
多工深度學習程式碼
基於Caffe實現多工學習的小樣例
本節在目前廣泛使用的深度學習開源框架Caffe的基礎上實現多工深度學習演算法所需的多維標籤輸入。預設的,Caffe中的Data層只支援單維標籤,為了支援多維標籤,首先修改Caffe中的convert_imageset.cpp以支援多標籤:
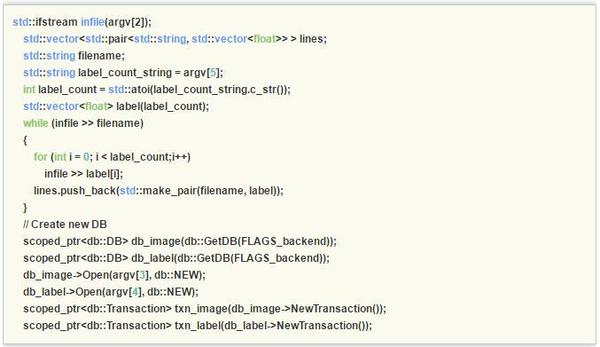 這樣我們就有了多工的深度學習的基礎部分資料輸入。為了向上相容Caffe框架,本文摒棄了部分開源實現增加Data層標籤維度選項並修改Data層程式碼的做法,直接使用兩個Data層將資料讀入,即分別讀入資料和多維標籤,接下來介紹對應的網路結構檔案prototxt的修改,注意紅色的註釋部分。
這樣我們就有了多工的深度學習的基礎部分資料輸入。為了向上相容Caffe框架,本文摒棄了部分開源實現增加Data層標籤維度選項並修改Data層程式碼的做法,直接使用兩個Data層將資料讀入,即分別讀入資料和多維標籤,接下來介紹對應的網路結構檔案prototxt的修改,注意紅色的註釋部分。

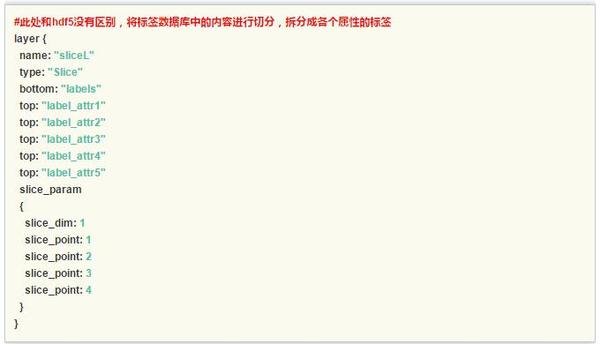
 特別的,slice層對多維的標籤進行了切分,為每個任務輸出了單獨的標籤。
特別的,slice層對多維的標籤進行了切分,為每個任務輸出了單獨的標籤。
 另外一個值得討論的是每個任務的權重設定,在本文實踐中五個任務設定為等權重loss_weight:0.2。一般的,建議所有任務的權重值相加為1,如果這個數值不設定,可能會導致網路收斂不穩定,這是因為多工學習中對不同任務的梯度進行累加,導致梯度過大,甚至可能引發引數溢位錯誤導致網路訓練失敗。
另外一個值得討論的是每個任務的權重設定,在本文實踐中五個任務設定為等權重loss_weight:0.2。一般的,建議所有任務的權重值相加為1,如果這個數值不設定,可能會導致網路收斂不穩定,這是因為多工學習中對不同任務的梯度進行累加,導致梯度過大,甚至可能引發引數溢位錯誤導致網路訓練失敗。

作者:程程
連結:https://zhuanlan.zhihu.com/p/22190532
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
相關推薦
多工深度學習程式碼
轉載自:多工深度學習 基於Caffe實現多工學習的小樣例 本節在目前廣泛使用的深度學習開源框架Caffe的基礎上實現多工深度學習演算法所需的多維標籤輸入。預設的,Caffe中的Data層只支援單維標籤,為了支援多維標籤,首先修改Caffe中的convert_imageset.cpp以支援多標籤: 這樣我們就有
自動學習多工深度學習網路
個人分類: 行人屬性 多工深度學習網路,一般是先設計網路有一些共享層,然後有多個分支學習不同的任務。論文從一個較瘦的網路開始,逐漸加粗。任務間進行選擇性共享,挖掘那些任務之間更相關。thin網路使用SOMP初始化。 task-specific子網路或分支:淺層特徵共享,深層特徵tas
分散式TensorFlow入坑指南:從例項到程式碼帶你玩轉多機器深度學習
通過多 GPU 並行的方式可以有很好的加速效果,然而一臺機器上所支援的 GPU 是有限的,因此本文介紹了分散式 TensorFlow。分散式 TensorFlow 允許我們在多臺機器上執行一個模型,所以訓練速度或加速效果能顯著地提升。本文簡要介紹了分散式 TensorFlow
UC伯克利 NIPS2018 Spotlight論文:依靠視覺想象力的多工強化學習
來源 | AI科技評論 編譯 | 高雲河 AI 科技評論按:NIPS 2018 的錄用論文近期已經陸續揭開面紗,強化學習毫不意外地仍然是其中一大熱門的研究領域。來自加州大學伯克利分校人工智慧實驗室(BAIR)的研究人員分享了他們獲得了 NIPS 2018 spotlight 的研究成果:Vi
如此多的深度學習框架 為什麼我選擇PyTorch
小編說:目前研究人員正在使用的深度學習框架不盡相同,本文介紹了6種常見的深度學習框架,PyTorch與他們相比又有哪些優勢呢?本文選自《深度學習框架PyTorch:入門與實踐》1 PyTorch的誕生2017年1月,Facebook人工智慧研究院(FAIR)團隊在GitHub上
Keras 深度學習程式碼筆記——模型儲存與載入
你可以使用model.save(filepath)將Keras模型和權重儲存在一個HDF5檔案中,該檔案將包含: 模型的結構,以便重構該模型 模型的權重 訓練配置(損失函式,優化器等) 優化器的狀態,以便於從上次訓練中斷的地方開始 使用keras.mod
2010-2016年被引用次數最多的深度學習論文
我相信世上存在值得閱讀的經典的深度學習論文,不論它們的應用領域是什麼。比起推薦大家長長一大串論文,我更傾向於推薦大家一個某些深度學習領域的必讀論文精選合集。 精選合集標準 2016 : +30 引用 「+50」 2015 : +100
Deep Learning(深度學習)程式碼/課程/學習資料整理
轉載自:http://blog.csdn.net/u013854886/article/details/48177251 1. Deep Learning課程(由淺入深): 我們組的一個Deep Learning的比較全面、概括的介紹,視訊:Part1,Part2,Slid
如何免費使用GPU跑深度學習程式碼
從事深度學習的研究者都知道,深度學習程式碼需要設計海量的資料,需要很大很大很大(重要的事情說三遍)的計算量,以至於CPU算不過來,需要通過GPU幫忙,但這必不意味著CPU的效能沒GPU強,CPU是那種綜合性的,GPU是專門用來做影象渲染的,這我們大家都知道,做影象矩陣的計算GPU更加在行,應該我們一般把深
動態分配多工資源的移動端深度學習框架
與雲相比,移動系統受計算資源限制。然而眾所周知,深度學習模型需要大量資源 。為使裝置端深度學習成為可能,應用程式開發者常用的技術之一是壓縮深度學習模型以降低其資源需求,但準確率會有所損失。儘管該技術非常受歡迎,而且已被用於開發最先進的移動深度學習系統,但它有一個重大缺陷:由於應用程式開發者獨立開發自己的應
深度學習之----多工學習
介紹 在機器學習(ML)中,通常的關注點是對特定度量進行優化,度量有很多種,例如特定基準或商業 KPI 的分數。為了做到這一點,我們通常訓練一個模型或模型組合來執行目標任務。然後,我們微調這些模型,直到模型的結果不能繼續優化。雖然通常可以通過這種方式使模型達到可接受的效能,但是
深度神經網路的多工學習概覽(An Overview of Multi-task Learning in Deep Neural Networks)
譯自:http://sebastianruder.com/multi-task/ 1. 前言 在機器學習中,我們通常關心優化某一特定指標,不管這個指標是一個標準值,還是企業KPI。為了達到這個目標,我們訓練單一模型或多個模型集合來完成指定得任務。然後,我們通過精細調參,來改進模型直至效能不再
深度學習之目標檢測常用演算法原理+實踐精講 YOLO / Faster RCNN / SSD / 文字檢測 / 多工網路
深度學習之目標檢測常用演算法原理+實踐精講 YOLO / Faster RCNN / SSD / 文字檢測 / 多工網路 資源獲取連結:點選這裡 第1章 課程介紹 本章節主要介紹課程的主要內容、核心知識點、課程涉及到的應用案例、深度學習演算法設計通用流程、適應人群、學習本門
推薦系統遇上深度學習(十九)--探祕阿里之完整空間多工模型ESSM
歡迎關注天善智慧,我們是專注於商業智慧BI,人工智慧AI,大資料分析與挖掘領域的垂直社群,學習,問答、求職一站式搞定! 對商業智慧BI、大資料分析挖掘、機器學習,python,R等資料領域感興趣的同學加微信:tsaiedu,並註明訊息來源,邀請你進入資料愛好者交流群,資料愛好者們都
遷移學習(transfer learning)、多工學習(multi-task learning)、深度學習(deep learning)概念摘抄
本文在寫作過程中參考了諸多前輩的部落格、論文、筆記等。由於人數太多,在此不一一列出,若有侵權,敬請告知,方便我進行刪改,謝謝!!! 遷移學習(Transfer Learning) 遷移學習出現的背景如下:在一些新興領域很難得到我們需要的大量的訓練資料,另外,傳統的機器學習
多工學習與深度學習
作者:chen_h 微訊號 & QQ:862251340 微信公眾號:coderpai 多工學習是機器學習的一個子領域,學習的目標是同事執行多個相關任務。比如,系統會同時執行學習兩項任務,以便這兩項任務都有助於別的任務的學習。這是模仿人類
深度學習DeepLearning.ai系列課程學習總結:8. 多層神經網路程式碼實戰
轉載過程中,圖片丟失,程式碼顯示錯亂。 為了更好的學習內容,請訪問原創版本: http://www.missshi.cn/api/view/blog/59ac0136e519f50d040001a7 Ps:初次訪問由於js檔案較大,請耐心等候(8s左
深度學習:多層感知機MLP數字識別的程式碼實現
深度學習我看的是neural network and deep learning 這本書,這本書寫的真的非常好,是我的導師推薦的。這篇部落格裡的程式碼也是來自於這,我最近是在學習Pytorch,學習的過程我覺得還是有必要把程式碼自己敲一敲,就像當初學習機器學習一
深度學習 多卡 python設置
深度 ice environ 設置 bsp 通過 python dev ron 首先 import os 然後通過 os.environ[‘CUDA_VISIBLE_DEVICES‘]=來設置用哪張卡 比如使用編號為0的卡:import os
深度學習TensorFlow如何使用多GPU並行模式?
深度學習 tensorflow TensorFlow可以用單個GPU,加速深度學習模型的訓練過程,但要利用更多的GPU或者機器,需要了解如何並行化地訓練深度學習模型。常用的並行化深度學習模型訓練方式有兩種:同步模式和異步模式。下面將介紹這兩種模式的工作方式及其優劣。如下圖,深度學習模型的訓練是一個叠代