Polygon-RNN++ ( 影象分割資料集自動標註)
一、Polygon-RNN整體架構

- 使用了CNN(卷積神經網路)提取影象特徵。
- 使用RNN(迴圈神經網路)解碼多邊形頂點。為了提高RNN的預測效果。
- 加入了注意力機制(attention)。
- 同時使用評估網路(evaluator network)從RNN提議的候選多邊形中選出最佳。
- 最後使用門控圖神經網路(Gated Graph Neural Network,GGNN)上取樣,以提高輸出解析度。
1.1 CNN部分
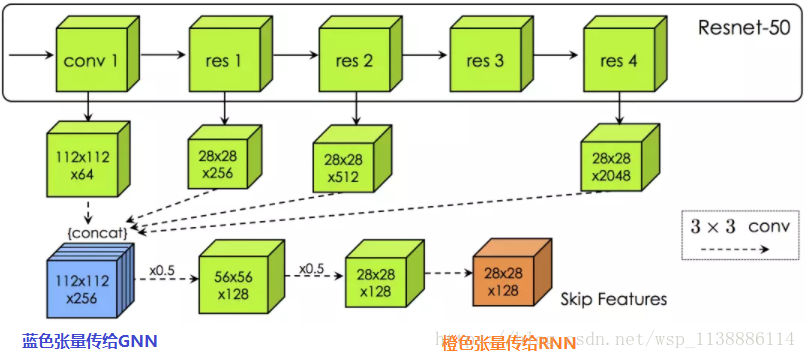
CNN部分,借鑑了ResNet-50的做法,減少步長(stride),引入空洞卷積(dilation)
1.2 RNN部分
RNN部分,使用了雙層 ConvLTSM(3x3核,64/16通道,每時步應用歸一化),以保留空間資訊、降低引數數量。網路的輸出為(D x D) + 1元素的獨熱編碼。前D x D維表示可能的頂點位置(論文的試驗中D = 28),而最後一個維度標誌多邊形的終點。
為了提升RNN部分的表現,加入了(attention)注意力機制。具體來說,在時步
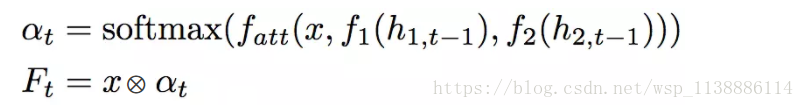
上式中, 為跳躍特徵張量, 為隱藏狀態張量,使用一個全連線層將 ; 對映至。 累加輸入之和,通過一個全連線層將其對映至DxD。 為 Hadamard product。直觀地說,attention 使用之前的 RNN 隱藏狀態控制影象特徵對映中的特定位置,使RNN在下一時步僅僅關注相關資訊。
另外,第一個頂點需要特別處理。因為,給定多邊形之前的頂點和一個隱式的方向,下一個頂點的位置總是確定的,除了第一個頂點。因此,研究人員增加了一個包含兩個DxD維網路層的分支,讓第一層預測邊,第二層預測頂點。測試時,第一個頂點取樣自該分支的最後一層。
第一個頂點的選擇很關鍵,特別是在有遮擋的情況下。傳統的集束搜尋基於對數概率,因此不適用於Polygon-RNN++(在遮擋邊界上的點一般在預測時會有很高的對數概率,減少了它被集束搜尋移除的機會)。因此,Polygon-RNN++使用了一個由兩個3x3卷積層加上一個全連線層組成的評估網路:
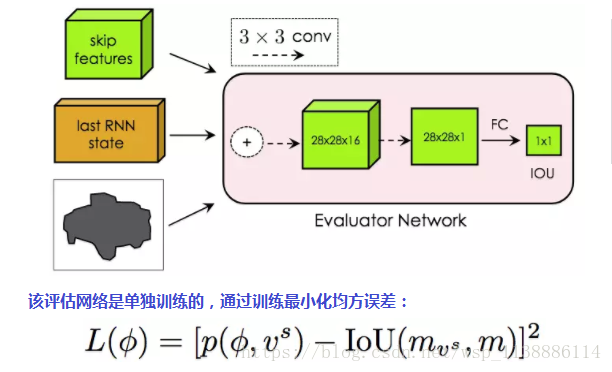
上式中,p為網路的預測IoU,mvs和m分別為預測掩碼、實際掩碼。
在測試時,基於評分前K的第一個頂點預測通過經典集束搜尋(對數概率,束寬為B)生成多邊形。對應K個第一個頂點,共有K個多邊形,然後讓評估網路從中選出最優多邊形。在論文的試驗中,K = 5. 之所以首先使用集束搜尋,而不是完全使用評估網路,是因為後者會導致推理時間過長。在B = K = 1的設定下,結合集束搜尋和評估網路的配置,可以達到295ms每物體的速度(Titan XP)。
與人互動時,人工糾正會傳回模型,讓模型重新預測多邊形的剩餘頂點。
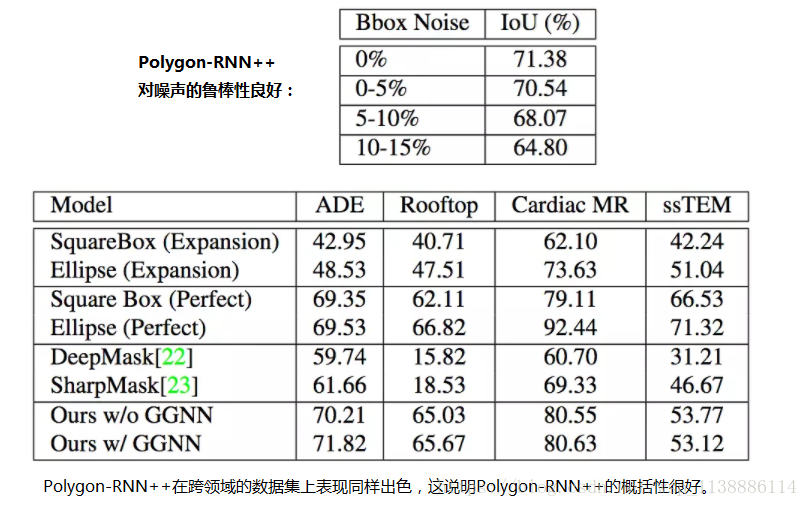
如前所述,RNN輸出的D x D維的多邊形,D取28. 之所以不取更大的D,是為了避免超出記憶體的限制。為了增加最終的輸出解析度,Polygon-RNN++使用了門控圖神經網路進行上取樣,將頂點視作圖的節點,並在相鄰節點中間增加節點。

上式中,V為圖的節點集,xv為節點v的初始狀態,hvt為節點v在時步t的隱藏狀態。矩陣A ∈ R|V|x2N|V|決定節點如何互相傳遞資訊,其中N表示邊的型別數。在試驗中使用了256維GRU,傳播步數T = 5。
節點v的輸出定義為:
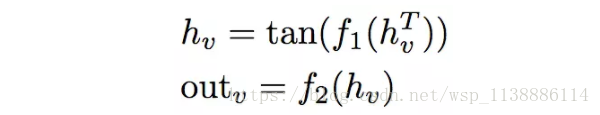
如前所述,CNN部分112 x 112 x 256的特徵對映(藍色張量)傳給GGNN。在圖中的每個節點v周圍(拉伸後),提取一個S x S塊,得到向量 ,提供給GGNN。在傳播過程之後,預測節點v的輸出,即D’ x D’空間網格上的位置。該網格以原位置 為參照,因此該預測任務其實是一個相對放置問題,並且可以視作分類問題,並基於交叉熵損失訓練。訓練的標準答案(ground truth)為RNN部分的輸出,如果預測和標準答案中的節點的差異超過閾值(試驗中為3格),則視為錯誤。
在試驗中,研究人員令S = 1,D’ = 112(研究人員發現更大的D’不能改善結果)。
二、基於強化學習訓練
Polygon-RNN基於交叉熵訓練。然而,基於交叉熵訓練有兩大侷限:
- MLE過度懲罰了模型。比如,預測的頂點雖然不是實際多邊形的頂點,但在實際多邊形的邊上。
- 優化的測度和最終評估測度(例如IoU)大不一樣。
另外,訓練過程中傳入下一時步的是實際多邊形而不是模型預測,這可能引入偏差,導致訓練和測試的不匹配。
為了緩解這些問題,Polygon-RNN++只在初始階段使用MLE訓練,之後通過強化學習訓練。因為使用強化學習,IoU不可微不再是問題了。
在強化學習的語境下,Polygon-RNN++的RNN解碼器可以視作序列決策智慧體。CNN和RNN架構的引數θ定義了選擇下一個頂點vt的策略pθ。在序列結束後,我們得到獎勵 。因此,最大化獎勵的損失函式為:
相應地,損失函式的梯度為: 實踐中常採用蒙特卡洛取樣計算期望梯度。但是這一方法方差很大,而且在未經恰當地基於情境歸一化的情況下非常不穩定。因此,Polygon-RNN++採用了自我批判(self-critical)方法,使用模型的測試階段推理獎勵作為基線: 另外,為了控制模型探索的隨機性,Polygon-RNN++還在策略softmax中引入了溫度引數 。試驗中, = 0.6.三、試驗結果
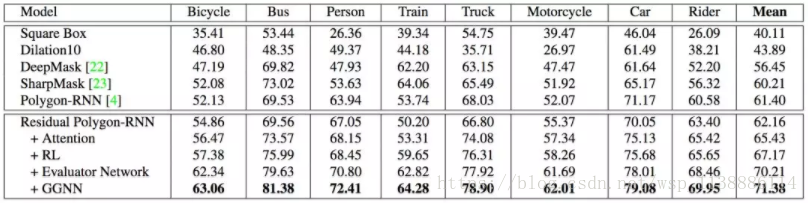
下圖展示了Polygon-RNN++在Cityscapes資料集上的結果。Cityscapes包含2975/500/1525張訓練/驗證/測試影象,共計8個語義分類。