
文字分類——演算法效能評估
內容提要
優秀的文字分類模型必須經得住真實資料集的驗證,因而分類器必須在通用的資料集上進行測試。用於文字分類的資料集一般稱為語料庫。
語料庫指經科學取樣和加工的大規模電子文字庫。藉助計算機分析工具,研究者可開展相關的語言理論及應用研究。語料庫中存放的是在語言的實際使用中真實出現過的語言材料;語料庫是以電子計算機為載體承載語言知識的基礎資源;真實語料需要經過加工(分析和處理),才能成為有用的資源。
資料集
機器學習是一個認識事物、獲取知識的過程。其任務是把現有的對客觀事物的認識與理解進行選擇、提取、組織與分類。通過對大量的真實文字的學習來發現和探索自然語言的各種事實與規律。機器學習的所獲取的知識物件一般稱為資料集。自然語言處理領域的資料集一般稱為語料庫。語料庫的建設已經經歷了半個多世紀的發展歷程。從最早的上世紀六十年代初的布朗語料庫和七十年代初的LOB語料庫,一直髮展到美國計算機語言協會ACL/DCI語料庫的建設。語料庫語言學目前已經成為自然語言處理領域的熱門科研課題。
文字分類的主流模型是基於統計學建立,統計機器學習模型的基礎就是要有統計來源或素材,因此語料庫在文字分類研究中的地位非常關鍵。分類器的實現需要建立在一個已經人工標註好的訓練資料集上,訓練集質量的優劣對文字分類的效能有著決定性的意義。語料庫不僅能夠為分類器提供機器學習的素材,而且可以評測分類器的分類效能,指導優化分類效果。
用於文字分類的語料庫一般分為平衡語料庫和非平衡語料庫。語料庫中每一個類的文字數相等或大致相等一般稱為平衡語料庫,而每個類別下文字數不相等的語料庫稱為非平衡語料庫。兩種語料庫對文字分類的研究都有重要的意義。
英文語料
a) 20_Newsgroups 資料集:卡內基梅隆大學的Lang於1995年收集並整理的包含19997篇文件約平均分佈在20個類別中的Usenet新聞組語料。Newsgroups已經成為文字分類及聚類中常用的資料集。麻省理工學院(MIT)的 Jason Rennie 對其作了必要的處理,形成 Newsgroups-18828。原始 Newsgroups 屬於平衡語料庫。
b) Reuters-21578 資料集:路透社人工彙集和分類形成,共包含路透社1987年的21578篇新聞稿,一般作為英文檔案分類領域的基準語料庫。該語料庫為非平衡語料庫。
c) OHSUMED 資料集:由 William Hersh 等人共同收集並整理,文件來源於醫藥資訊資料庫MEDLINE10,收集從1987 至1991 年270個醫藥類期刊的標題和(或)摘要,共含有348566篇文件。
中文語料
a) TanCorpV1.0 資料集:中國科學院計算技術研究所譚鬆波收集整理。該語料庫分為兩層,第一層12個類別,第二層60個類別,共包含文字14150篇。該語料庫每個類包含文字數差異較大,為典型的非平衡語料庫。
b) 搜狗實驗室資料集:經過編輯手工整理與分類的新聞語料,新聞來源於搜狐新聞網站。搜狗實驗室根據需求不同整理了多個版本。一般常用的是SogouC.reduced.20061127語料庫,分為9個大類別,每類包含1990篇文件,共包含17910篇文件。另外完整版SogouC語料庫共有10個類,每類包含8000篇文件,共包含80000篇文件。該語料庫為平衡語料庫。
c) 復旦大學資料集:由復旦大學計算機資訊與技術系國際資料庫中心自然語言處理小組李榮陸提供,分為20個類別,包含9833篇測試文件和9804篇訓練文件。另外,還提供了一個小規模語料庫,分為10個類別,共2816篇文件。該語料庫屬於非平衡語料庫。
評估指標
人們根據不同的文字分類應用背景提出了多種評估分類系統性能的標準。常用的評估標準:召回率(Recall)、準確率(Precision)、F1-評測值(F1-measure)、微平均(Micro-average)和巨集平均(Macro-average)。另外一些使用較少的評估方法包括平衡點(break-even point)、11點平均正確率(11-point average precision)等。本文中所涉及到的“精度”(Accuracy)一般指廣義精度,可以代表召回率、精確率、F1-評測值(簡記:F1值)、微平均和巨集平均等評價指標。
假設一個文字分類系統針對類別ci 的分類標註結果統計如表所示:

或者用等價的集合描述如圖所示:
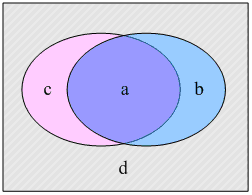
圖左側橢圓表示實際測試集類別標註,右側橢圓是經過分類器分類後標註的分類結果。上圖與表的中符號的意義如下:
1) a表示正確地標註測試集文字為類別ci 的文字數量;
2) b表示錯誤地標註測試集文字為類別ci 的文字數量;
3) c表示錯誤地排除測試集文字在類別ci 之外的文字數量;
4) d表示正確地排除測試集文字在類別ci 之外的文字數量。
召回率與準確率
a) 分類器在類別ci 上的召回率(又稱查全率)定義如式:
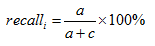
b) 分類器在類別ci 上的準確率(又稱查準率)定義如式:
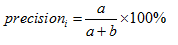
F1-評測值
c) 分類器在類別ci 上的F1值定義如式:

召回率和準確率分別從兩個方面考察分類器的分類效能。召回率過高可能導致準確率過低,反之亦然。所以綜合考慮分類結果召回率和準確率的平衡,採用F1-評測值比較合理。
微平均與巨集平均
文字分類系統的分類結果,每個類對應都有一個召回率和準確率,它們評價的是單個類別上的分類精度。因此,可以通過這些單個類別的精度評價整個分類系統的整體效能。
微平均從分類器的整體角度考慮,不考慮分類體系的小類別上的分類精度。它是利用被正確分類標註的文字總數aall ,被錯誤分類標註的文字總數ball ,以及應當被正確分類標註而實際上卻被錯誤地排除的文字總數call 分別替換上式中的a、b、c得到的微平均召回率、微平均準確率和微平均F1值。 微平均本質講是一項考察分類器整體能夠正確分類標註多少文字。如果每一篇文字必須屬於一個類別的話,則有下式成立:
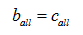
那麼微平均召回率、微平均準確率與微平均F1值相等。所以微平均F1值計算如下式所示:

巨集平均是從分類器小類別的整體考慮,首先計算出每一類別的召回率與準確率,然後對召回率與準確率分別取算術平均得到的巨集平均召回率與巨集平均準確率。最後根據巨集平均召回率與巨集平均準確率計算巨集平均F1值。
a) 巨集平均召回率
其計算式如下所示:
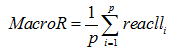
其中 recalli 為類別ci 的準確率,P 為分類體系類別數目。
b) 巨集平均準確率
其計算式如下所示:

其中 precisioni 為類別ci 的召回率,P 為分類體系類別數目。
c) 巨集平均F1值
其計算式如下所示:
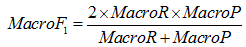
巨集平均考察分類器對不同類別的處理能力。尤其在非平衡資料集上,巨集平均能夠更好地衡量分類器處理小樣本類別的分類能力。換句話說,微平均從文字分類標註正確總數角度衡量分類精度,巨集平均是從每一類別文字標註正確的角度衡量分類精度。
混淆矩陣
混淆矩陣(Confusion Matrix):在文字分類中,使用混淆矩陣顯示分類測試標註的統計情況,是一種視覺化結果統計顯示工具。其形式如表所示:

表2中第一行代表實際測試的資料集類別,每一類代表對應第一類實際類別被分類的情況。例如對應類別ci 的表1中的c值與b值分別如下式所示:

表2中對角線上的值就是每一個類正確分類的文字數(表1中的a)。
參考文獻:
[1] Sebastiani,F. Machine learning in automated text categorization [J]. ACM Comput. Surv. 34(1): 1-47.
[2] 靖紅芳,王斌,楊雅輝,徐燕.基於類別分佈的特徵選擇框架[J].計算機研究與發展,46(9):1586-1593.
[3] Tan,S. B.,Cheng,X. Q.,Ghanem,M. M.,Wang,B.,Xu,H. B. A novel refinement approach for text categorization [C]. In: ACM CIKM
[4] 蘇金樹,張博鋒,徐昕. 基於機器學習的文字分類技術研究進展[J].軟體學報,17(9):1848~1859.
[5] Joachims,T. A probabilistic analysis of the Rocchio algorithm with TFIDF for text categorization [C]. In: Proc. of the ICML’97:143-151.
[6] 譚鬆波,王月粉.中文文字分類語料庫-TanCorpV1.0 .
[7] Kim,H. J.,Shrestha,J.,Kim,H. N.,et al. User action based adaptive learning with weighted Bayesian classification for filtering spam mail [J]. Lecture Notes in Artificial Intelligence,43(4):790-798.
[8] 中國科學院計算技術研究所自然語言處理研究組. 文字分類評測大綱.