
Zookeeper簡介(一)
使用Zookeeper已經有幾年時間了,零零散散的積累了一些經驗,但從未想過能寫出一些列的文章分享出來。從今天起,計劃持續更新關於Zookeeper相關的文章,從基本的搭建使用、原理分析、典型場景分析、引用案例及程式碼編寫,甚至到後期的原始碼分析,帶領大家一步步的從入門到深入Zookeeper的使用,在這個過程中你會像我一樣慢慢的喜歡上它。歡迎大家持續關注本人部落格。
簡介
如果你還處於單機時代,那麼你將很少用到Zookeeper,很多更好的方案可以幫助你解決問題。一旦涉及到分散式應用,或許在每做一個決定的時候都要想一想,是否可以使用Zookeeper來實現。
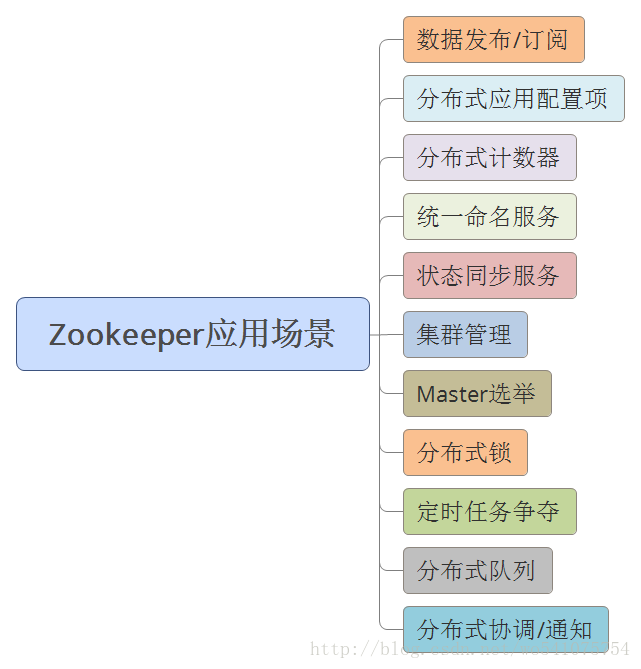
Zookeeper是Apache Hadoop的一個子專案,主要是用來解決分散式應用中經常遇到的一些資料管理問題。下圖列舉了一些可能會遇到的場景。
特點
Zookeeper可以保證如下的分散式特性:
順序一致性
原子性
單一檢視
可靠性
實時性
設計目標
目標一 簡單的資料模型
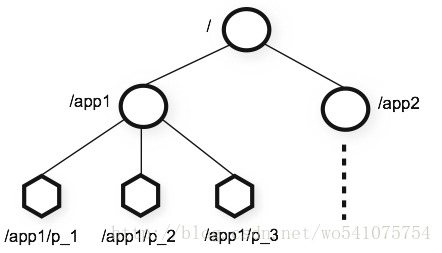
Zookeeper使得分散式程式能夠通過一個共享的、樹形結構的名字空間來進行相互協調。組成這個樹形結構的資料節點被稱作ZNode,它們之間的層級關係就像檔案系統的目錄結構一樣。
目標二 可以構建叢集
也就是Zookeeper服務的可複製性。一般3-5臺機器就可以構建一個Zookeeper的叢集。只要確保一半以上的伺服器能夠正常工作,整個機器就能夠正常對外服務。相互之間可以進行通訊,在記憶體中維護當前伺服器狀態。客戶可以與任意一臺伺服器建立TCP連線進行通訊,當與此伺服器連線斷開之後,客戶端會自動連線到叢集中的其他伺服器繼續工作。
目標三 順序訪問
客戶端的每一個更新請求Zookeeper都會分配一個全域性唯一的遞增編號,通過這個編號可以確保事物操作的先後順序。
目標四 高效能
Zookeeper將全量資料儲存於記憶體之中,並直接服務於客戶端的所有非事物請求,因此在讀操作的應用上優勢更為明顯。可以在千臺伺服器組成的讀寫比例大約為10:1的分佈系統上表現優異。
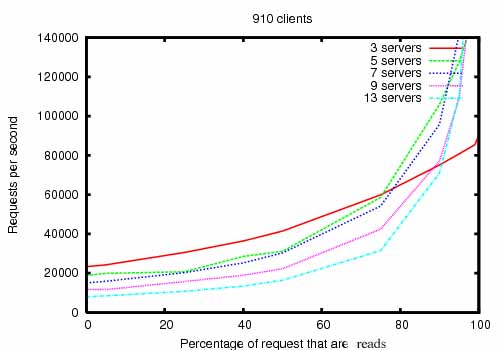
(此圖來自官網圖片)
版本及官網
Zookeeper的官網地址:http://zookeeper.apache.org/
GitHub地址:https://github.com/apache/zookeeper
目前穩定版本為Release 3.4.9,以後的部落格內容也以此版本為基礎來講解。
---------------------
作者:朱智勝
來源:CSDN
原文:https://blog.csdn.net/wo541075754/article/details/56335059
版權宣告:本文為博主原創文章,轉載請附上博文連結!