
Pandas讀取並修改excel
一、前言
最近總是和excel打交道,由於資料量較大,人工來修改某些資料可能會有點浪費時間,這時候就使用到了Python資料處理的神器—–Pandas庫,話不多說,直接上Pandas。
二、安裝
這次使用的python版本是python2.7,安裝python可以去python的官網進行下載,這裡不多說了。
安裝完成後使用Python自帶的包管理工具pip可以很快的安裝pandas。
pip install pandas如果使用的是Anaconda安裝的Python,會自帶pandas。
三、read_excel()介紹
首先可以先建立一個excel檔案當作實驗資料,名稱為example.xlsx,內容如下:
| name | age | gender |
|---|---|---|
| John | 30 | male |
| Mary | 22 | female |
| Smith | 32 | male |
這裡是很簡單的幾行資料,我們來用pandas實際操作一下這個excel表。
# coding:utf-8
import pandas as pd
data = pd.read_excel('example.xlsx', sheet_name='Sheet1')
print data結果如下:
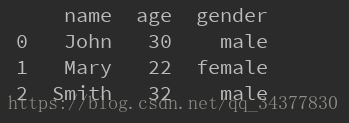
這裡使用了read_excel()方法來讀取excel,來看一個read_excel()這個方法的API,這裡只截選一部分經常使用的引數:
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None)這裡主要引數為io,sheet_name,header,usecols和names
io:excel檔案,如果命名為中文,在python2.7中,需要使用decode()來解碼成unicode字串,例如: pd.read_excel('示例'.decode('utf-8)) sheet_name:返回指定的sheet,如果將sheet_name指定為None,則返回全表,如果需要返回多個表,可以將sheet_name指定為一個列表,例如['sheet1', 'sheet2'] header:指定資料表的表頭,預設值為0,即將第一行作為表頭。 usecols:讀取指定的列,例如想要讀取第一列和第二列資料: pd.read_excel("example.xlsx", sheet_name=None, usecols=[0, 1])
四、使用
這裡先來一個在機器學習中經常使用的:將所有gender為male的值改為0,female改為1。
# coding:utf-8
import pandas as pd
from pandas import DataFrame
# 讀取檔案
data = pd.read_excel("example.xlsx", sheet_name="Sheet1")
# 找到gender這一列,再在這一列中進行比較
data['gender'][data['gender'] == 'male'] = 0
data['gender'][data['gender'] == 'female'] = 1
print data結果如下:
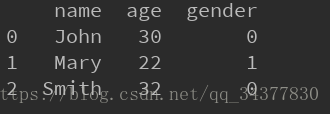
需要注意的是,這裡的data為excel資料的一份拷貝,對data進行修改並不會直接影響到我們原來的excel,必須在修改後儲存才能夠修改excel。儲存的程式碼如下:
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)這時候我們再開啟example.xlsx檔案看看是否更改了:
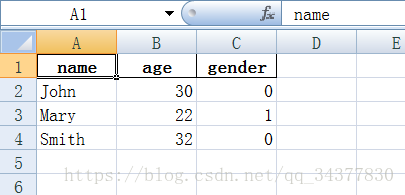
如果我們想要新增加一列或者一行資料怎麼辦呢?這裡給出參考:
新增列資料:
data['列名稱'] = None
新增行資料,這裡行的num為excel中自動給行加的id數值
data.loc[行的num] = [值1, 值2, ...]
以上面的資料為例:
# coding:utf-8
import pandas as pd
from pandas import DataFrame
data = pd.read_excel("example.xlsx", sheet_name='Sheet1')
# 增加行資料,在第5行新增
data.loc[5] = ['James', 32, 'male']
# 增加列資料,給定預設值None
data['profession'] = None
# 儲存資料
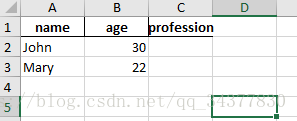
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)開啟excel看到的結果如下:
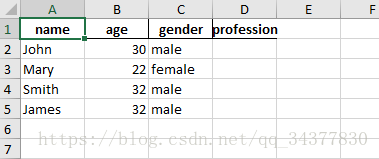
說完了增加一行或一列,那怎樣刪除一行或一列呢?
import pandas as pd
from pandas import DataFrame
data = pd.read_excel("example.xlsx", sheet_name='Sheet1')
# 刪除gender列,需要指定axis為1,當刪除行時,axis為0
data = data.drop('gender', axis=1)
# 刪除第3,4行,這裡下表以0開始,並且標題行不算在類
data = data.drop([2, 3], axis=0)
# 儲存
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)這時候開啟excel可以看見gender列和除標題行的第3,4行被刪除了。
總結
pandas除了上述的基本功能以外,還有其它更高階的操作,想要進一步學習的小夥伴們可以去pandas網站進行學習。