
評估分類器效能及提升分類器準確率的組合方法
評估分類器效能
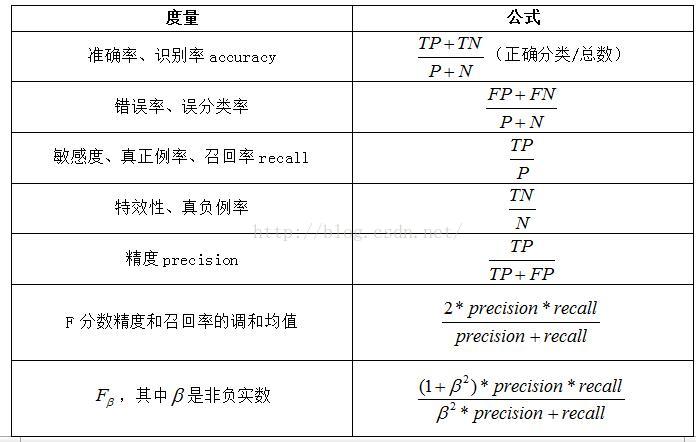
TP,TN,FP,FN,P,N分別表示真正例、真負例、假正例、假負例、正和負樣本數
含意
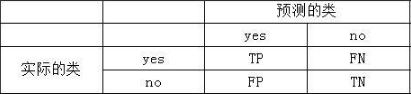
TP(true positive):指被分類器正確分類的正元組
TN(true negative):指被分類器正確分類的負元組
FP(false positive):被錯誤地標記為正元組的負元組
FN(false negative):被錯誤地標記為負元組的正元組
提升分類器準確率的組合方法
- 袋裝
- 提升
- 隨機森林
介於袋裝、提升、隨機森林的介紹,大家可以參考該部落格,通俗易懂的講解
https://blog.csdn.net/qq_18668137/article/details/81135888
相關推薦
評估分類器效能及提升分類器準確率的組合方法
評估分類器效能 TP,TN,FP,FN,P,N分別表示真正例、真負例、假正例、假負例、正和負樣本數 含意 TP(true positive):指被分類器正確分類的正元組 TN(true negative):指被分類器正確分類的負元組 FP(false positive
影象分類基本流程及 KNN 分類器
1. 影象分類以及基本流程 1.1 什麼是影象分類 所謂影象分類問題,就是已有固定的分類標籤集合,然後對於輸入的影象,從分類標籤集合中找出一個分類標籤,最後把分類標籤分配給該輸入影象。雖然看起來挺簡單的,但這可是計算機視覺領域的核心問題之一,計算機視覺領域中很多看似不同的問題(比如物體檢
樸素貝葉斯分類演算法理解及文字分類器實現
貝葉斯分類是一類分類演算法的總稱,這類演算法均以貝葉斯定理為基礎,故統稱為貝葉斯分類。本文作為分類演算法的第一篇,將首先介紹分類問題,對分類問題進行一個正式的定義。然後,介紹貝葉斯分類演算法的基礎——貝葉斯定理。最後,通過例項討論貝葉斯分類中最簡單的一種:樸素貝葉斯分類。
小程序上傳文件到微信服務器,及開發者服務器獲取上傳文件
emp span 回調 data pre lose 數據 blank some 微信官方參考文檔:https://developers.weixin.qq.com/miniprogram/dev/api/network/upload/wx.uploadFile.html
css —— 選擇器優先順序及jQuery遍歷元素常用方法
一、部分常用css選擇器 1、子元素選擇器:> 作用:只選取直接子元素。 優點:使html元素層次很清晰的呈現。 2、相鄰兄弟元素選擇器:+ 作用:選取相鄰兄弟元素中的第二個。適用於兄弟元素(可以是不同元素)第一個與後面的(某個或所有)樣式不一樣的場合。 例: &l
css——選擇器 選擇器優先順序 優先順序提升 選擇器權重計算 繼承性
1、選擇器 :focus——選擇具有焦點的輸入元素 :first-letter——選擇元素的第一個字母 :first-line——選擇元素的第一行 :before——在元素之前插入內容 :af
【scikit-learn】評估分類器效能的度量,像混淆矩陣、ROC、AUC等
6. ROC曲線和AUC¶ ROC曲線指受試者工作特徵曲線/接收器操作特性(receiver operating characteristic,ROC)曲線, 是反映靈敏性和特效性連續變數的綜合指標,是用構圖法揭示敏感性和特異性的相互關係,它通過將連續變數設定出多個不同的臨界值,從而計算出一系列敏感性和特異
opencv測試分類器效能 opencv_performance.exe 使用方法 及引數含義
Test Samples 原文:點選開啟連結 In order to evaluate the performance of trained classifier a collection of marked up images is needed
python中使用整合模型,隨機森林分類器,梯度提升決策樹效能模型分析 視覺化
import pandas as pd titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt') #titanic = pd.read_csv('.
貝葉斯分類器演算法及案例詳解
作者:vicky_siyu 致謝:小龍快跑jly, 巧兒、克力,Esther_or so,雨佳小和尚 本文是對貝葉斯分類器(包括樸素貝葉斯分類器,半樸素貝葉斯分類器及貝葉斯網路)演算法的演算及案例的詳細分析。本文只是在學習後進行了總結並加入了自己的理解,如有不妥之處,還望海涵,也希望大家
理解貝葉斯分類器原理及關係
作者:vicky_siyu 致謝:小龍快跑jly, 巧兒、克力,Esther_or so,雨佳小和尚 本文是對貝葉斯分類器的初步理解,通過案例解釋貝葉斯並對貝葉斯分類器的關係進一步分析和理解。本文只是在學習後進行了總結並加入了自己的理解,如有不妥之處,還望海涵,也希望大家多多指教,一起學
【機器學習】分類器效能指標
1. 錯誤率: e = 錯誤分類個數/總樣本數 2. 正確率: TP:分類正確正例 TN:分類正確負例 FP:分類錯誤正例 FN:分類錯誤負例 precision = 分類正確的正類/(預測結果中被分為正類的個數) = TP/(TP+FP) 3. 召回
資料不平衡時分類器效能評價(ROC曲線)
大家在將統計學習方法用於實際應用時,不免會遇到各類間資料不太平衡的情況。比如垃圾郵件的識別、稀有病情的診斷、詐騙電話識別、情感分析等等情況。導致資料不平衡的原因有很多,有可能是因為不恰當的取樣方法,也可能真實的資料分佈就是如此;然而真實的資料分佈在大多數情況下我們是無從得知
拉普拉斯修正的樸素貝葉斯分類器及AODE分類器
下面的一些原理來著周志華老師的西瓜書。 *************************************************************************************************************** 拉普拉斯
分類器設計之線性分類器和線性SVM(含Matlab程式碼)
對於高維空間的兩類問題,最直接的方法是找到一個最佳的分類超平面,使得並且,對於所有的正負訓練樣本和. 因此,以上問題可以表達為: 問題P0可以轉化為 兩邊除以\epsilon,並且做變數替換,最終得到下面的線性規化(linear programming
文字分類——演算法效能評估
內容提要 資料集 英文語料 中文語料 評估指標 召回率與準確率 F1-評測值 微平均與巨集平均 混淆矩陣 優秀的文字分類模型必須經得住真實資料集的驗證,因而分類器
【火爐煉AI】深度學習010-Keras微調提升效能(多分類問題)
【火爐煉AI】深度學習010-Keras微調提升效能(多分類問題) (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2, Keras 2.1.6, Tensorflow 1.9.0) 前面的文章(【火爐
用KNN分類器進行貓狗分類
1. KNN簡單介紹 KNN名字是K-nearest neighbors。Nearest neighbors是最鄰近的,K是指數量。其思想大概是,在空間中先放置好所有用於訓練的樣品,把測試樣品置於該空間中。用距離公式計算出離測試樣品最近的K個樣品,假如K個樣品中屬於A類的最
機器學習演算法:交叉驗證——(監督)學習器效能評估方法 [ sklearn.model_selection.cross_val_score()官方翻譯 ]
交叉驗證——(監督)學習器效能評估方法 一、思考:交叉驗證有什麼好值得我們使用的? 每個演算法模型都需要經過兩個階段:訓練和驗證。 1) 一般情況下的,我們用的方法是:將原始資料集分為 訓練資料集 & 測試資料集。 優點:是,但僅僅是思路正確。 缺點:思
python資料探勘入門與實踐--------電離層(Ionosphere), scikit-learn估計器,K近鄰分類器,交叉檢驗,設定引數
ionosphere.data下載地址:http://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/ 原始碼及相關資料下載 https://github.com/xxg1413/MachineLea