資料探勘領域十大經典演算法之—CART演算法(超詳細附程式碼)
阿新 • • 發佈:2019-01-07
簡介
CART與C4.5類似,是決策樹演算法的一種。此外,常見的決策樹演算法還有ID3,這三者的不同之處在於特徵的劃分:
- ID3:特徵劃分基於資訊增益
- C4.5:特徵劃分基於資訊增益比
- CART:特徵劃分基於基尼指數
基本思想
CART假設決策樹是二叉樹,內部結點特徵的取值為“是”和“否”,左分支是取值為“是”的分支,右分支是取值為“否”的分支。這樣的決策樹等價於遞迴地二分每個特徵,將輸入空間即特徵空間劃分為有限個單元,並在這些單元上確定預測的概率分佈,也就是在輸入給定的條件下輸出的條件概率分佈。
CART演算法由以下兩步組成:
- 決策樹生成:基於訓練資料集生成決策樹,生成的決策樹要儘量大;
- 決策樹剪枝:用驗證資料集對已生成的樹進行剪枝並選擇最優子樹,這時損失函式最小作為剪枝的標準。
CART決策樹的生成就是遞迴地構建二叉決策樹的過程。CART決策樹既可以用於分類也可以用於迴歸。本文我們僅討論用於分類的CART。對分類樹而言,CART用Gini係數最小化準則來進行特徵選擇,生成二叉樹。 CART生成演算法如下:
輸入:訓練資料集D,停止計算的條件:
輸出:CART決策樹。
根據訓練資料集,從根結點開始,遞迴地對每個結點進行以下操作,構建二叉決策樹:
- 設結點的訓練資料集為D,計算現有特徵對該資料集的Gini係數。此時,對每一個特徵A,對其可能取的每個值a,根據樣本點對A=a的測試為“是”或 “否”將D分割成D1和D2兩部分,計算A=a時的Gini係數。
- 在所有可能的特徵A以及它們所有可能的切分點a中,選擇Gini係數最小的特徵及其對應的切分點作為最優特徵與最優切分點。依最優特徵與最優切分點,從現結點生成兩個子結點,將訓練資料集依特徵分配到兩個子結點中去。
- 對兩個子結點遞迴地呼叫步驟l~2,直至滿足停止條件。
- 生成CART決策樹。
演算法停止計算的條件是結點中的樣本個數小於預定閾值,或樣本集的Gini係數小於預定閾值(樣本基本屬於同一類),或者沒有更多特徵。
程式碼
程式碼已在github上實現(呼叫sklearn),這裡也貼出來
# encoding=utf-8
import pandas as pd
import time 測試資料集為MNIST資料集,獲取地址為train.csv
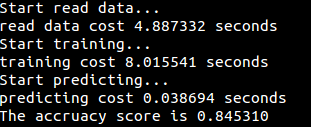
執行結果