
國際化字元編碼處理總結
阿新 • • 發佈:2019-01-07
在處理國際化時,處理不當就會產生亂碼,通用的做法是都轉換為UTF-8編碼,對於高層開發語言十分簡單,對於底層程式語言則有些複雜。其中涉及的概念也有很多。
字元是指計算機中使用的字母、數字、字和符號,包括:1、2、3、A、B、C、~!·#¥%……—*()——+等等。在 ASCII 編碼中,一個英文字母字元儲存需要1個位元組。在 GB 2312 編碼或 GBK 編碼中,一個漢字字元儲存需要2個位元組。在UTF-8編碼中,一個英文字母字元儲存需要1個位元組,一個漢字字元儲存需要3到4個位元組。在UTF-16編碼中,一個英文字母字元或一個漢字字元儲存都需要2個位元組(Unicode擴充套件區的一些漢字儲存需要4個位元組)。在UTF-32編碼中,世界上任何字元的儲存都需要4個位元組。
- ASCII 字元
- Unicode 字元
寬字元
- 用多個位元組來代表的字元稱之為寬字元,而Unicode只是寬字元編碼的一種實現,寬字元並不一定是Unicode。
- 寬字元字串表示為一個 wchar_t[] 陣列。可以通過用字母 L 作為字元的字首將任何 ASCII 字元表示為寬字元形式。例如,L’\0’ 是寬終止NULL 字元。同樣,可以通過用字母 L 作為 ASCII 字串的字首 (L”Hello”) 將任何 ASCII 字串表示為寬字元字串形式。
- wchar_t的寬度屬於編譯器的特性。對於Windows是16位寬;類Unix系統中,預設是32位寬。
位元組順序
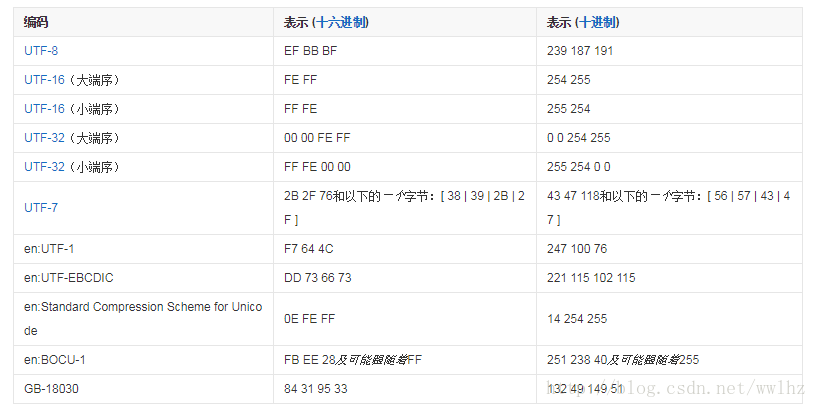
位元組順序涉及到位元組的大小端,一個檔案會在前面加上一個字元用來表明該檔案採用的是大端還是小端。這個字元的名字叫做”零寬度非換行空格”(zero width no-break space),用FEFF表示。
如果一個文字檔案的頭兩個位元組是FE FF,就表示該檔案採用大端方式;如果頭兩個位元組是FF FE,就表示該檔案採用小端方式。
“零寬度非換行空格” 又叫 BOM(Byte Order Mark),不同的編碼方式,會有不同的BOM格式。
參考: