
使用Spark MLlib 完成新聞自動分類
阿新 • • 發佈:2019-01-07
寫在前面
最近學習了一點文字挖掘相關知道,剛剛接觸到一點皮毛,剛好學了點Spark,所有就找個了小例子玩了一下,演算法和實現都不太難,比較適合看公式一臉蒙逼,無聊想來點實際性Demo玩一下
基本流程
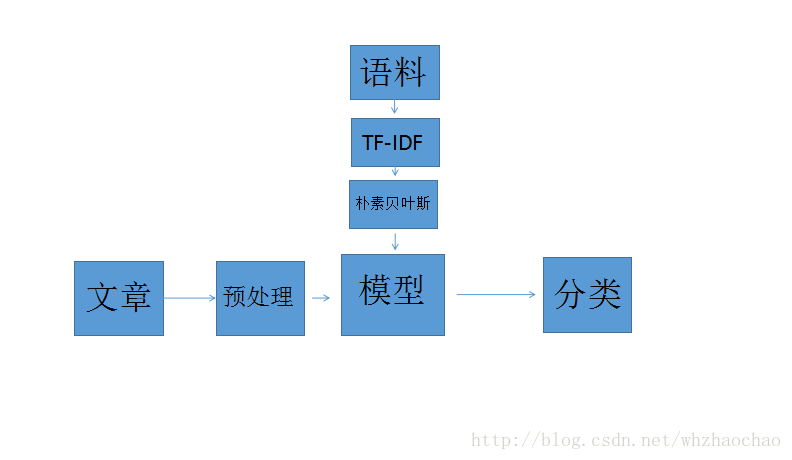
如圖所示為新聞自己分類的基本流程,其中主要包含以下幾點
語料
分類語料庫用搜狗實驗室http://www.sogou.com/labs/的資料,語料庫中共10個分類,總計50多萬條記錄,每條記錄由對應的分類編號加對應關鍵片語成,語料庫中格式如下
0,蘋果 官網 蘋果 宣佈 ...
1,蘋果 梨 香蕉 ...
其中
0 汽車
1 財經
2 IT
3 健康
4 體育
5 旅遊
6 教育
7 TF-IDF
TF-IDF這個特徵演算法是比較簡單的,用來簡單提取特徵值學習一下還是可以的,具體演算法可以百度一下,Spark 官網也有介紹:中文,英文,部落格
樸素貝葉斯分類器
樸素貝葉斯分類器主要根據貝葉斯概率公式計算事件之間的概率,基本演算法原理可以參考部落格
Spark 教程 英文 ,中文
新聞資料
這裡的新聞資料是用來分類的,可以從網際網路上爬取,我裡我自己準備了點資料,資料以JSON格式儲存,格式如下
{"topicurl":"http://zzhz.zjol.com.cn/system/2017/06/08/021530999.shtml","is_topic 文章預處理
這裡主要是針對從網上爬過來的新聞資料進行格式轉換和分詞操作,分詞器使用ansj_seg GitHub地址 https://github.com/NLPchina/ansj_seg
經過預處理後,新聞資料就成了一個由關鍵片語成的文件
主要程式碼
主流程程式碼
def main(args: Array[String]): Unit = {
//建立sparkSession
val sparkSession = SparkSession.builder
.config("spark.sql.warehouse.dir", "D:\\WorkSpace\\spark\\spark-learning\\spark-warehouse")
.master("local")
.appName("spark session example")
.getOrCreate()
val trainRdd = sparkSession.sparkContext.textFile("E:\\file\\res\\allType.txt").map(x => {
val data = x.split(",")
(data(0), data(1))
})
//IT-IDF
val trainTFDF = toTFIDF(sparkSession, trainRdd)
//標示點
var trainPoint = trainTFDF.map {
x =>
LabeledPoint(x._1.toDouble, Vectors.dense(x._3.toArray))
}
//訓練模型
val model = NaiveBayes.train(trainPoint)
//儲存模型資料
// model.save(sparkSession.sparkContext,"E:\\model")
// val model=NaiveBayesModel.load(sparkSession.sparkContext,"E:\\model")
//載入新聞資料
val testData = loadTestData(sparkSession, "E:\\zjol\\21531000.json")
//TF-IDF
val testDataTFIDF = toTFIDF(sparkSession, testData)
//測試分類
val res = testDataTFIDF.map({
x => {
(x._1, model.predict(Vectors.dense(x._3.toArray)))
}
})
//新聞ID,分類
res.foreach(x => println(x._1 + " " + x._2))
}特徵提取
/**
* 對RDD新聞進行TF-IDF特徵計算
* @param rdd
* @return
*/
def toTFIDF(sparkSession: SparkSession, rdd: RDD[Tuple2[String, String]]) = {
val df = rdd.map(x => {
Row(x._1, x._2)
})
val schema = StructType(
Seq(
StructField("category", StringType, true)
, StructField("text", StringType, true)
)
)
//將dataRdd轉成DataFrame
val srcDF = sparkSession.createDataFrame(df, schema)
srcDF.createOrReplaceTempView("news")
srcDF.select("category", "text").take(2).foreach(println)
//將分好的詞按空格拆分轉換為DataFrame
var tokenizer = new Tokenizer().setInputCol("text").setOutputCol("words")
var wordsData = tokenizer.transform(srcDF)
wordsData.select("category", "text", "words").take(2).foreach(println)
val hashingTF = new HashingTF(Math.pow(2, 18).toInt)
val tfDF1 = wordsData.rdd.map(row => {
val words = row.getSeq(2)
(row.getString(0), row.getString(1), hashingTF.transform(words))
})
val tfDF = wordsData.rdd.map(row => {
val words = row.getSeq(2)
hashingTF.transform(words)
})
val idf = new IDF().fit(tfDF)
val num_idf_pairs = tfDF1.map(x => {
(x._1, x._2, idf.transform(x._3))
})
num_idf_pairs.take(10).foreach(println)
num_idf_pairs
}
資料預處理
/**
* 載入測試json新聞資料
* @param sparkSession
* @param path
* @return
*/
def loadTestData(sparkSession: SparkSession, path: String) = {
val df = sparkSession.read.json(path)
df.printSchema()
df.createOrReplaceTempView("news")
val sql = "select author,body,is_topic,keywords,newsid,pub_time,source,sub_title,title,top_title,topicurl from news"
val rdd = sparkSession.sql(sql).rdd.map(row =>
(
row.getString(4).substring(1).toLong,
row.getString(8),
getTextFromTHML(row.getString(6))
)
).filter(x => (!x._2.equals("") && !x._3.equals("") && x._3.length>200 ))
val newsRdd = rdd.map(x => {
val words = ToAnalysis.parse(x._3).getTerms
var string = ""
val size = words.size()
for (i <- 0 until size) {
string += words.get(i.toInt).getName + " "
}
(x._1.toString, string)
})
newsRdd
}
/**
* 抽取HTML中文字
* @param htmlStr
* @return
*/
def getTextFromTHML(htmlStr: String): String = {
val doc = Jsoup.parse(htmlStr)
var text1 = doc.text()
// remove extra white space
val builder = new StringBuilder(text1)
var index = 0
while ( {
builder.length > index
}) {
val tmp = builder.charAt(index)
if (Character.isSpaceChar(tmp) || Character.isWhitespace(tmp)) builder.setCharAt(index, ' ')
index += 1
}
text1 = builder.toString.replaceAll(" +", " ").trim
text1
}結果
結果資料以文章ID加分類編號組成
21530024 7.0
21530023 6.0
21530022 7.0
21530021 3.0
21530019 7.0
21530018 8.0
21530017 5.0
21530016 3.0
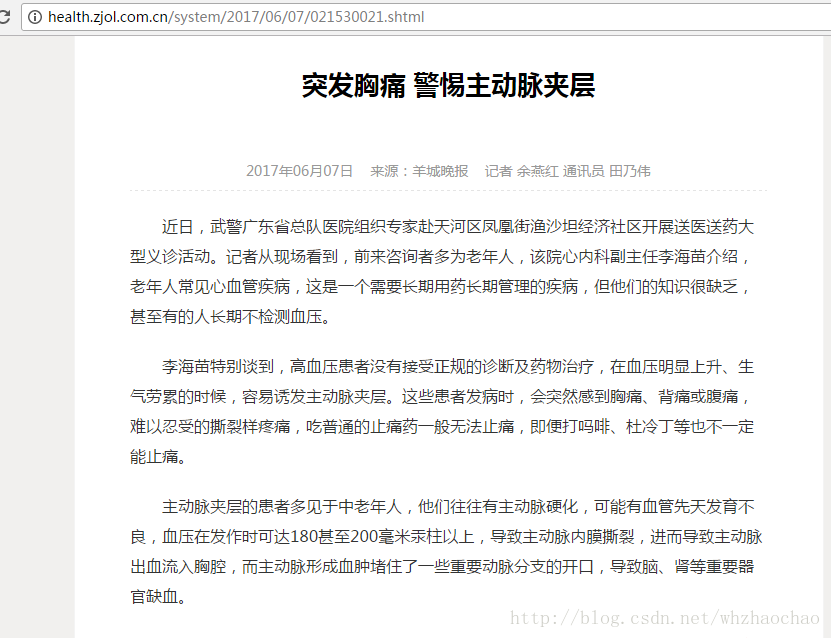
21530015 3.021530021 這篇新聞分類為3.0(健康),新聞如下 :
計算正確率
val testRdd = sparkSession.sparkContext.textFile("E:\\file\\res\\test.txt").map(x => {
val data = x.split(",")
(data(0), data(1))
})
//IT-IDF
val testrainTFDF = toTFIDF(sparkSession, testRdd)
//測試分類
val res = testrainTFDF.map({
x => {
(x._1, model.predict(Vectors.dense(x._3.toArray)))
}
})
//新聞ID,分類
res.foreach(x => println(x._1 + " " + x._2))
//新聞總數
val allCount=res.count()
//分類正確數量
val find=res.filter(x=>x._1.toDouble.equals(x._2));
find.foreach(x=>println(x._1+" "+x._2))
//8856 11533
println(find.count()+" "+allCount)正確率為 76.9%