
Hadoop1.x版本和Hadoop2.x版本架構原理
MapReduce 1.x 架構
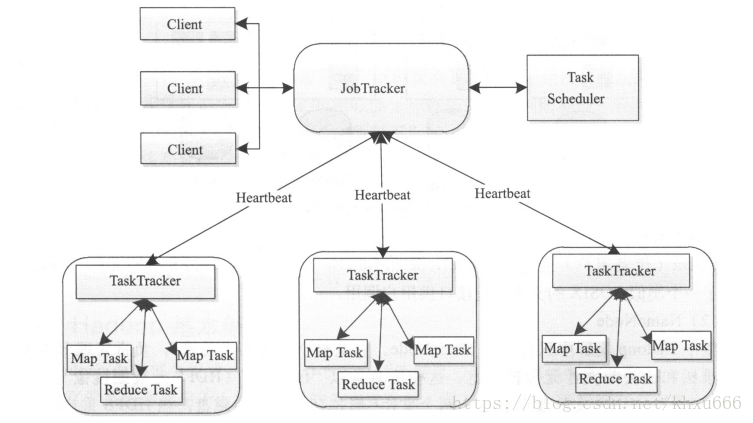
MapReduce 1.x 採用 Master/Slave 架構,由全域性唯一的 Jobtracker 和多個 TaskTacker 組成,並且在Client中提供一系列的api供程式設計和管理使用。
1.client
提供api供使用者程式設計呼叫,將使用者編寫的MapReduce程式提交到JobTracker中。
2. JobTracker
- 負責資源排程 主節點 發生故障整個叢集癱瘓
- 負責任務排程,主節點
存在的問題
負載過高,容易故障
與MR耦合度太高,如果Spark也要執行在這一框架上,需要自己去實現,這個叢集就存在兩套資源排程器,存在資源隔離問題以及資源掠奪問題。。
全域性唯一,主要負責叢集資源監控和作業排程。JobTracker會對叢集中所有的TaskTracker進行監控,一旦TaskTracker出現宕機、失敗等情況,JobTracker中的排程器會將原來在這個TaskTracker上面執行的任務轉移到其他的節點上面繼續執行。當有新的作業進入到叢集中時,排程器會根據資源的使用情況合理的分配這些作業。並且JobTracker中的排程器是可以插拔的,這意味著使用者可以根據自己的需要,自定義作業和叢集的排程方法。但是JobTracker存在單點故障的問題,一旦JobTracker所在的機器宕機,那麼叢集就無法正常工作。
3.TaskTracker
TaskTracker使用 “slot” 對本節點的資源(cpu、記憶體、磁碟等)進行劃分,負責具體的作業執行工作。TaskTracker需要週期性向JobTracker彙報本節點的心跳資訊,包括自身執行情況、作業執行情況等,JobTracker中的排程器會根據心跳資訊對其分配“slot”,TaskTracker獲得slot之後,就開始執行相應的工作。其中 slot 有兩種: MapSlot 和 TaskSlot ,分別負責執行Map任務和Task任務,二者互不影響。
4.Task
分為兩種:Map Task 和 Reduce Task,分別執行Map任務和 Task 任務。MapReduce的輸入資料會被切分成多個 split ,一個split會交給一個Map Task去執行。
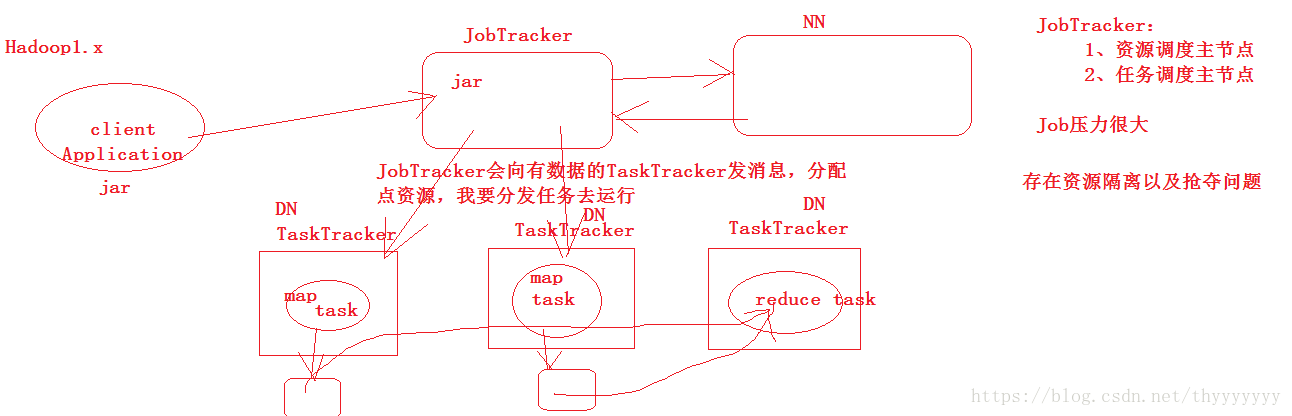
MapReduce 2.x 架構
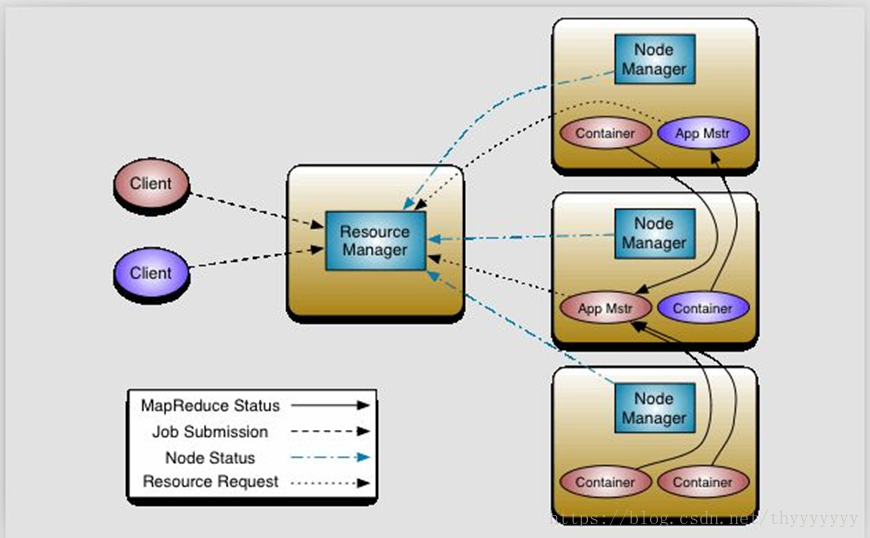
yarn資源排程器主從架構
ResourceManager
NodeManager
YARN:Yet Another Resource Negotiator;
Hadoop 2.0新引入的資源管理系統,直接從MRv1演化而來的;
核心思想:將MRv1中JobTracker的資源管理和任務排程兩個功能分開,分別由ResourceManager和ApplicationMaster程序實現
ResourceManager:負責整個叢集的資源管理和排程
ApplicationMaster:負責應用程式相關的事務,比如任務排程、任務監控和容錯等
YARN的引入,使得多個計算框架可執行在一個叢集中
每個應用程式對應一個ApplicationMaster
目前多個計算框架可以執行在YARN上,比如MapReduce、Spark、Storm等
基本功能模組
相關技術點
ResurceManager(RM):一個純粹的排程器,專門負責叢集中可用資源的分配和管理。
Container :分配給具體應用的資源抽象表現形式,包括記憶體、cpu、disk
NodeManager(NM) :負責節點本地資源的管理,包括啟動應用程式的Container,監控它們的資源使用情況,並報告給RM,管理Container生命週期
Container:節點NM,CPU,MEM,I/O大小,啟動命令,預設NM啟動執行緒監控Container大小,超出申請資源額度,kill
支援linux的Cgroup
App Master (ApplicationMaster(AM)):特定框架庫的一個例項,負責有RM協商資源,並和NM協調工作來執行和監控Container以及它們的資源消耗。AM也是以一個的Container身份執行。
以作業為單位,避免單點故障,負載到不同的節點,為task申請資源(Task-Container)
客戶端(Client):是叢集中一個能向RM提交應用的例項,並且指定了執行應用所需要的AM型別,請求資源建立AM,與AM互動
執行過程
- 提交MapReduce程式,向NameNode請求要處理檔案的Block的位置資訊。
- 向ResourceManager申請資源,請求啟動一個ApplicationMaster。
- RM接收到請求後隨機選擇一臺資源充足的節點啟動Container容器
- NodeManager會在這個Container容器中啟動一個ApplicationMaster(任務排程器)
- client把請求到的資訊報表提交到AM。
- AM根據這些位置資訊向ResourceManager申請資源,RM接收請求選擇資源充足的節點啟動一個Container容器,並在容器中建立yarn-child程序。
- AM分發Map Task執行緒到各個yarn-child中執行。
- 在每個yarn-child所在節點,每個Map Task執行緒執行完後會都會生成一個磁碟檔案。
- 如果yarn-child節點資源充足,AM會優先選擇這些節點分發Reduce Task任務。
- 等Reduce Task執行完之後,會把結果檔案寫入HDFS。