
Ridge和lasso迴歸實現的一個小案例
阿新 • • 發佈:2019-01-07
來自於鄒博機器學習第七期第九課中的內容:簡單介紹就是一個產品的銷量sales與TV、radio、newspaper三個投入量之間的關係。
直接上程式碼:
import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import pandas as pd from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.linear_model import Lasso, Ridge
其中train_test_split
if __name__ == "__main__": # pandas讀入 data = pd.read_csv('E:\\code\\Advertising.csv') # print(data) x = data[['TV', 'Radio', 'Newspaper']] # x = data[['TV', 'Radio']] y = data['Sales'] # print(x)# print(y) x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, test_size=0.2) model = Lasso() # model = Ridge() alpha_can = np.logspace(-3, 2, 10) #在控制檯輸出過程中,預設小數會以科學計數法的形式輸出,預設值為False np.set_printoptions(suppress=True) #即輸出小數 print('alpha_can = ', alpha_can) lasso_model = GridSearchCV(model, param_grid={'alpha': alpha_can}, cv=5) #GridSearchCV用法參考 http://blog.csdn.net/cherdw/article/details/54970366 lasso_model.fit(x_train, y_train) print('超引數:\n', lasso_model.best_params_) order = y_test.argsort(axis=0) # argsort()函式是將x中的元素從小到大排列,提取其對應的index(索引),然後輸出到y_test print('order: \n',order) y_test = y_test.values[order] #當把索引對應的賦值給y_test時,輸出的y_test自動從小到大排序 print('y_test:',y_test) x_test = x_test.values[order,:] y_hat = lasso_model.predict(x_test) print('score:',lasso_model.score(x_test, y_test)) mse = np.average((y_hat - np.array(y_test)) ** 2) # Mean Squared Error rmse = np.sqrt(mse) # Root Mean Squared Error print({'mse':mse},{'rmse': rmse}) t = np.arange(len(x_test)) mpl.rcParams['font.sans-serif'] = ['simHei'] mpl.rcParams['axes.unicode_minus'] = False plt.figure(facecolor='w') plt.plot(t, y_test, 'r-', linewidth=2, label='真實資料') plt.plot(t, y_hat, 'g-', linewidth=2, label='預測資料') plt.title('線性迴歸預測銷量', fontsize=18) plt.legend(loc='upper left') plt.grid(b=True, ls=':') plt.show()
1、lasso迴歸結果為:{'alpha': 0.59948425031894093},模型得分score: 0.891103116143
{'mse': 2.0226718195221851}
2、將model改為Ridge時輸出結果為:{'alpha': 7.7426368268112773},模型得分score: 0.892714279041 {'mse': 1.9927457676936733}
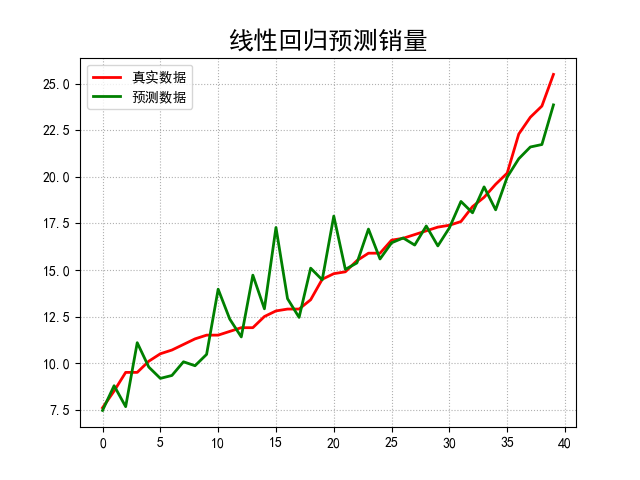
可以看出模型得分非常接近且mse相差也不大,當然本例不能說明兩種方法差別不大,只給出兩種方法的基本實現。其實lasso和ridge分別對應了正則化中的L1和L2,詳情參考http://blog.csdn.net/zouxy09/article/details/24971995/3、注意到如果將下面的程式碼註釋掉order = y_test.argsort(axis=0) # argsort()函式是將x中的元素從小到大排列,提取其對應的index(索引),然後輸出到y_test print('order: \n',order) y_test = y_test.values[order] #當把索引對應的賦值給y_test時,輸出的y_test自動從小到大排序 x_test = x_test.values[order,:]所得的結果相差不大,但得出的圖形變化就大了,因為y_test資料我們沒有進行排序,是亂的,
就出現了下圖所示,為了美觀起見,用argsort()函式做了處理