
影象分類資料集(Fashion-MNIST)
1、獲取資料集
這也是我第一次接觸到影象分類問題,在jupyter notebook上實現之後,還想把它寫在部落格上,為了紀念一下吧! 首先對於原著的敬意,那肯定是要分享連結http://zh.gluon.ai/的啦!
1.1 獲取資料集
首先匯入需要的包和模組
In [1]: %matplotlib inline
import gluonbook as gb
from mxnet.gluon import data as gdata
import sys
import time
下⾯,我們通過Gluon 的data 包來下載這個資料集。第⼀次調⽤時會⾃動從⽹上獲取資料。我們通過引數train 來指定獲取訓練資料集或測試資料集(testing data set)。測試資料集也叫測試集(testing set),只⽤來評價模型的表現,並不⽤來訓練模型。
In [2]: mnist_train = gdata.vision.FashionMNIST(train=True)
mnist_test = gdata.vision.FashionMNIST(train=False)
訓練集中和測試集中的每個類別的影象數分別為6,000 和1,000。因為有10 個類別,所以訓練集和測試集的樣本數分別為60,000 和10,000。
In [3]: len(mnist_train), len(mnist_test)
Out[3]: (60000, 10000)
我們可以通過⽅括號[ ]來訪問任意⼀個樣本,下⾯獲取第⼀個樣本的影象和標籤。
In [4]: feature, label = mnist_train[0]
變數feature 對應⾼和寬均為28 畫素的影象。每個畫素的數值為0 到255 之間8 位⽆符號整
數(uint8)。它使⽤3 維的NDArray 儲存。其中的最後⼀維是通道數。因為資料集中是灰度影象,所以通道數為1。為了表述簡潔,我們將⾼和寬分別為h 和w 畫素的影象的形狀記為h × w 或(h,w)。
In [5]: feature.shape, feature.dtype
Out[5]: ((28, 28, 1), numpy.uint8)
影象的標籤使⽤NumPy 的標量表⽰。它的型別為32 位整數。
In [6]: label, type(label), label.dtype Out[6]: (2, numpy.int32, dtype('int32'))
Fashion-MNIST 是⼀個10 類服飾分類資料集。Fashion-MNIST 中⼀共包括了10 個類別,分別為:t-shirt(T 恤)、trouser(褲⼦)、pullover(套衫)、dress(連⾐裙)、coat(外套)、sandal(涼鞋)、shirt(襯衫)、sneaker(運動鞋)、bag(包)和ankle boot(短靴)。以下函式可以將數值標籤轉成相應的⽂本標籤。
In [7]: # 本函式已儲存在gluonbook 包中⽅便以後使⽤。
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
下⾯定義⼀個可以在⼀⾏⾥畫出多張影象和對應標籤的函式。
In [8]: # 本函式已儲存在gluonbook 包中⽅便以後使⽤。
def show_fashion_mnist(images, labels):
gb.use_svg_display()
# 這⾥的_ 表⽰我們忽略(不使⽤)的變數。
_, figs = gb.plt.subplots(1, len(images), figsize=(12, 12))
for f, img, lbl in zip(figs, images, labels):
f.imshow(img.reshape((28, 28)).asnumpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
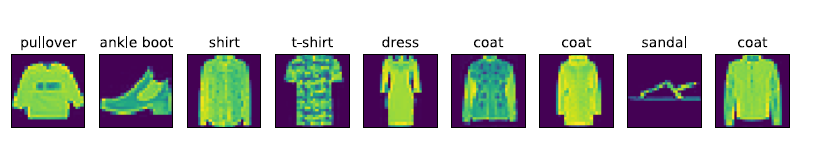
現在,我們看⼀下訓練資料集中前9 個樣本的影象內容和⽂本標籤。
In [9]: X, y = mnist_train[0:9]
show_fashion_mnist(X, get_fashion_mnist_labels(y))
1.2 讀取小批量
我們將在訓練資料集上訓練模型,並將訓練好的模型在測試資料集上評價模型的表現。雖然我
們可以像“線性迴歸的從零開始實現”⼀節中那樣通過yield 來定義讀取小批量資料樣本的
函式,但為了程式碼簡潔,這⾥我們直接建立DataLoader 例項。該例項每次讀取⼀個樣本數為
batch_size 的小批量資料。這⾥的批量⼤小batch_size 是⼀個超引數。
在實踐中,資料讀取經常是訓練的效能瓶頸,特別當模型較簡單或者計算硬體效能較⾼時。Gluon的DataLoader 中⼀個很⽅便的功能是允許使⽤多程序來加速資料讀取(暫不⽀持Windows作業系統)。這⾥我們通過引數num_workers 來設定4 個程序讀取資料。
此外,我們通過ToTensor 類將影象資料從uint8 格式變換成32 位浮點數格式,併除以255 使
得所有畫素的數值均在0 到1 之間。ToTensor 類還將影象通道從最後⼀維移到最前⼀維來⽅便
之後介紹的卷積神經⽹絡計算。通過資料集的transform_first 函式,我們將ToTensor 的
變換應⽤在每個資料樣本(影象和標籤)的第⼀個元素,即影象之上。
In [10]: batch_size = 256
transformer = gdata.vision.transforms.ToTensor()
if sys.platform.startswith('win'):
num_workers = 0 # 0 表⽰不⽤額外的程序來加速讀取資料。
else:
num_workers = 4
train_iter = gdata.DataLoader(mnist_train.transform_first(transformer),
batch_size, shuffle=True,
num_workers=num_workers)
test_iter = gdata.DataLoader(mnist_test.transform_first(transformer),
batch_size, shuffle=False,
num_workers=num_workers)
我們將獲取並讀取Fashion-MNIST 資料集的邏輯封裝在gluonbook.load_data_fashion_mnist 函式中供後⾯章節調⽤。該函式將返回train_iter 和test_iter 兩個變數。隨著本書內容的不斷深⼊,我們會進⼀步改進該函式。它的完整實現將在“深度卷積神經⽹絡(AlexNet)”⼀節中描述。
最後我們檢視讀取⼀遍訓練資料需要的時間。
In [11]: start = time.time()
for X, y in train_iter:
continue
'%.2f sec' % (time.time() - start)
Out[11]: '1.09 sec'
2、Softmax 迴歸的從零開始實現
這⼀節我們來動⼿實現Softmax 迴歸。⾸先導⼊本節實現所需的包或模組。
In [1]: %matplotlib inline
import gluonbook as gb
from mxnet import autograd, nd
2.1 獲取和讀取資料
我們將使⽤Fashion-MNIST 資料集,並設定批量⼤小為256。
In [2]: batch_size = 256
train_iter, test_iter = gb.load_data_fashion_mnist(batch_size)
2.2 初始化模型引數
跟線性迴歸中的例⼦⼀樣,我們將使⽤向量表⽰每個樣本。已知每個樣本輸⼊是⾼和寬均為28
畫素的影象。模型的輸⼊向量的⻓度是28 × 28 = 784:該向量的每個元素對應影象中每個畫素。
由於影象有10 個類別,單層神經⽹絡輸出層的輸出個數為10。所以Softmax 迴歸的權重和偏差
引數分別為784 × 10 和1 × 10 的矩陣。
In [3]: num_inputs = 784
num_outputs = 10
W = nd.random.normal(scale=0.01, shape=(num_inputs, num_outputs))
b = nd.zeros(num_outputs)
同之前⼀樣,我們要對模型引數附上梯度。
In [4]: W.attach_grad()
b.attach_grad()
2.3 實現Softmax 運算
在介紹如何定義Softmax 迴歸之前,我們先描述⼀下對如何對多維NDArray 按維度操作。在下⾯
例⼦中,給定⼀個NDArray 矩陣X。我們可以只對其中同⼀列(axis=0)或同⼀⾏(axis=1)
的元素求和,並在結果中保留⾏和列這兩個維度(keepdims=True)。
In [5]: X = nd.array([[1, 2, 3], [4, 5, 6]])
X.sum(axis=0, keepdims=True), X.sum(axis=1, keepdims=True)
Out[5]: (
[[5. 7. 9.]]
<NDArray 1x3 @cpu(0)>,
[[ 6.]
[15.]]
<NDArray 2x1 @cpu(0)>)
下⾯我們就可以定義前⾯小節⾥介紹的softmax 運算了。在下⾯的函式中,矩陣X 的⾏數是樣
本數,列數是輸出個數。為了表達樣本預測各個輸出的概率,softmax 運算會先通過exp 函式對
每個元素做指數運算,再對exp 矩陣同⾏元素求和,最後令矩陣每⾏各元素與該⾏元素之和相
除。這樣⼀來,最終得到的矩陣每⾏元素和為1 且⾮負。因此,該矩陣每⾏都是合法的概率分佈。
Softmax 運算的輸出矩陣中的任意⼀⾏元素代表了⼀個樣本在各個輸出類別上的預測概率。
In [6]: def softmax(X):
X_exp = X.exp()
partition = X_exp.sum(axis=1, keepdims=True)
return X_exp / partition # 這⾥應⽤了⼴播機制。
可以看到,對於隨機輸⼊,我們將每個元素變成了⾮負數,且每⼀⾏和為1。
In [7]: X = nd.random.normal(shape=(2, 5))
X_prob = softmax(X)
X_prob, X_prob.sum(axis=1)
Out[7]: (
[[0.21324193 0.33961776 0.1239742 0.27106097 0.05210521]
[0.11462264 0.3461234 0.19401033 0.29583326 0.04941036]]
<NDArray 2x5 @cpu(0)>,
[1.0000001 1. ]
<NDArray 2 @cpu(0)>)
2.4 定義模型
有了softmax 運算,我們可以定義上節描述的softmax 迴歸模型了。這⾥通過reshape 函式將
每張原始影象改成⻓度為num_inputs 的向量。
In [8]: def net(X):
return softmax(nd.dot(X.reshape((-1, num_inputs)), W) + b)
2.5 定義損失函式
上⼀節中,我們介紹了softmax 迴歸使⽤的交叉熵損失函式。為了得到標籤的預測概率,我們可
以使⽤pick 函式。在下⾯例⼦中,變數y_hat 是2 個樣本在3 個類別的預測概率,變數y
是這2 個樣本的標籤類別。通過使⽤pick 函式,我們得到了2 個樣本的標籤的預測概率。與
“Softmax 迴歸”⼀節數學表述中標籤類別離散值從1 開始逐⼀遞增不同,在程式碼中,標籤類別的
離散值是從0 開始逐⼀遞增的。
In [9]: y_hat = nd.array([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y = nd.array([0, 2])
nd.pick(y_hat, y)
Out[9]:
[0.1 0.5]
<NDArray 2 @cpu(0)>
以下實現了“Softmax 迴歸”⼀節中介紹的交叉熵損失函式。
In [10]: def cross_entropy(y_hat, y):
return - nd.pick(y_hat, y).log()
2.6 計算分類準確率
給定⼀個類別的預測概率分佈y_hat,我們把預測概率最⼤的類別作為輸出類別。如果它與真
實類別y ⼀致,說明這次預測是正確的。分類準確率即正確預測數量與總預測數量之⽐。
下⾯定義準確率accuracy 函式。其中y_hat.argmax(axis=1) 返回矩陣y_hat 每⾏中最
⼤元素的索引,且返回結果與變數y 形狀相同。我們在“資料操作”⼀節介紹過,相等條件判斷
式(y_hat.argmax(axis=1) == y) 是⼀個值為0(相等為假)或1(相等為真)的NDArray。
由於標籤型別為整數,我們先將變數y 變換為浮點數再進⾏相等條件判斷。
In [11]: # 本函式已儲存在gluonbook 包中⽅便以後使⽤。
def accuracy(y_hat, y):
return (y_hat.argmax(axis=1) == y.astype('float32')).mean().asscalar()
讓我們繼續使⽤在演⽰pick 函式時定義的變數y_hat 和y,並將它們分別作為預測概率分
布和標籤。可以看到,第⼀個樣本預測類別為2(該⾏最⼤元素0.6 在本⾏的索引為2),與真實
標籤0 不⼀致;第⼆個樣本預測類別為2(該⾏最⼤元素0.5 在本⾏的索引為2),與真實標籤2
⼀致。因此,這兩個樣本上的分類準確率為0.5。
In [12]: accuracy(y_hat, y)
Out[12]: 0.5
類似地,我們可以評價模型net 在資料集data_iter 上的準確率。
In [13]: # 本函式已儲存在gluonbook 包中⽅便以後使⽤。該函式將被逐步改進:它的完整實現將在“影象增⼴”⼀節中描述。
def evaluate_accuracy(data_iter, net):
acc = 0
for X, y in data_iter:
acc += accuracy(net(X), y)
return acc / len(data_iter)
因為我們隨機初始化了模型net,所以這個隨機模型的準確率應該接近於類別個數10 的倒數
0.1。
In [14]: evaluate_accuracy(test_iter, net)
Out[14]: 0.0947265625
2.7 訓練模型
訓練softmax 迴歸的實現跟前⾯介紹的線性迴歸中的實現⾮常相似。我們同樣使⽤小批量隨機梯
度下降來優化模型的損失函式。在訓練模型時,迭代週期數num_epochs 和學習率lr 都是可
以調的超引數。改變它們的值可能會得到分類更準確的模型。
In [15]: num_epochs, lr = 5, 0.1
# 本函式已儲存在gluonbook 包中⽅便以後使⽤。
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
params=None, lr=None, trainer=None):
for epoch in range(num_epochs):
train_l_sum = 0
train_acc_sum = 0
for X, y in train_iter:
with autograd.record():
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
if trainer is None:
gb.sgd(params, lr, batch_size)
else:
trainer.step(batch_size) # 下⼀節將⽤到。
train_l_sum += l.mean().asscalar()
train_acc_sum += accuracy(y_hat, y)
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / len(train_iter),
train_acc_sum / len(train_iter), test_acc))
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs,
batch_size, [W, b], lr)
Out [15]: epoch 1, loss 0.7867, train acc 0.749, test acc 0.798
epoch 2, loss 0.5744, train acc 0.810, test acc 0.825
epoch 3, loss 0.5295, train acc 0.822, test acc 0.831
epoch 4, loss 0.5049, train acc 0.831, test acc 0.830
epoch 5, loss 0.4903, train acc 0.834, test acc 0.838
2.8 預測
訓練完成後,現在我們可以演⽰如何對影象進⾏分類。給定⼀系列影象(第三⾏影象輸出),我
們⽐較⼀下它們的真實標籤(第⼀⾏⽂本輸出)和模型預測結果(第⼆⾏⽂本輸出)。
In [16]: for X, y in test_iter:
break
true_labels = gb.get_fashion_mnist_labels(y.asnumpy())
pred_labels = gb.get_fashion_mnist_labels(net(X).argmax(axis=1).asnumpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]
gb.show_fashion_mnist(X[0:9], titles[0:9])
