
【Deep Learning】tensorflow實現卷積神經網路(AlexNet)
一、實驗要求
1.使用卷積神經網路實現圖片分類,資料集為OxFlowers17;
二、實驗環境
Anaconda2-4.3.1(Python2.7),tensorflow-cpu。
三、實驗原理
3.1 資料讀取
已知資料集是連續80個樣本為一個分類,有17個類別,所以一共只有1360個樣本,所以首先用一個函式把每一類的樣本分到一個資料夾,資料夾的名字從0開始命名,接著進行資料的讀取,由於本次實驗使用的資料集比較小,因而沒有劃分出驗證集,根據官網給出的劃分資料集的方法,把驗證集也劃分給訓練集,以豐富訓練集,最後得到1020個訓練樣本和340個測試樣本。
對應程式碼:loadData.py
# -*- coding: UTF-8 -*- import os import numpy as np import scipy.io as sio from PIL import Image dir='../oxflower17/jpg/' def to_categorical(y, nb_classes): y = np.asarray(y, dtype='int32') if not nb_classes: nb_classes = np.max(y)+1 Y = np.zeros((1, nb_classes)) Y[0,y] = 1. return Y def build_class_directories(dir): dir_id = 0 class_dir = os.path.join(dir, str(dir_id)) if not os.path.exists(class_dir): os.mkdir(class_dir) for i in range(1, 1361): fname = "image_" + ("%.4i" % i) + ".jpg" os.rename(os.path.join(dir, fname), os.path.join(class_dir, fname)) if i % 80 == 0 and dir_id < 16: dir_id += 1 class_dir = os.path.join(dir, str(dir_id)) os.mkdir(class_dir) def get_input(resize=[224,224]): print 'Load data...' getJPG = lambda filePath: np.array(Image.open(filePath).resize(resize)) dataSet=[];labels=[];choose=1 classes = os.listdir(dir) for index, name in enumerate(classes): class_path = dir+ name + "/" if os.path.isdir(class_path): for img_name in os.listdir(class_path): img_path = class_path + img_name img_raw = getJPG(img_path) dataSet.append(img_raw) y=to_categorical(int(name),17) labels.append(y) datasplits = sio.loadmat('../oxflower17/datasplits.mat') keys = [x + str(choose) for x in ['val', 'trn', 'tst']] train_set, vall_set, test_set = [set(list(datasplits[name][0])) for name in keys] train_data, train_label,test_data ,test_label= [],[],[],[] for i in range(len(labels)): num = i + 1 if num in test_set: test_data.append(dataSet[i]) test_label.extend(labels[i]) else: train_data.append(dataSet[i]) train_label.extend(labels[i]) train_data = np.array(train_data, dtype='float32') train_label = np.array(train_label, dtype='float32') test_data = np.array(test_data, dtype='float32') test_label = np.array(test_label, dtype='float32') return train_data, train_label,test_data ,test_label def batch_iter(data, batch_size, num_epochs, shuffle=True): data = np.array(data) data_size = len(data) num_batches_per_epoch = int((len(data)-1)/batch_size) + 1 for epoch in range(num_epochs): # Shuffle the data at each epoch if shuffle: shuffle_indices = np.random.permutation(np.arange(data_size)) shuffled_data = data[shuffle_indices] else: shuffled_data = data for batch_num in range(num_batches_per_epoch): start_index = batch_num * batch_size end_index = min((batch_num + 1) * batch_size, data_size) yield shuffled_data[start_index:end_index] if __name__=='__main__': #build_class_directories(os.path.join(dir)) train_data, train_label,test_data, test_label=get_input() print len(train_data),len(test_data)
3.2 模型介紹
本次實驗使用的是AlexNet模型,AlexNet共有八層,其前五層是卷積層,後三層是全連線層。最後一個全連線層的輸出具有17個輸出單元。
其中第一個卷積層conv1,採用了96個11 * 11 的kernel,stride為4,第二層卷積層conv2採用了192個5 * 5 的kernel,stride為1,後面三層的分別為384個3*3的kernel,256個3*3的kernel,256個3*3的kernel,所有的stride均為1,並且只有第一,第二和第五層有pooling層和Norm(norm1)變換。為了防止過擬合,在這三層設定了dropout,dropout值為0.5,最後是三層的全連線層,輸出為17個神經單元,所有的啟用函式都是relu函式,我們把這些東西全部放在一個類裡進行實現。具體可見程式碼及下圖1用tensorboard生成模型圖。
分類問題的標準損失函式是交叉熵損失函式加上最後一層全連線層引數正則化*0.01。
對應程式碼:AlexNet.py
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
def conv(input,fh,fw,n_out,name):
n_in = input.get_shape()[-1].value
with tf.name_scope(name) as scope:
filter = tf.get_variable(scope+"w", shape=[fh, fw, n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
conv = tf.nn.conv2d(input, filter, [1,4,4,1], padding='SAME')
bias_val = tf.constant(0.0, shape=[n_out], dtype=tf.float32)
biases = tf.Variable(bias_val, trainable=True, name='b')
z = tf.nn.bias_add(conv, biases)
relu = tf.nn.relu(z, name=scope)
return relu
def conv_layer(input,fh,fw,n_out,name):
n_in = input.get_shape()[-1].value
with tf.name_scope(name) as scope:
filter = tf.get_variable(scope+"w", shape=[fh, fw, n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
conv = tf.nn.conv2d(input, filter, [1,1,1,1], padding='SAME')
bias_val = tf.constant(0.0, shape=[n_out], dtype=tf.float32)
biases = tf.Variable(bias_val, trainable=True, name='b')
z = tf.nn.bias_add(conv, biases)
relu = tf.nn.relu(z, name=scope)
return relu
def full_connected_layer(input, n_out,name):
shape = input.get_shape().as_list()
dim = 1
for d in shape[1:]:
dim *= d
x = tf.reshape(input, [-1, dim])
n_in = x.get_shape()[-1].value
with tf.name_scope(name) as scope:
filter = tf.get_variable(scope+"w", shape=[n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
bias_val = tf.constant(0.1, shape=[n_out], dtype=tf.float32)
biases = tf.Variable(bias_val, name='b')
fc = tf.nn.relu_layer(input, filter, biases, name=scope)
return fc
def max_pool_layer(input,name):
return tf.nn.max_pool(input, ksize=[1,3,3,1], strides=[1,2,2,1],padding='SAME', name=name)
def norm(name, l_input, lsize=4):
return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name)
class CNN(object):
def __init__(
self, num_classes,l2_reg_lambda=0.01):
self.input_x = tf.placeholder(tf.float32, [None, 224,224,3], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
l2_loss = tf.constant(0.1)
with tf.name_scope("conv-maxpool"):
# first layer
self.conv1_1 = conv(self.input_x,fh=11, fw=11,n_out=96,name="conv1_1")
self.pool1 = max_pool_layer(self.conv1_1,name='pool1')
self.norm1 = norm('norm1', self.pool1, lsize=4)
self.norm1 = tf.nn.dropout(self.norm1, self.dropout_keep_prob)
# second layer
self.conv2_1 = conv_layer(self.norm1, fh=5, fw=5, n_out=192,name='conv2_1')
self.pool2 = max_pool_layer(self.conv2_1, name='pool2')
self.norm2 = norm('norm2', self.pool2, lsize=4)
self.norm2 = tf.nn.dropout(self.norm2, self.dropout_keep_prob)
# Third layer
self.conv3_1 = conv_layer(self.norm2, fh=3, fw=3, n_out=384, name='conv3_1')
self.conv3_2 = conv_layer(self.conv3_1,fh=3, fw=3, n_out=256, name='conv3_2')
self.conv3_3 = conv_layer(self.conv3_2, fh=3, fw=3, n_out=256, name='conv3_3')
self.pool3 = max_pool_layer(self.conv3_3, name='pool3')
self.norm3 = norm('self.norm3', self.pool3, lsize=4)
self.norm3 = tf.nn.dropout(self.norm3,self.dropout_keep_prob)
# Combine all the pooled features
shape = self.norm3.get_shape().as_list()
self.dim = 1
for d in shape[1:]:
self.dim *= d
self.h_pool_flat= tf.reshape(self.norm3, [-1, self.dim])
with tf.name_scope("output"):
W1 = tf.get_variable(
"W1",
shape=[self.dim, 4096],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.constant(0.1, shape=[4096]), name="b1")
l2_loss += tf.nn.l2_loss(W1)
l2_loss += tf.nn.l2_loss(b1)
self.dense1 = tf.nn.relu(tf.matmul(self.h_pool_flat,W1)+b1, name='fc1')
W2 = tf.get_variable(
"W2",
shape=[4096, 4096],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.constant(0.1, shape=[4096]), name="b2")
l2_loss += tf.nn.l2_loss(W2)
l2_loss += tf.nn.l2_loss(b2)
self.dense2 = tf.nn.relu(tf.matmul(self.dense1,W2)+b2, name='fc2')
W3 = tf.get_variable(
"W3",
shape=[4096, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b3")
l2_loss += tf.nn.l2_loss(W3)
l2_loss += tf.nn.l2_loss(b3)
self.out = tf.matmul(self.dense2,W3)+b3
# CalculateMean cross-entropy loss
self.loss=0
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.out, labels=self.input_y)
self.loss = tf.reduce_mean(losses)+l2_reg_lambda*l2_loss
# Accuracy
self.accuracy=0
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(tf.argmax(self.out,1), tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
圖1 網路模型
3.3 訓練過程
訓練的一些引數:
①batch_size:40
②num_epochs:80
③evaluate_every:30
④checkpoint_every:30
⑤num_checkpoints:5
在訓練的過程中,我們通過在訓練和評估階段來跟蹤和視覺化各種引數,以檢視損失值和正確值是如何變化的,在訓練階段和評估階段,記錄的彙總資料都是一樣的,我們使用 SummaryWriter 函式來將它們寫入磁碟中。
同時還設定了檢查點(checkpointing),用來儲存模型的引數以備以後恢復。檢查點可用於在以後的繼續訓練,或者提前來終止訓練,從而能來選擇最佳引數。檢查點是使用 Saver 物件來建立的。
訓練時我們定義一個訓練函式train_step,用於單個訓練步驟,在一批資料上進行評估,並且更新模型引數,我們對資料集進行批次迭代操作,為每個批處理呼叫一次訓練函式,並且設定了在一定的迭代訓練次數之後評估一下我們的訓練模型。
通過將權重更新和網路層操作的結果都儲存起來,最後在 TensorBoard 中進行視覺化。
對應程式碼:train.py
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import os
import time
import datetime
import loadData
from AlexNet import CNN
# Parameters
# ==================================================
# Model Hyperparameters
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)")
tf.flags.DEFINE_float("l2_reg_lambda", 0.01, "L2 regularization lambda (default: 0.01)")
# Training parameters
tf.flags.DEFINE_integer("batch_size", 40, "Batch Size (default: 30)")
tf.flags.DEFINE_integer("num_epochs", 80, "Number of training epochs (default: 20)")
tf.flags.DEFINE_integer("evaluate_every", 30, "Evaluate model on dev set after this many steps (default: 20)")
tf.flags.DEFINE_integer("checkpoint_every", 30, "Save model after this many steps (default: 20)")
tf.flags.DEFINE_integer("num_checkpoints",5, "Number of checkpoints to store (default: 5)")
# Misc Parameters
tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement")
tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices")
FLAGS = tf.flags.FLAGS
FLAGS._parse_flags()
print("\nParameters:")
for attr, value in sorted(FLAGS.__flags.items()):
print("{}={}".format(attr.upper(), value))
print("")
# Load data
train_x, train_y, test_x, test_y = loadData.get_input()
print("Train/Test: {:d}/{:d}".format(len(train_y), len(test_y)))
# Training
# ==================================================
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement)
sess = tf.Session(config=session_conf)
with sess.as_default():
cnn =CNN(
num_classes=17,
l2_reg_lambda=FLAGS.l2_reg_lambda)
# Define Training procedure
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(1e-4)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and accuracy
loss_summary = tf.summary.scalar("loss", cnn.loss)
acc_summary = tf.summary.scalar("accuracy", cnn.accuracy)
# Train Summaries
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
# Test summaries
test_summary_op = tf.summary.merge([loss_summary, acc_summary])
test_summary_dir = os.path.join(out_dir, "summaries", "test")
test_summary_writer = tf.summary.FileWriter(test_summary_dir, sess.graph)
# Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
# Initialize all variables
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
"""
A single training step
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
def test_step(x_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: 1.0
}
step, summaries, loss, accuracy = sess.run(
[global_step, test_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(summaries, step)
# Generate batches
batches =loadData.batch_iter(
list(zip(train_x,train_y)), FLAGS.batch_size, FLAGS.num_epochs)
# Training loop. For each batch...
for batch in batches:
x_batch, y_batch = zip(*batch)
train_step(x_batch, y_batch)
current_step = tf.train.global_step(sess, global_step)
if current_step % FLAGS.evaluate_every == 0:
print("\nEvaluation:")
test_step(test_x, test_y, writer=test_summary_writer)
print("")
if current_step % FLAGS.checkpoint_every == 0:
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))四、實驗結果
通過以上的訓練,我們得到了最終結果的準確率大概在70%左右。具體的acurracy和loss走勢可見如下使用TensorbBoard生成訓練時記錄下的資料的視覺化圖。
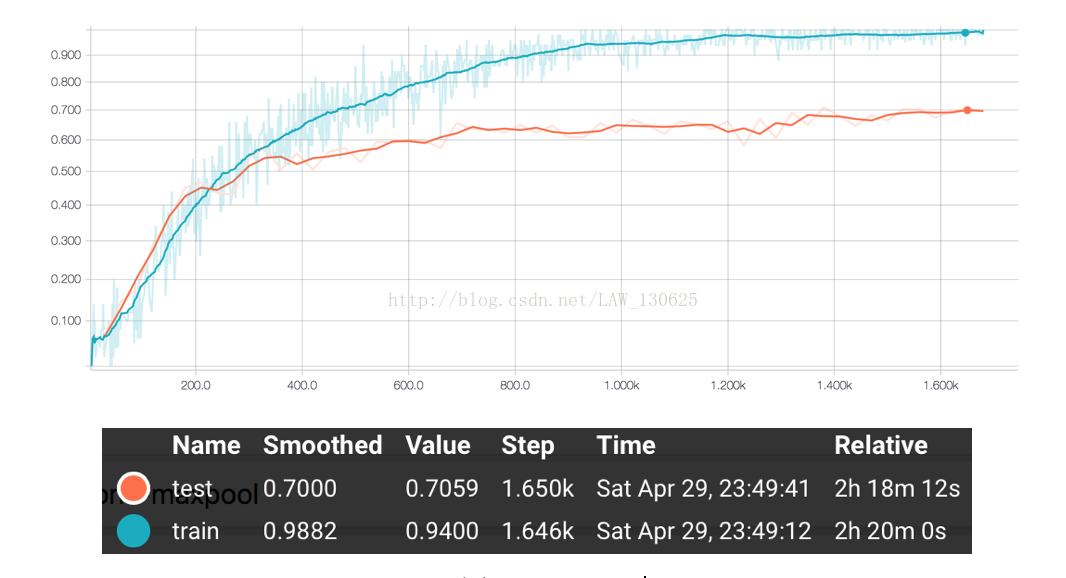
圖2 accuracy
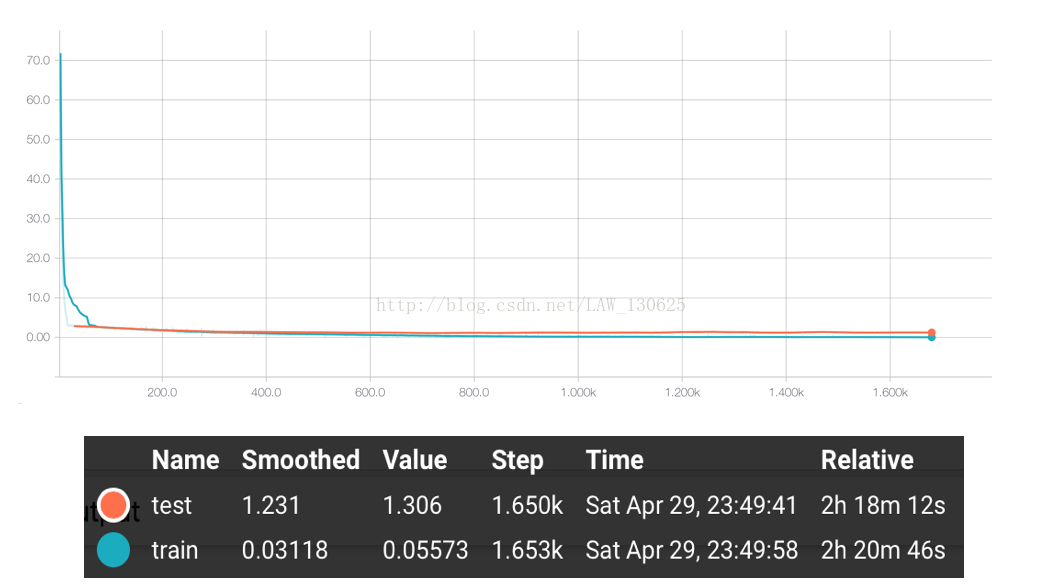
五、一些思考
本次實驗的最好結果只有70.59%左右,並沒有表現出AlexNet的強悍能力,綜合分析主要有以下幾個原因:
①觀察上面圖2的accuracy可以發現,在正確率上,前100個step中,測試集的效果比訓練集的效果要好,但是之後測試集表現逐漸平緩,而訓練集的效果繼續逐漸上升,最後接近於1,所以可以推斷最後模型出現了一定的過擬合,主要原因是AlexNet模型擬合能力強,而本次實驗資料較為少,訓練資料集只有1020個樣本,所以模型出現了過擬合;
②在劃分資料集上,可能存在個別類別的訓練樣本非常的少,所以難以訓練出表現該型別的模型,自然而然模型效果也就差強人意;
③由於採用的是筆記本CPU進行訓練模型,所以訓練過程比較緩慢,因而基本沒有進行太多的調參工作,如果仔細調參,模型應該還有上升的空間。