大資料系列之資料倉庫Hive知識整理(四)Hive的嚴格模式,動態分割槽,排序,事務,調優
1.Hive的嚴格模式
Hive提供了一個嚴格模式,可以防止使用者執行那些產生意想不到的不好的影響的查詢。
想想看在那麼大的資料量的前提下,如果我們在分割槽上表上使用查詢所有,或是使用了笛卡爾積查詢資料等等不良情況,那得花費我們多少時間和資源成本,Hive在預設情況下會開啟一種模式,叫做嚴格模式,來限制我們這些不良操作。
其中在hive-site.xml的配置檔案中,設定了屬性來進行全域性的配置

對於全域性的配置,我們可以修改這些屬性,也可以採用臨時會話的形式,使用set 屬性=值的形式來進行修改,只不過只在當前會話有效。
使用了嚴格模式之後主要對以下3種不良操作進行控制:
1.分割槽表必須指定分割槽進行查詢。
2.order by時必須使用limit子句。
3.不允許笛卡爾積。
2.Hive的動態分割槽
之前我們介紹過了分割槽表,並且查看了分割槽表的儲存結構(分割槽表是目錄),並且像分割槽表裡面儲存了資料。我們在進行儲存資料的時候,都是明確的指定了分割槽。在這個過程中Hive也提供了一種比較任性化的操作,就是動態分割槽,不需要我們指定分割槽目錄,Hive能夠把資料進行動態的分發,例如2018年的資料,就讓他進入2018年分割槽目錄下,2017年的資料,就讓他進入2017的目錄下。使用動態分割槽的時候,我們需要將當前的嚴格模式設定成非嚴格模式,否則不允許使用動態分割槽
$hive>set hive.exec.dynamic.partition.mode=nonstrict//設定非嚴格模式
//設定動態分割槽的語法如下所示:
$hive>insert into t5 partition(country,province) select (包含分割槽的欄位資訊就可以) from orders;
//用到的相關的表
hive> CREATE TABLE t5(id int,price int) PARTITIONED BY (country string, province string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
//orders
1,24,china,sd
2,25,china,sd
3,26,china,sd
4,27,china,sd
5,28,china,sy
6,29,china,sy
7,30,china,sy
8,31,china,sy
9,32,china,sy
10,33,china,sy
11,34,china,sh
12,35,china,sh
13,24,china,sh
14,25,china,sh
15,26,china,sh
16,24,china,sh
如果當前模式是嚴格模式,則要求至少有一列的欄位是靜態的,且靜態欄位必須出現在最前面
$hive>insert into t5 partition(country=china,province) select (包含分割槽的欄位資訊就可以) from orders;

3.Hive的排序
與Mysql類似,Hive也提供了一些排序的語法,包括order by,sort by。
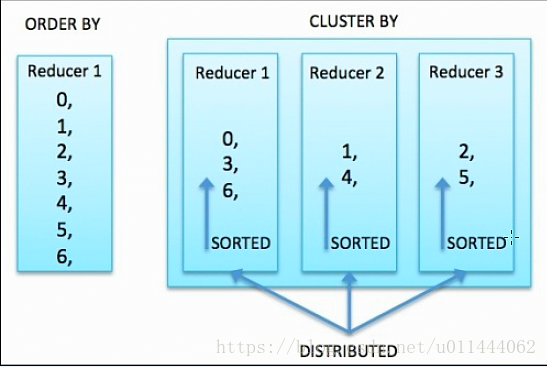
order by=MapReduce的全排序
sort by=MapReduce的部分排序
distribute by=MapReduce的分割槽
想想之前我們說過的大資料之Hadoop系列說的MapReduce的分割槽,排序,歸併的過程。由於Hive在一些操作中會自動幫我們呼叫MapReduce來完成一些資料操作,會自動開啟MapReduce操作,不用我們寫Mapper和Reduce函式,如果我們使用上述的語法,是不是就是在自定義排序,自定義分割槽呢,是不是很簡單的一句話就能夠實現我們之前在大資料之Hadoop系列中的複雜的自定義分割槽,排序函式,是不是方便很多,舒服很多。
基本語法與MySql語法基本一致
selece .......from ...... order by 欄位;//按照這個欄位全排序
selece .......from ...... sort by 欄位; //按照這個欄位區域性有序
selece 欄位.....from ...... distribute by 欄位;//按照這個欄位分割槽
特別注意的是:
1.在上面的最後一個distribute by使用過程中,按照排序的欄位要出現在最左側也就是select中有這個欄位,因為我們要告訴MapReduce你要按照哪一個欄位分割槽,當然獲取的資料中要出現這個欄位了。類似於我們使用group by的用法,欄位也必須出現在最左側,因為資料要包含這個欄位,才能按照這個欄位分組,至於Hive什麼時候會自行的開啟MapReduce,那就是在使用聚合的情況下開啟,使用select ...from ....以及使用分割槽表的selece ....from......where .....不會開啟。

2.distribute by與sort by可以組合使用,但是distribute by要放在前邊,因為MapReduce要先分割槽,後排序,再歸併
語法如下:
select 欄位a,........from .......distribute by欄位a,sort by欄位
如果distribute by與sort by使用的欄位一樣,則可以使用cluster by 欄位替代:
select 欄位a,........from .......cluster by 欄位
4.Hive的事務
hive事務處理在>0.13.0之後支援行級事務。
---------------------------------------
1.所有事務自動提交。
2.只支援orc格式。
3.使用bucket表。
4.配置hive引數,使其支援事務。(只是設定了臨時會話,只在當前對話生效,如要持久化,就在hive-site.xml中配置)
$hive>SET hive.support.concurrency = true;
$hive>SET hive.enforce.bucketing = true;
$hive>SET hive.exec.dynamic.partition.mode = nonstrict;
$hive>SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
$hive>SET hive.compactor.initiator.on = true;
$hive>SET hive.compactor.worker.threads = 1;
5.使用事務性操作
$>CREATE TABLE tx(id int,name string,age int) CLUSTERED BY (id) INTO 3 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as orc TBLPROPERTIES ('transactional'='true');
5.Hive的調優
Hive提供了多種的調優的手段,優化手段
//1使用explain檢視查詢計劃
hive>explain select count(*) from customers ;
hive>explain extended select count(*) from customers ; //更加詳細的資訊

//2.設定limit優化測,避免全部查詢.
hive>set hive.limit.optimize.enable=true
//3本地模式
$hive>set mapred.job.tracker=local;//
$hive>set hive.exec.mode.local.auto=true//自動本地模式,測試
//4.嚴格模式,
$hive>set hive.mapred.mode=strict //1.分割槽表必須指定分割槽進行查詢
//2.order by時必須使用limit子句。
//3.不允許笛卡爾積.
//5.設定MR的數量
hive> set hive.exec.reducers.bytes.per.reducer=750000000;//設定reduce處理的位元組數。
//6.JVM重用
$hive>set mapreduce.job.jvm.numtasks=1//-1沒有限制,使用大量小檔案。
//7.資料傾斜.
$hive>SET hive.optimize.skewjoin=true;
$hive>SET hive.skewjoin.key=100000;
$hive>SET hive.groupby.skewindata=true;
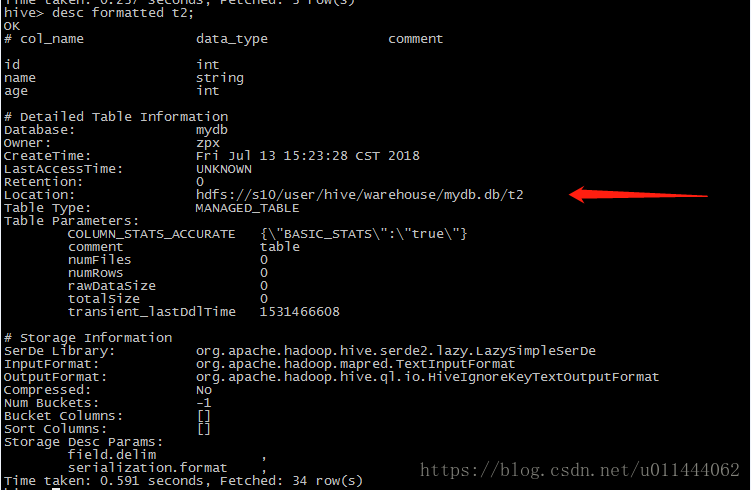
補充:我們也可以通過如下手段來查看錶的結構
desc 表;
desc formatted 表;//查看錶的詳細資訊