Tensorflow實現卷積神經網路,用於人臉關鍵點識別
今年來人工智慧的概念越來越火,AlphaGo以4:1擊敗李世石更是起到推波助瀾的作用。作為一個開挖掘機的菜鳥,深深感到不學習一下deep learning早晚要被淘汰。
既然要開始學,當然是搭一個深度神經網路跑幾個資料集感受一下作為入門最直觀了。自己寫程式碼實現的話debug的過程和執行效率都會很憂傷,我也不知道怎麼呼叫GPU… 所以還是站在巨人的肩膀上,用現成的框架吧。粗略瞭解一下,現在比較知名的有caffe、mxnet、tensorflow等等。選哪個呢?對我來說選擇的標準就兩個,第一要容易安裝(想盡快入門的迫切心情實在難以忍受一大堆的配置安裝…);第二文件要齊全(這應該是廢話 - -)。這幾個大名鼎鼎的框架文件都是比較齊全的,那就看最容易安裝的。看了幾個文件,tensorflow算是最容易安裝的了。基本就是pip intall 給定的URL
tensorflow基本概念與用法
tensorflow直譯過來就是張量流。去年google剛推出tensorflow的時候我就納悶,為什麼深度學習會牽扯到張量,以前學彈塑性力學的時候就是一大堆張量看的很煩…不過還好要理解tensorflow裡的tensor完全不用理會那些。先來看一下官方文件的說明:
class tf.Tensor
Represents a value produced by an Operation.
A Tensor is a symbolic handle to one of the outputs of an Operation. It does not hold the values of that operation’s output, but instead provides a means of computing those values in a TensorFlow Session.
首先,Tensor代表了執行一個操作(運算)所產生的值。其次,一個Tensor例項並不會儲存具體的值,而只是代表了產生這些值的運算方式。好像有些拗口,也就是說假如有一個加法操作add,令c = add(1,1)。那麼c就是一個tensor例項了,代表了1+1的結果,但是它並沒有儲存2這個具體的值,它只知道它代表1+1這個運算。從這裡也可以看出,tensorflow裡的api都是惰性求值,等真正需要知道具體的值的時候,才會執行計算,其他時候都是在定義計算的過程。
Tensor可以代表從常數一直到N維陣列的值。
Flow指的是,指的是tensorflow這套框架裡的資料傳遞全部都是tensor,也就是運算的輸入,輸出都是tensor。
常用操作
這裡只是簡單介紹一下在後面定義卷積神經網路的時候會用到的東西。想要了解更詳細的內容還得參考官網上的文件。
首先import tensorflow as tf,後面的tf就代表tensorflow啦。
常數
tf.constant 是一個Operation,用來產生常數,可以產生scalar與N-D array. a是一個tensor,代表了由constant這個Operation所產生的標量常數值的過程。 b就是代表了產生一個2*2的array的過程。
a = tf.constant(3)
b = tf.constant(3,shape=[2,2])
變數
變數代表了神經網路中的引數,在優化計算的過程中需要被改變。tf.Variable當然也是一個Operation,用來產生一個變數,建構函式需要傳入一個Tensor物件,傳入的這個Tensor物件就決定了這個變數的值的型別(float 或 int)與shape。
變數雖然與Tensor有不同的型別,但是在計算過程中是與Tensor一樣可以作為輸入輸出的。(可以理解為Tensor的派生類,但是實際上可能並不是這樣,我還沒有看原始碼)
變數在使用前都必須初始化。
w = tf.Variable(b)
Operation
其實Operation不應該單獨拿出來說,因為之前的tf.constant和tf.Variable都是Op,不過還是說一下常規的操作,比如tf.matmul執行矩陣計算,tf.conv2d用於卷積計算,Op的詳細用法以及其他的Op可以參考api文件。
tf.matmul(m,n)
tf.conv2d(...)
TensorFlow的計算由不同的Operation組成,比如下圖

定義了6*(3+5)這個計算過程。6、3、5其實也是Op,這在前面介紹過了。
卷積神經網路用於人臉關鍵點識別
寫到這裡終於要開始進入正題了,先從CNN做起吧。Tensorflow的tutorial裡面有介紹用CNN(卷積神經網路)來識別手寫數字,直接把那裡的程式碼copy下來跑一遍也是可以的。但是那比較沒有意思,kaggle上有一個人臉關鍵點識別的比賽,有資料集也比較有意思,就拿這個來練手了。
定義卷積神經網路
首先是定義網路結構,在這個例子裡我用了3個卷積層,第一個卷積層用
產生權值的函式程式碼如下
#根據給定的shape定義並初始化卷積核的權值變數
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
#根據shape初始化bias變數
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
定義卷積運算的程式碼如下。對tf.nn.con2d()的引數還是要說明一下
1. x是輸入的樣本,在這裡就是影象。x的shape=[batch, height, width, channels]。
- batch是輸入樣本的數量
- height, width是每張影象的高和寬
- channels是輸入的通道,比如初始輸入的影象是灰度圖,那麼channels=1,如果是rgb,那麼channels=3。對於第二層卷積層,channels=32。
2. W表示卷積核的引數,shape的含義是[height,width,in_channels,out_channels]。
3. strides引數表示的是卷積核在輸入x的各個維度下移動的步長。瞭解CNN的都知道,在寬和高方向stride的大小決定了卷積後圖像的size。這裡為什麼有4個維度呢?因為strides對應的是輸入x的維度,所以strides第一個引數表示在batch方向移動的步長,第四個引數表示在channels上移動的步長,這兩個引數都設定為1就好。重點就是第二個,第三個引數的意義,也就是在height於width方向上的步長,這裡也都設定為1。
4. padding引數用來控制圖片的邊距,’SAME’表示卷積後的圖片與原圖片大小相同,’VALID’的話卷積以後影象的高為
def conv2d(x,W):
return tf.nn.cov2d(x,W,strides=[1,1,1,1],padding='VALID')接著是定義池化層的程式碼,這裡用ksize定義pool視窗的大小,每個維度的意義與之前的strides相同,所以實際上我們設定第二個,第三個維度就可以了。
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')定義好產生權重、卷積、池化的函式以後就要開始組裝這個卷積神經網路了。定義之前再定義一下輸入樣本x與對應的目標值y_。這裡用了tf.placeholder表示此時的x與y_是指定shape的站位符,之後在定義網路結構的時候並不需要真的輸入了具體的樣本,只要在求值的時候feed進去就可以了。啟用函式用relu,api也就是tf.nn.relu。
keep_prob是最後dropout的引數,dropout的目的是為了抗過擬合。
rmse是損失函式,因為這裡的目的是為了檢測人臉關鍵點的位置,是迴歸問題,所以用root-mean-square-error。並且最後的輸出層不需要套softmax,直接輸出y值就可以了。
這樣就組裝好了一個卷積神經網路。後續的步驟就是根據輸入樣本來train這些引數啦。
x = tf.placeholder("float", shape=[None, 96, 96, 1])
y_ = tf.placeholder("float", shape=[None, 30])
keep_prob = tf.placeholder("float")
def model():
W_conv1 = weight_variable([3, 3, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([2, 2, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_conv3 = weight_variable([2, 2, 64, 128])
b_conv3 = bias_variable([128])
h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3)
h_pool3 = max_pool_2x2(h_conv3)
W_fc1 = weight_variable([11 * 11 * 128, 500])
b_fc1 = bias_variable([500])
h_pool3_flat = tf.reshape(h_pool3, [-1, 11 * 11 * 128])
h_fc1 = tf.nn.relu(tf.matmul(h_pool3_flat, W_fc1) + b_fc1)
W_fc2 = weight_variable([500, 500])
b_fc2 = bias_variable([500])
h_fc2 = tf.nn.relu(tf.matmul(h_fc1, W_fc2) + b_fc2)
h_fc2_drop = tf.nn.dropout(h_fc2, keep_prob)
W_fc3 = weight_variable([500, 30])
b_fc3 = bias_variable([30])
y_conv = tf.matmul(h_fc2_drop, W_fc3) + b_fc3
rmse = tf.sqrt(tf.reduce_mean(tf.square(y_ - y_conv)))
return y_conv, rmse訓練卷積神經網路
讀取訓練資料
定義好卷積神經網路的結構之後,就要開始訓練。訓練首先是要讀取訓練樣本。下面的程式碼用於讀取樣本。
import pandas as pd
import numpy as np
TRAIN_FILE = 'training.csv'
TEST_FILE = 'test.csv'
SAVE_PATH = 'model'
VALIDATION_SIZE = 100 #驗證集大小
EPOCHS = 100 #迭代次數
BATCH_SIZE = 64 #每個batch大小,稍微大一點的batch會更穩定
EARLY_STOP_PATIENCE = 10 #控制early stopping的引數
def input_data(test=False):
file_name = TEST_FILE if test else TRAIN_FILE
df = pd.read_csv(file_name)
cols = df.columns[:-1]
#dropna()是丟棄有缺失資料的樣本,這樣最後7000多個樣本只剩2140個可用的。
df = df.dropna()
df['Image'] = df['Image'].apply(lambda img: np.fromstring(img, sep=' ') / 255.0)
X = np.vstack(df['Image'])
X = X.reshape((-1,96,96,1))
if test:
y = None
else:
y = df[cols].values / 96.0 #將y值縮放到[0,1]區間
return X, y
#最後生成提交結果的時候要用到
keypoint_index = {
'left_eye_center_x':0,
'left_eye_center_y':1,
'right_eye_center_x':2,
'right_eye_center_y':3,
'left_eye_inner_corner_x':4,
'left_eye_inner_corner_y':5,
'left_eye_outer_corner_x':6,
'left_eye_outer_corner_y':7,
'right_eye_inner_corner_x':8,
'right_eye_inner_corner_y':9,
'right_eye_outer_corner_x':10,
'right_eye_outer_corner_y':11,
'left_eyebrow_inner_end_x':12,
'left_eyebrow_inner_end_y':13,
'left_eyebrow_outer_end_x':14,
'left_eyebrow_outer_end_y':15,
'right_eyebrow_inner_end_x':16,
'right_eyebrow_inner_end_y':17,
'right_eyebrow_outer_end_x':18,
'right_eyebrow_outer_end_y':19,
'nose_tip_x':20,
'nose_tip_y':21,
'mouth_left_corner_x':22,
'mouth_left_corner_y':23,
'mouth_right_corner_x':24,
'mouth_right_corner_y':25,
'mouth_center_top_lip_x':26,
'mouth_center_top_lip_y':27,
'mouth_center_bottom_lip_x':28,
'mouth_center_bottom_lip_y':29
}
開始訓練
執行訓練的程式碼如下,save_model用於儲存當前訓練得到在驗證集上loss最小的模型,方便以後直接拿來用。
tf.InteractiveSession()用來生成一個Session,(好像是廢話…)。Session相當於一個引擎,TensorFlow框架要真正的進行計算,都要通過Session引擎來啟動。
tf.train.AdamOptimizer是優化的演算法,Adam的收斂速度會比較快,1e-3是learning rate,這裡先簡單的用固定的。minimize就是要最小化的目標,當然是最小化均方根誤差了。
def save_model(saver,sess,save_path):
path = saver.save(sess, save_path)
print 'model save in :{0}'.format(path)
if __name__ == '__main__':
sess = tf.InteractiveSession()
y_conv, rmse = model()
train_step = tf.train.AdamOptimizer(1e-3).minimize(rmse)
#變數都要初始化
sess.run(tf.initialize_all_variables())
X,y = input_data()
X_valid, y_valid = X[:VALIDATION_SIZE], y[:VALIDATION_SIZE]
X_train, y_train = X[VALIDATION_SIZE:], y[VALIDATION_SIZE:]
best_validation_loss = 1000000.0
current_epoch = 0
TRAIN_SIZE = X_train.shape[0]
train_index = range(TRAIN_SIZE)
random.shuffle(train_index)
X_train, y_train = X_train[train_index], y_train[train_index]
saver = tf.train.Saver()
print 'begin training..., train dataset size:{0}'.format(TRAIN_SIZE)
for i in xrange(EPOCHS):
random.shuffle(train_index) #每個epoch都shuffle一下效果更好
X_train, y_train = X_train[train_index], y_train[train_index]
for j in xrange(0,TRAIN_SIZE,BATCH_SIZE):
print 'epoch {0}, train {1} samples done...'.format(i,j)
train_step.run(feed_dict={x:X_train[j:j+BATCH_SIZE],
y_:y_train[j:j+BATCH_SIZE], keep_prob:0.5})
#電腦太渣,用所有訓練樣本計算train_loss居然宕機,只好註釋了。
#train_loss = rmse.eval(feed_dict={x:X_train, y_:y_train, keep_prob: 1.0})
validation_loss = rmse.eval(feed_dict={x:X_valid, y_:y_valid, keep_prob: 1.0})
print 'epoch {0} done! validation loss:{1}'.format(i, validation_loss*96.0)
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
current_epoch = i
save_model(saver,sess,SAVE_PATH) #即時儲存最好的結果
elif (i - current_epoch) >= EARLY_STOP_PATIENCE:
print 'early stopping'
break
在測試集上預測
下面的程式碼用於預測test.csv裡面的人臉關鍵點,最後的y值要乘以96,因為之前縮放到[0,1]區間了。
X,y = input_data(test=True)
y_pred = []
TEST_SIZE = X.shape[0]
for j in xrange(0,TEST_SIZE,BATCH_SIZE):
y_batch = y_conv.eval(feed_dict={x:X[j:j+BATCH_SIZE], keep_prob:1.0})
y_pred.extend(y_batch)
print 'predict test image done!'
output_file = open('submit.csv','w')
output_file.write('RowId,Location\n')
IdLookupTable = open('IdLookupTable.csv')
IdLookupTable.readline()
for line in IdLookupTable:
RowId,ImageId,FeatureName = line.rstrip().split(',')
image_index = int(ImageId) - 1
feature_index = keypoint_index[FeatureName]
feature_location = y_pred[image_index][feature_index] * 96
output_file.write('{0},{1}\n'.format(RowId,feature_location))
output_file.close()
IdLookupTable.close()結果
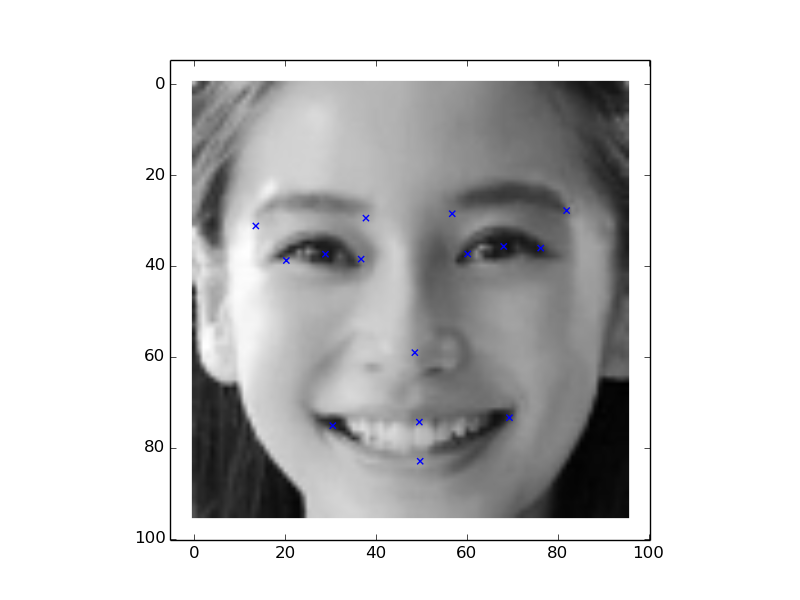
用這個結構的卷積神經網路訓練出來的模型,在測試集上預測的結果提交以後的成績是3.4144,在kaggle的leaderboard上是41名,初試CNN,感覺還可以了。這只是資料,還是找一些現實的照片來試試這個模型如何,所以我找了一張anglababy的,標識出來的關鍵點感覺還算靠譜。基於TensorFlow的卷積神經網路先寫到這了,有什麼遺漏的想起來再補充,之後對深度學習更瞭解了,再寫寫CNN的原理,bp的推導過程之類的。