
Python網路爬蟲--歷史天氣資料採集
阿新 • • 發佈:2019-01-07
在很多機器學習應用中,天氣資料為重要的輔助特徵資料,故本文主要介紹如何利用Python獲取歷史天氣資料。
目標網站
資料爬取的目標網站為天氣網
程式設計實現
匯入相關包
import requests # 匯入requests
from bs4 import BeautifulSoup # 匯入bs4中的BeautifulSoup
import os
import re
import csv
import pandas as pd
import numpy as np
import time
import json下面以爬取北京市歷史天氣資料為例進行演示:
獲取所有月份URL
分析網頁原始碼可知,所有月份的URL在’tqtongji1’的div中。

實現程式碼如下:
def get_url(request_url):
html = requests.get(request_url).text
Soup = BeautifulSoup(html, 'lxml') # 解析文件
all_li = Soup.find('div', class_='tqtongji1').find_all('li')
url_list = []
for li in all_li:
url_list.append([li.get_text(), li.find('a' 獲取某月份的歷史天氣資料
獲取到月份URL後,分析月份的頁面原始碼可知,歷史天氣資料在’tqtongji2’的div中。
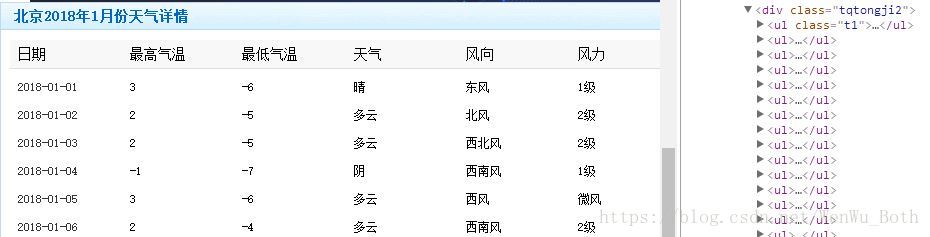
原始碼如下:
def get_month_weather(request_url, year_number, month_number):
# month_url = 'http://lishi.tianqi.com/beijing/201712.html'
url_list = get_url(request_url)
for i in range(len(url_list)-1 獲取某年的歷史天氣資料
將各月份的資料彙總即可得到年曆史天氣資料。
原始碼如下:
def get_year_weather(request_url, year_number):
year_weather = []
for i in range(12):
month_weather = get_month_weather(request_url, year_number, i+1)
year_weather.extend(month_weather)
print '第%d月天氣資料採集完成,望您知悉!'%(i+1)
col_name = ['Date', 'Max_Tem', 'Min_Tem', 'Weather', 'Wind', 'Wind_Level']
result_df = pd.DataFrame(year_weather)
result_df.columns = col_name
# result_df.to_csv('year_weather.csv')
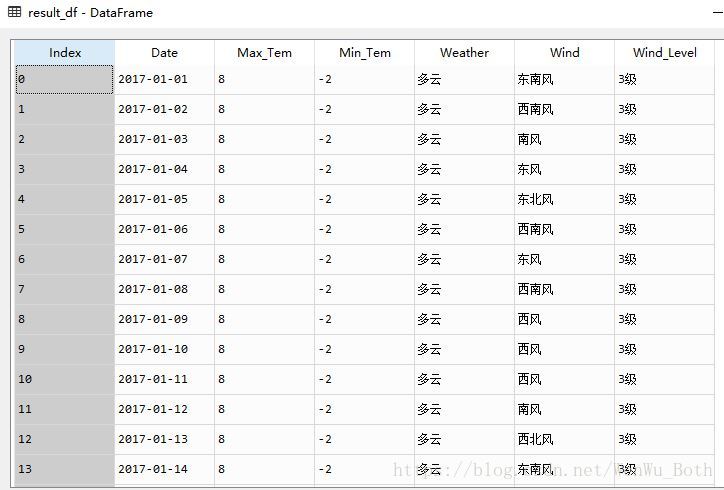
return result_df執行’result_df = get_year_weather(request_url, 2017)’,結果如下:
廣告時間

歡迎您掃一掃上面的二維碼,關注我的微信公眾號!