
NLP知識整理(下)
阿新 • • 發佈:2019-01-07
機器學習模型
- 在完成特徵抽取後,我們就將文字型資料轉化成了規範的數字格式資料,可以送入機器學習模型或深度學習模型進行訓練了。如果採用機器學習的方式,比較適合的模型有LR,LinearSVC, NaiveBayse,如果向量的維度不是很高很稀疏,一些樹類模型如RandomForest, Xgboost, LightGBM也可以對其進行訓練。
深度學習模型
- 隨著近些年深度學習的發展,在計算力和資料量足夠的條件下,深度學習越來越能發揮其深層特徵抽取的能力,獲得更好的預測效果和泛化效果。常見的模型有MLP, TextCNN, TextRNN, TextRCNN, LSTM, GRU, FastText,Bert… 這裡以TextCNN舉例講解一個深度學習模型的構建
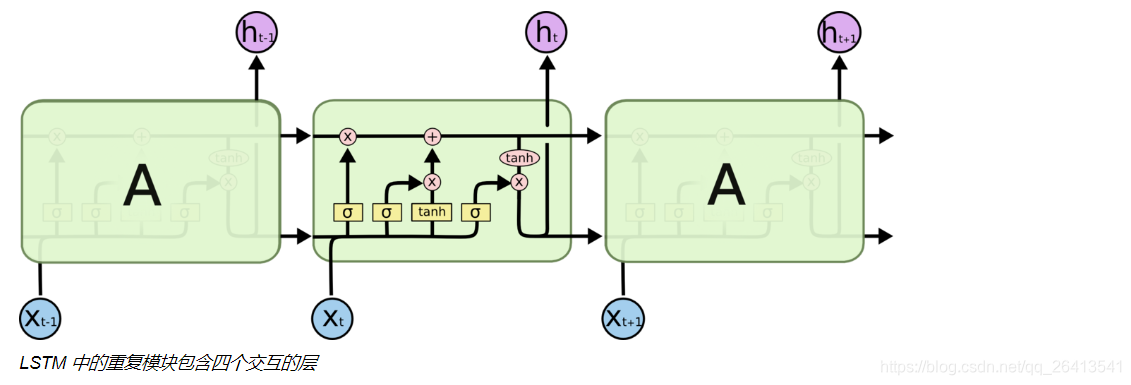
LSTM
-
LSTM是RNN的一個變體,目的是解決RNN迴圈次數增加後,會產生梯度消失現象導致導致模型不能很好的學習長期依賴資訊的問題。
-
RNN結構中,本層輸入和上層的輸出用一個很簡單的tanh進行融合。
普通RNN結構

遺忘門
- 遺忘門由上層輸出和本輪輸入共同決定,決定的方式是sigmoid輸出一個0-1的值(這個值往往可以看做是非0即1的),當這個值f為0時,之前的狀態C(t-1)與之點乘變成0,之前的狀態便被遺忘,反之之前的狀態與1點乘,原始資訊得以保留。
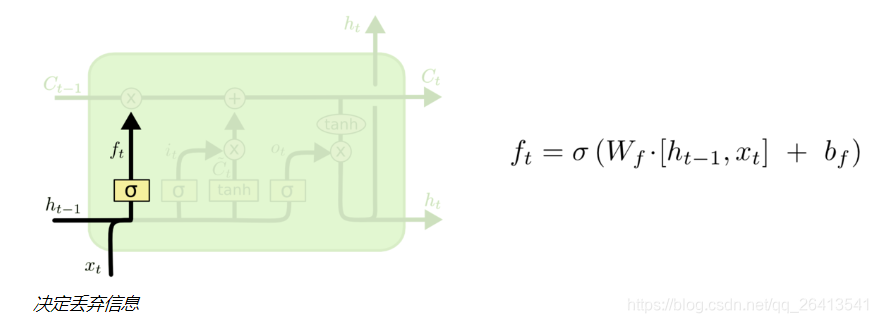
更新門
- 遺忘門是對之前的資訊做一個過濾,來確定遺忘還是記住之前的資訊狀態C(t-1)
- 除此之外,我們還要對當前輸入資訊X(t)做一個過濾,這就是更新門的作用
- 更新門由兩部分i(t)和C(t-1)組成,這兩部分都由上輪輸出h(t-1)和本輪輸出x(t)共同決定,i(t)的作用是用一個sigmoid函式產生一個近似0或1的值來確定是否保留C(t),而C~(t)則是通過非線性函式tanh將x(t)和h(t-1)融合產生的類狀態資訊。
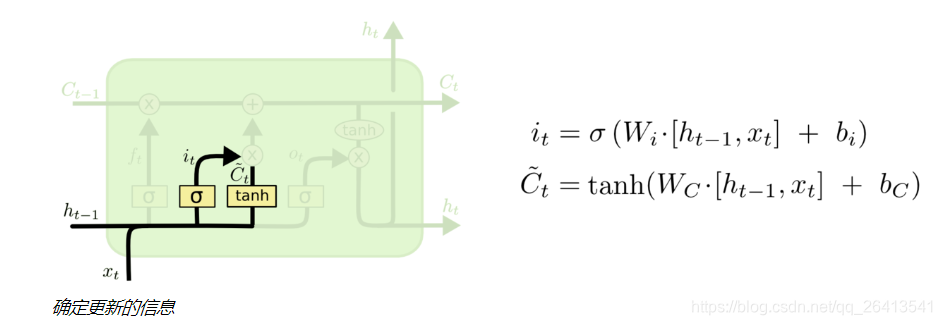
細胞狀態
- LSTM的可以記憶長期依賴資訊的核心就是細胞狀態,它是一個貫通多個細胞單元的單向傳送帶,只有一些很基本的點乘和疊加操作,狀態(也就是資訊)在上面的長期保持很容易。
- 之前的狀態先經過狀態門的點乘,確定下來是否被保留,在附加上更新門增添的資訊,這樣就構成了新的細胞狀態C(t)
- 注意,狀態C(t)並不是輸出h(t),它是保留了長期記憶資訊的輸出輔助。
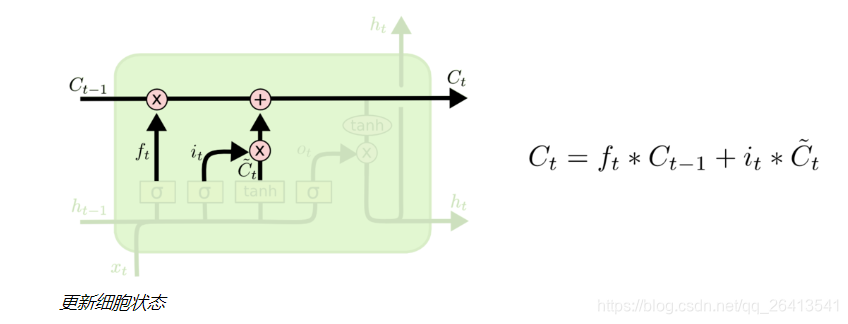
輸出門
- 狀態C(t)並不是輸出h(t),它是保留了長期記憶資訊的輸出輔助,所以自然的他要和上輪輸出h(t-1)、本輪輸入X(t)構成本輪輸出資訊h(t)。
- 輸出門也是由兩個部分構成,類似於更新們,sigmoid的作用是控制資訊是否保留,tanh的作用是引入非線性。
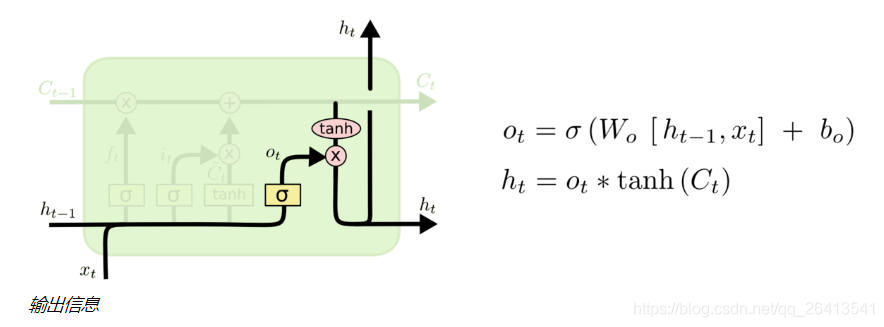
迴圈往復
- 在一個神經細胞當中,資訊經歷了遺忘門、更新門和輸出門三個部分產生了變化,將這個過程在多個神經細胞中不斷迴圈,就構成了LSTM
超引數調節
- LSTM的超引數並不是很多,核心引數有以下幾個:
① units 細胞個數
② input_dim 輸入向量的最大值不超過多少
③ output_dim 輸出向量的維度
④ input_length 輸入向量的維度,當下一層接的是Flatten層的時候,這個引數是必須指定的,用於Flatten層維度的計算。
⑤ return_sequences 是返回一個最終輸出,還是所有細胞產生的輸出序列,當使用兩層LSTM的時候,需要將第一層的return_sequences設定為True
⑥ dropout 控制過擬合
⑦ learning_rate 學習速率
⑧ batch_size 批數量
⑨ epoch 輪次
⑩ Optimizer 優化器(Adam,Momenten,RMSprop)
TextCNN
- TextCNN是處理文字問題的卷積神經網路,因為文字資料和影象資料略有不同,所以TextCNN較CNN有一些微小的變化。
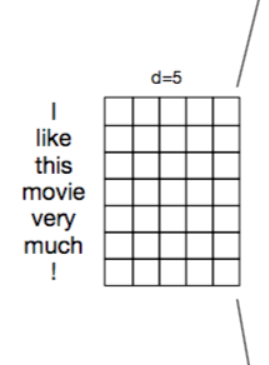
嵌入層
- 嵌入層的作用是將計算機不能理解的文字資料轉化成可以理解的向量化表示。
- 一般是使用稠密的向量化表示如Word2vec或者Glove,比較少的情況是經過pad_sequence補齊的Tokenizer,一般不使用詞袋模型CountVectorizer或者TF-IDF,因為這些方式產生的向量過於稀疏且不能很好的表示詞彙之間的相關性
- 詞嵌入的方式有兩種:
①隨機初始化引數,自己從頭學習,過程比較緩慢,但是如果語料庫足夠的話,訓練出來的詞嵌入會比較好的擬合當前語料。
②下載預訓練好的詞嵌入,賦值給詞嵌入矩陣,然後進行微調,微調的方法是將引數trainable設定為True,還有更好但也更麻煩的方式是從輸出層到輸入層逐層微調的歧視性學習。
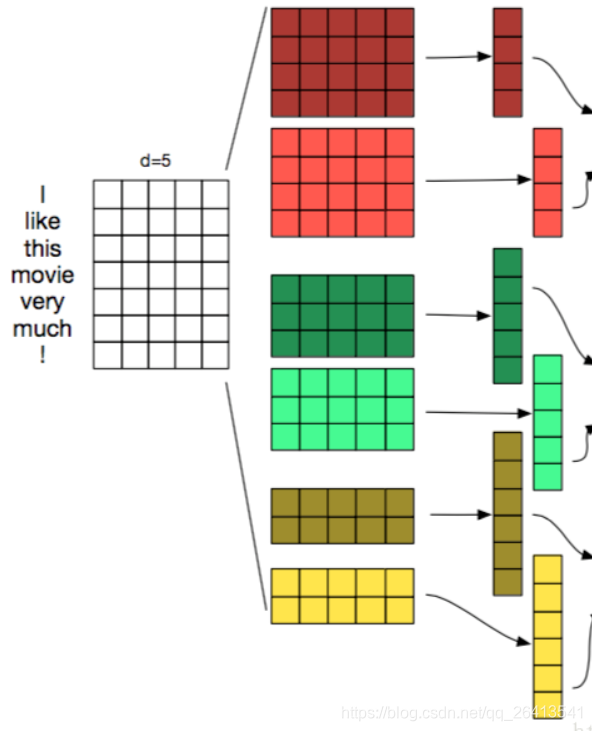
卷積層
- 卷積層的作用是特徵抽取
- TextCNN的卷積層和CNN中的很類似,都是用一個濾窗去和原矩陣相乘,再將這些值相加得到Feature Map,相當於將原來n維的詞向量降維到1維,這1維綜合了原來多維詞向量中包含的資訊。
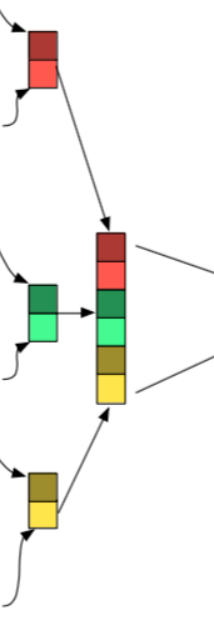
- 下圖中的三個部分,左邊是詞嵌入矩陣WordEmbedding,中間是濾窗Filter,右邊是運算後的結果Feature Map
- TextCNN中濾窗的大小,必須要包含一個完整的詞向量,在橫向的維度中,這個大小是不能改變的,而縱向的大小可以調節,其意義相當於每次從n個單詞中抽取資訊,和N-gram有異曲同工之妙。
- 卷積層可以設定的引數有濾窗的個數,和濾窗的大小,以下圖為例,尺寸為2,3,4的濾窗,每個尺寸都構建了兩個濾窗,一共6個。
- 不同尺寸的濾窗可以分屬不同的channel
池化層
- 池化層的作用是特徵平移不變性,最大池化層操作的方式是僅保留原始Feature Map中最大的值而捨棄掉其餘的部分。
- 常見的有最大池化層和平均池化層,一般認為最大池化層的效果更好一些。
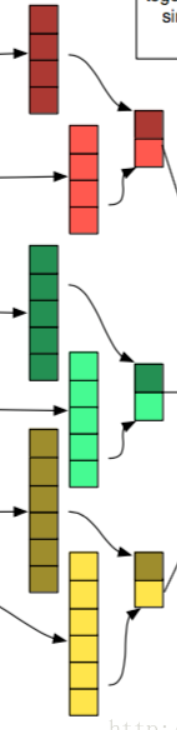
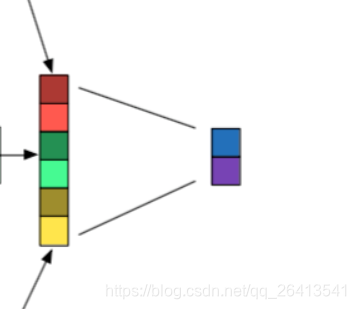
拼接層
- 將多個maxpooling得到的結果拼接成一個一維的長向量
全連線層
- 最後一般還會接一至兩個全連線層,作為隱藏層和輸出層,隱藏層的啟用函式一般是relu或者tanh,如果是分類問題,輸出層的啟用函式一般是softmax。
超引數調節
① 初始化詞向量,一般是word2vec或者Glove,注意不要使用One-Hot Vectors
② 卷積核尺寸,1-10之間,一般認為文字越長,需要的卷積核尺寸越大,用以捕捉不同詞之間的共現關係,該引數對最終結果影響較大。
③ 每種尺寸卷積核數量,100-600之間,可以理解未某種意義上的epoch,該數值越大,訓練時間越長。
④ 啟用函式的選擇,用來帶來非線性表達能力,一般relu和tanh比較常見,輸出層的啟用函式可能是sigmoid或者是softmax
⑤ 池化層的選擇,帶來特徵平移不變性,一般使用maxpooling1D
⑥ 正則化項,對最終效果影響較小。
FastText
- FastText是facebook開源的一個詞向量與文字分類工具,典型應用場景是“帶監督的文字分類問題”。
- FastText提供簡單而高效的文字分類和表徵學習的方法,效能比肩深度學習而且速度更快
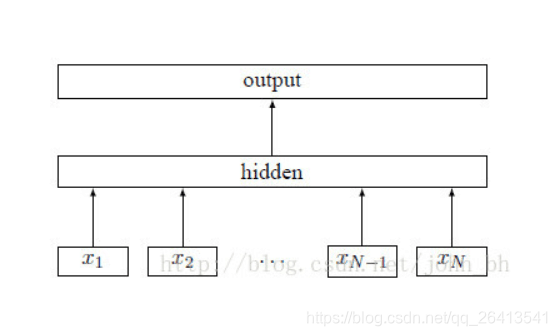
- FastText的結構特點可以分為3個部分:
① 在輸入層使用基於N-Gram的特徵抽取
② 在隱藏層使用無啟用函式的線性運算(求和或平均)
③ 在輸出層使用層次化SoftMax直接輸出分類結果 - FastText可以執行的任務有兩類:
① 文字分類任務
② 詞向量學習 - FastText和Word2vec的共同點:
① 都是用word embedding的稠密向量表達形式
② 優化結構類似,都採用層次化softmax進行加速和優化和線性的啟用函式 - FastText和Word2vec的區別:
① Word2vec的輸出是詞向量,而FastText輸出的是分類類別,而中間產生的詞向量不會被保留。
② Word2vec的輸入是term,而FastText的輸入是sentence,FastText會自動的將其分詞並執行N-Gram
樸素貝葉斯
- 樸素貝葉斯基於條件獨立假設和貝葉斯公式,屬於生成式模型,運算速度比較快,在有大量樣本的情況下效果尚可。
- 雖然獨立假設的判斷並非完全正確,但是極大的簡化了運算。
- 貝葉斯公式: P(A|B) = P(B|A) P(A) / P(B)
- 其中A代表標籤,B代表特徵,這樣就把通過特徵預測標籤的問題轉化為通過已有標籤中某特徵的分佈/某標籤比例/某特徵比例三者間的統計運算。
- 為了避免某特徵B的出現概率為零導致上述公式分母為零無法運算的問題,引入拉普拉斯平滑,將P(B)+1
- 樸素貝葉斯常用的模型有三種:
① 高斯模型: 處理特徵是連續型變數的情況
② 多項式模型: 最常見,要求特徵是離散資料
③ 伯努利模型: 要求特徵是離散的,且為布林型別,即true和false,或者1和0