch.h:
#define prefetch(x) __builtin_prefetch(x)__builtin_prefetch()是GNU C編譯器特有的內建函式,意義在於程式碼優化。因為我們要將list.h移植到使用微軟編譯器的平臺,所以不可使用__builtin_prefetch()函式,可修改為:
#define prefetch(x) ((void*)(x)) (2)將list.h中的所有函式的宣告屬性“static inline”修改為“static”,因為“static inline”同時修飾一個函式只在GNU C編譯器宣告。
連結串列的一般設計是:
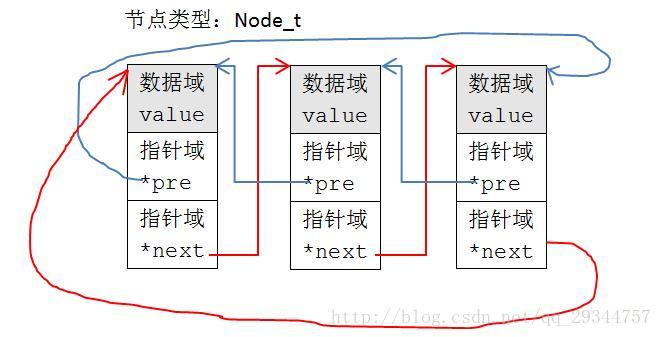
從圖可見,節點的指標域指向的是下一個節點(或上一個節點)變數開始的地址,指標的型別為Node_t*。顯然隨著節點型別的不同,指標域的指標型別也要隨之改變。Linux核心為了設計成具有封裝性和擴充套件性的連結串列,將節點指標域中的指標的指向做了改變:
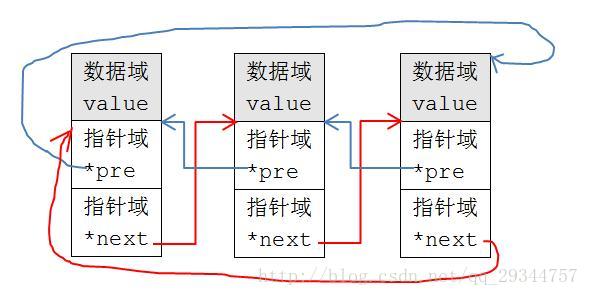
作為雙向迴圈連結串列的節點,每一個型別節點的指標域都具有兩個指標,這是不變的,核心將指標的指向改為下一個節點(或上一個節點)變數的指標域開始地方,這樣每一個節點的定義只需要包含核心定義的指標域型別即可使用核心連結串列。連結串列的操作(如增加/刪除)是針對指標域型別的,所以這些函式能適用於任何使用核心連結串列組織的資料。
注意,這樣一來,我們要訪問使用核心連結串列的節點的資料域時,不可以直接通過指標域的的指向的地址來訪問,中間需要一個轉換過程,即使用核心的container_of巨集,container_of可以實現通過結構體的某個成員變數的地址獲取結構體變數的起始地址,我們通過該地址就可以獲取給結構體的任意成員了,這正是Linux核心設計的巧妙之處。
核心連結串列的常用函式/巨集有:
1.INIT_LIST_HEAD():初始化連結串列(頭)
2.list_add():在;連結串列頭插入節點
3.list_add_tail():在連結串列尾部插入節點
4.list_del():刪除節點
5.list_entry():通過節點的指標域獲取資料節點的起始地址
6.list_for_each():遍歷連結串列(不可和list_del()配合使用)
7.list_for_each_safe():安全的遍歷連結串列(可和list_del()配合使用))編寫測試函式(1):
void list_test1()
{
struct Node_t
{
struct list_head head;
char value;
};
int i;
struct Node_t l = {0}; //定義頭節點
struct list_head* p = NULL;
struct list_head* n;
//初始化連結串列(頭節點)
INIT_LIST_HEAD(&l.head);
for (i = 0; i < 6; ++i)
{
struct Node_t* n = (struct Node_t* )malloc(sizeof(struct Node_t));
n->value = i;
//將新節點尾插到連結串列中
list_add_tail(&n->head, &l.head);
}
//遍歷連結串列
list_for_each(p, &l.head)
{
//因為Node_t的第一個成員的型別就是struct list_head型別,所以可以強制型別轉換
printf("%-2d", ((struct Node_t*)p)->value);
}
printf("\n");
list_for_each(p, &l.head)
{
//刪除第一個value為2的節點
if (((struct Node_t*)p)->value == 2)
{
list_del(p); //執行list_del()後p的指標域都指向NULL
free((struct Node_t*)p);
break;
}
}
list_for_each(p, &l.head)
{
printf("%-2d", list_entry(p, struct Node_t, head)->value);
}
printf("\n");
//不可以通過list_for_each遍歷來逐一銷燬動態分配的節點,因為銷燬完第一個節點後p的指標域都置為0
//而list_for_each巨集是通過p來遍歷下一個節點的
//list_for_each(p, &l.head)
//{
// list_del(p);
//}
//可以使用list_for_each_safe遍歷來逐一銷燬動態分配的節點,因為該巨集使用了n來備份p指標
list_for_each_safe(p, n, &l.head)
{
list_del(p);
free((struct Node_t*)p); //銷燬節點
//或者free(list_entry(p, struct Node_t, head)); //銷燬節點
}
}測試函式(2):
void list_test2()
{
struct Node_t
{
char value;
struct list_head head;
};
struct Node_t l = {0};
struct list_head* p;
struct list_head* n;
int i;
//初始化連結串列(頭節點)
INIT_LIST_HEAD(&l.head);
for (i = 0; i < 6; ++i)
{
struct Node_t* n = (struct Node_t* )malloc(sizeof(struct Node_t));
n->value = i;
//將新節點以頭插的方式插入連結串列中
list_add(&n->head, &l.head);
}
//遍歷列印
list_for_each(p, &l.head)
{
printf("%-2d", list_entry(p, struct Node_t, head)->value);
}
printf("\n");
//遍歷連結串列
list_for_each(p, &l.head)
{
//因為Node_t的第一個成員不是list_head型別成員,所以需要list_entry巨集獲取Node_t型別物件的
//起始地址,進而訪問其value成員
struct Node_t *n = list_entry(p, struct Node_t, head);
if (n->value == 2)
{
list_del(p);
free(n);
break;
}
}
list_for_each(p, &l.head)
{
printf("%-2d", list_entry(p, struct Node_t, head)->value);
}
printf("\n");
list_for_each_safe(p, n, &l.head)
{
list_del(p);
free(list_entry(p, struct Node_t, head)); //銷燬節點
}
}使用核心連結串列需要注意:
a. 不可以使用list_for_each遍歷連結串列節點並銷燬節點,原因見程式碼註釋;
b. 訪問節點的資料域時,如果節點型別的第一個成員不是list_head型別的變數時需要使用list_entry()獲取節點型別變數的起始地址,進而訪問節點的資料域,否則可以通過強制型別轉換(考慮兩個結構體變數的記憶體佈局)。
相關推薦
移植Linux核心連結串列
Linux核心原始碼中的連結串列是一個雙向迴圈連結串列,該連結串列的設計具有優秀的封裝性和可擴充套件性。本文將從2.6.39版本核心的核心連結串列移植到Windows平臺的visual studio2010環境中。連結串列的原始碼位於核心原始碼的includ
linux核心連結串列list_entry()函式的分析
這個函式可以通過list的指標域推算出它的節點所指向的值,具體程式碼實現如下: /** * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type:
LINUX核心連結串列筆記
[email protected]:~/CMburn-master$ find /usr/ -name list.h -print /usr/src/linux-headers-4.15.0-24-generic/include/config/system/blacklist/hash
資料結構 筆記:Linux核心連結串列剖析
Linux核心連結串列的位置及依賴 -位置 ·{linux-2.6.39}\\include\linux\list.h -依賴 #include <linux/types.h> #include <linux/stddef.h> #includ
7.Linux核心設計與實現 P69---深入分析 Linux 核心連結串列(轉)
連結串列是一種常用的組織有序資料的資料結構,它通過指標將一系列資料節點連線成一條資料鏈,是線性表的一種重要實現方式。相對於陣列,連結串列具有更好的動態性,建立連結串列時無需預先知道資料總量,可以隨機分配空間,可以高效地在連結串列中的任意位置實時插入或刪除資料。連結串列的開銷主要是訪問的順序性和組織鏈的空間
Linux核心連結串列深度分析
連結串列簡介: 連結串列是一種常用的資料結構,它通過指標將一系列資料節點連線成一條資料鏈。相對於陣列,連結串列具有更好的動態性,建立連結串列時無需預先知道資料總量,可以隨機分配空間,可以高效地在連結串列中的任意位置實時插入或者刪除資料。連結串列的開銷主要是訪問的順序性和組織
深入分析 Linux 核心連結串列
一、連結串列資料結構簡介 連結串列是一種常用的組織有序資料的資料結構,它通過指標將一系列資料節點連線成一條資料鏈,是線性表的一種重要實現方式。相對於陣列,連結串列具有更好的動態性,建立連結串列時無需預先知道資料總量,可以隨機分配空間,可以高效地在連結串列中的任意位置實時插入或刪除資料。連
重新審視linux核心連結串列
list_for_each_entry_safe 、 list_for_each_entry list_for_each_safe 、 list_for_each 在函式名上的差別就是前面多一個safe,大概就是安全遍歷的意思,為什麼會多出這麼一個函式,在什麼時候用合
linux核心連結串列的實現和使用和詳解
首先,核心連結串列的標頭檔案,在linux核心的 /include/linux 下的 List.h ,把List.h 複製出來,黏貼到 工程下,就可以直接用核心連結串列的一些巨集和函式。 以下介紹核心連結串列的一些巨集和函式,已經他的實現方式和使用方法。 (1)什麼是核心
今天看了Linux 核心連結串列
/* Insert a new entry between two known consecutive entries */ static inline void __list_add(struct list_head *fnew,struct list_head *pr
linux核心連結串列之例項一
基本知識可以看這個網址 這個例子包括簡單的增、刪、遍歷#include <linux/kernel.h> #include <linux/module.h> #include <linux/init.h> #include <l
(補充實驗方法) linux核心連結串列之例項 這個例子包括簡單的增、刪、遍歷
#include <linux/kernel.h>#include <linux/module.h>#include <linux/init.h>#include <linux/slab.h>#include <linux/list.h>MODUL
嵌入式Linux開發——(十四)移植Linux核心
基於Linux2.6.22.6 1、相關常識 ①VERSION = 2 PATCHLEVEL=6 主版本號,穩定版本用偶數來表示,每隔2~~3年出現一個穩定版 &nbs
移植linux核心到s3c6410(kernel 列印:Uncompressing Linux ... done , booting the kernel.後無響應問題的解決。)
轉載地址: https://blog.csdn.net/roadtoforest/article/details/6652280 U-boot網口問題解決後,uImage和ramdisk終於可以上傳到單板上去驗證了。指令碼為: MINI6410 # setenv serverip
核心連結串列實現任意兩個節點交換位置
#include <stdio.h> #include "list.h" //list.h這個檔案需要你自己打造,可以拷貝核心原始碼,也可以參考我的博文 struct data_info { int data; struct list_head list; }; in
資料結構之核心連結串列
核心連結串列設計的非常巧妙,但也不是什麼難理解的內容,關於核心連結串列的介紹網上有很多,這裡就不贅述了,來個使用的例子吧。 list.h #ifndef HS_KERNEL_LIST_H #define HS_KERNEL_LIST_H #define offsetof(TYPE, MEM
玩轉C線性表和單向連結串列之Linux雙向連結串列優化
前言: 這次介紹基本資料結構的線性表和連結串列,並用C語言進行編寫;建議最開始學資料結構時,用C語言;像棧和佇列都可以用這兩種資料結構來實現。 一、線性表基本介紹 1 概念: 線性表也就是關係戶中最簡單的一種關係,一對一。
核心連結串列list.h檔案剖析
核心連結串列list.h檔案剖析 一、核心連結串列的結構【雙向迴圈連結串列】 核心連結串列的好主要體現為兩點,1是可擴充套件性,2是封裝。可以將核心連結串列複用到使用者態程式設計中,以後在使用者態下程式設計就不需要寫一些關於連結串列的程式碼了,直接將核心中list
linux核心中串列埠驅動註冊過程(tty驅動)
原文轉自:http://m.blog.csdn.net/blog/lushengchu2003/9368031 最近閒來無事情做,想到以前專案中遇到串列埠硬體流控制的問題,藍芽串列埠控制返回錯誤,上層讀寫串列埠buffer溢位的問題等,也折騰了一陣子,雖然 最終證明與串列埠驅動無關,但是排查問題
手把手教你移植linux核心---------OK6410(一)
配置資訊: 移植核心:linux-3.3.5 可以從 http://www.kernel.org/ 下載純正的版本 編譯環境:vmware下ubuntu11.04 交叉編譯版本:4.3.2 準備工作: 一塊OK6410開發板,交叉網線,串列埠線