
作為大眾熟知的電商應用,京東如何構建風控體系架構?
作為大眾熟知的電商應用,京東是如何構建堅挺的風控體系架構?如何優化資料的計算和儲存?如何基於裝置做智慧識別的?本文由京東技術專家王美青對以上問題進行解讀。
風控技術體系介紹
風控技術架構
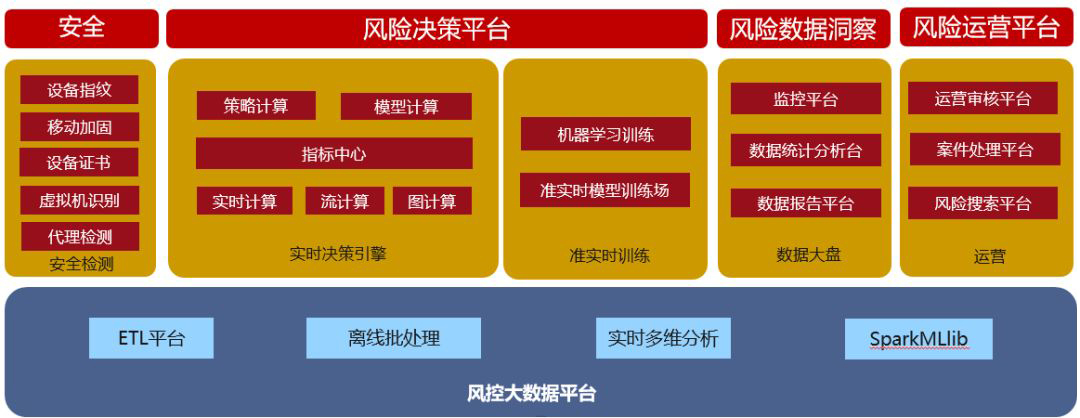
上圖是風控技術架構圖,包括安全模組、風險決策平臺、風險資料洞察模組、風險運營平臺。其中,安全模組跟使用者的接觸是最緊密的,其包含裝置指紋、移動端加固、裝置證書、虛擬機器識別以及代理檢測。
風險決策平臺根據場景進行管控和實時決策,同時支援策略計算和模型計算。指標庫中囊括了所有的指標、策略、模型資料。下層是實時計算、流計算和圖計算。另外,風險決策平臺還包括機器學習訓練模組和準實時模型訓練場。
風險資料洞察模組對風險進行實時監控,統計分析,並形成報告。
風險運營平臺相對來說是比較滯後的一個平臺,實時場景生成後,提供一個運營稽核的平臺;在案件處理平臺,通過人工介入為線上模型提供真實案例;風險搜尋平臺,提供成功交易之後的風險分析詳情。
風險管控方案架構
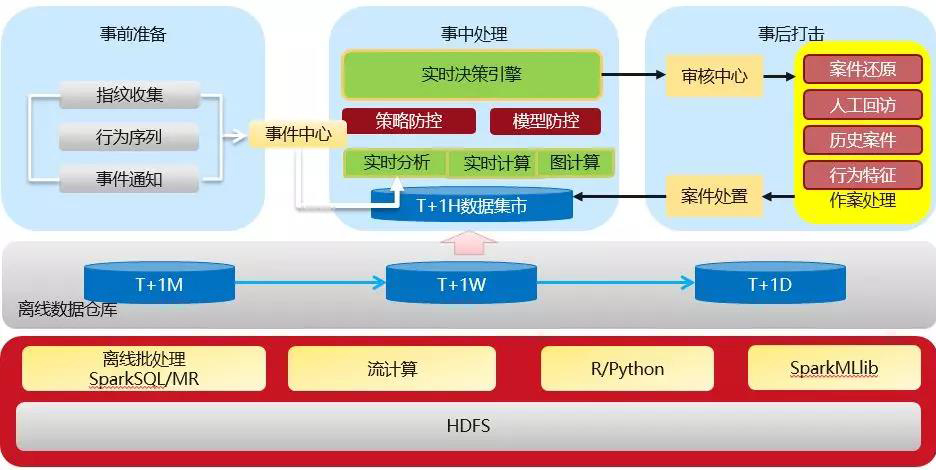
風險管控包括三個方面:事前準備、事中處理、事後打擊。
1、事前準備
蒐集裝置端的環境資訊,包括指紋、行為序列和業務上的事件通知,不包含使用者的敏感資訊。
2、事中處理
實時決策引擎部署了很多策略和模型,通過實時分析、實時計算、圖計算進行處理。
3、事後打擊
發現風險後對案件進行還原,此時會介入人工稽核,經過比對歷史案件、分析行為特徵等,確認後再回流到資料集市中。下層是一些計算工具,設定了幾層向上的資料推送,包括T加一個月、T加一週、T加一天。
資料計算與儲存技術
資料處理架構–Lambda架構
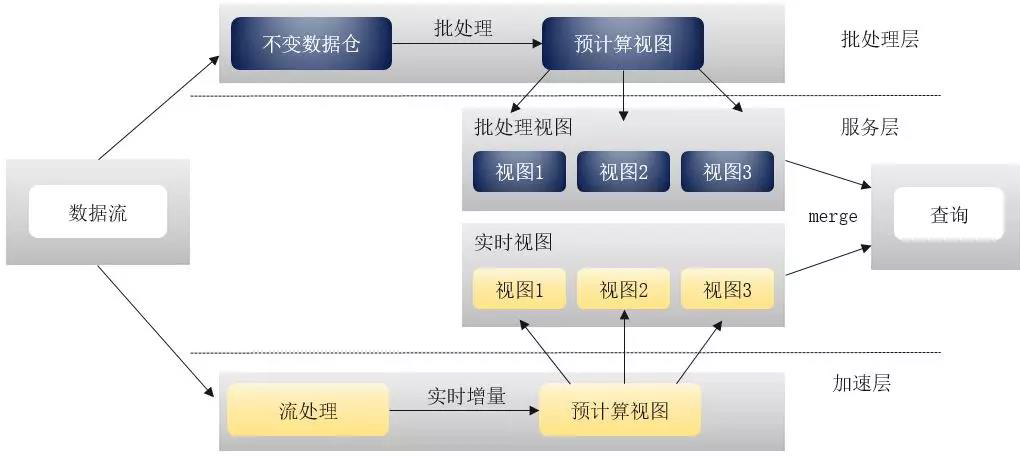
上圖是資料處理架構Lambda,在輸入資料後,資料流一部分進入不變資料倉,經過批處理進入儲存檢視中,供對外的查詢服務使用。另一部分進行實時計算,計算完後資料便廢棄了。
資料計算架構
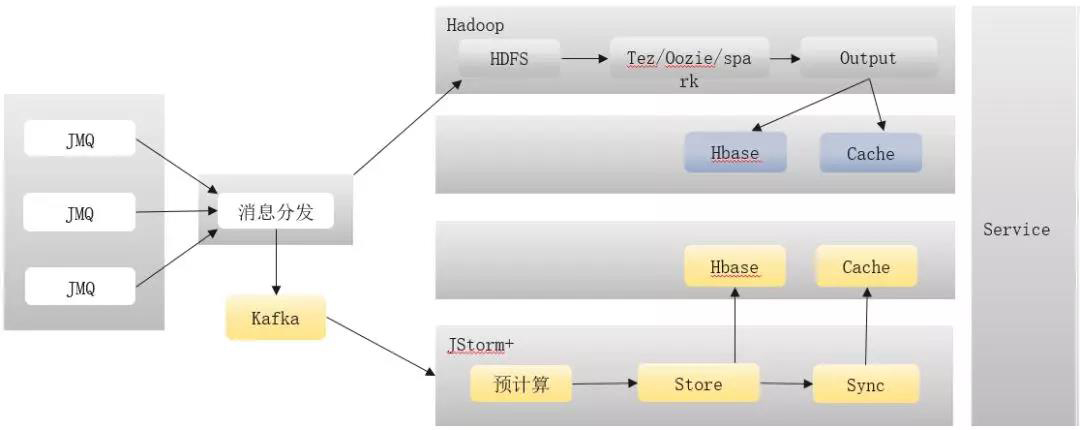
公司內部大多使用JMQ訊息模式,將JMQ 訊息集中收集後分發,通過Kafka進入計算平臺,使用JSTORM進入儲存,分別存入Hbase和Cache。其中供線上毫秒級響應時所做的儲存全部放入Cache中。
實時計算框架

1、特點
- 響應式架構
- 時間滑動視窗
- 定義了類SQL的特定領域語言
- 內建多種函式
- Java+scala
2、Flink應用
使用多個流相互連結,這些流都不是同時的,但他們互相間有線索,可以將多個流串聯起來。
資料可靠性保障
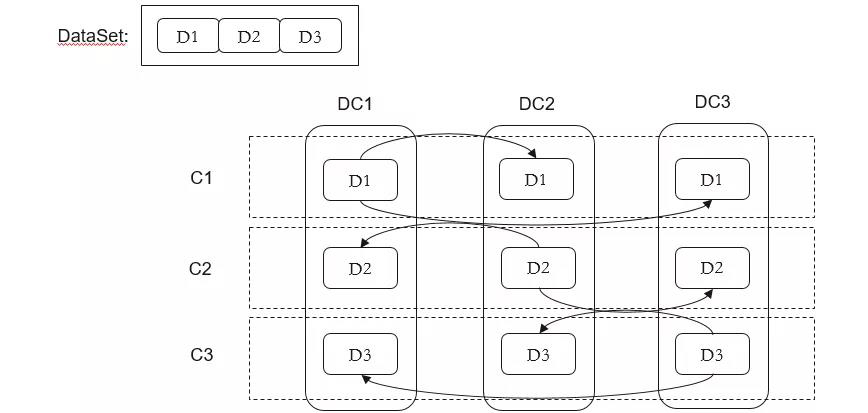
如上圖中的資料集,資料集包含三個資料中心。將每一份資料分別在多個機房進行儲存,然後將每一組機器劃分到一個機房。當某個機房出現問題後,可獲取到DataSet。
資料治理方案
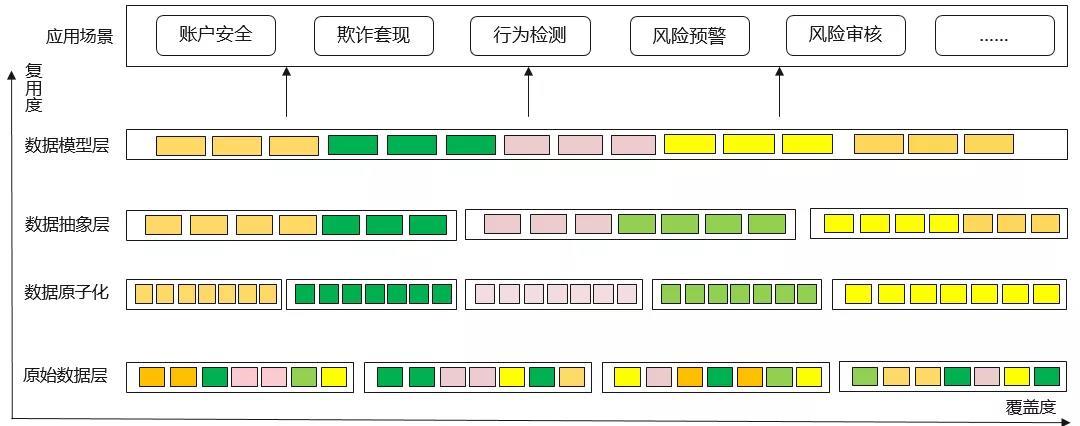
1、原始資料層
原始資料層資料是未經加工、雜亂無章的。
2、資料原子化層
通過資料加工將資料分門別類,例如分為帳戶級別、交易級別、訂單,使資料原子化。
3、資料的抽象層
將原子層的資料拼裝,為資料建模準備。
4、資料模型層
將資料抽象層歸納好的資料,再抽象出一層,供業務場景使用。
*資料縱向層級越高,資料的複用度就越大,橫向越多,覆蓋度就越高
移動安全及應用
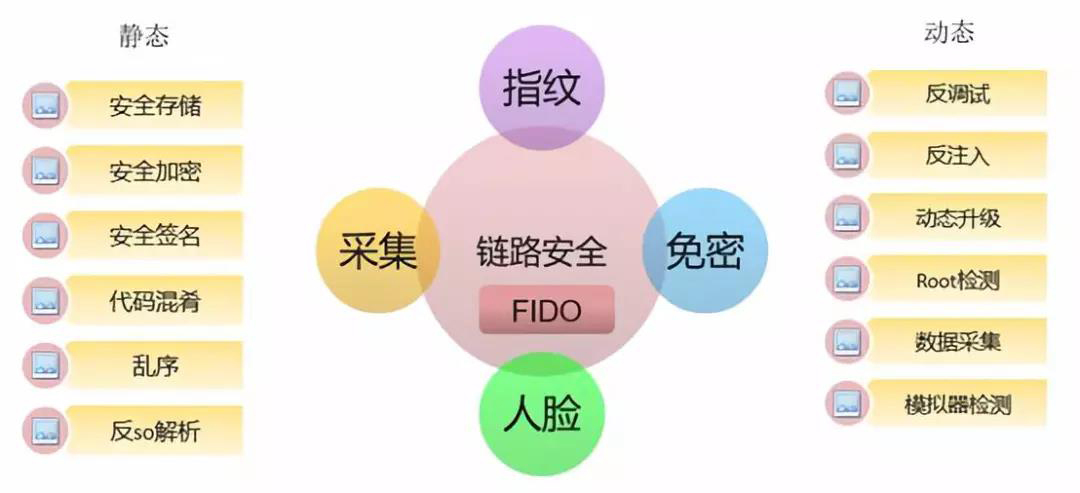
在安全鏈路方面整合FIDO協議,鏈路安全由軟實現和FIDO共同支撐。FIDO包括:指紋、免密、人臉和一些資料的採集。採集的資料並非使用者敏感資料,而是使用者使用手機時在感測器方面的表現。
流程步驟
使用者使用時首先有一個簽約認證的Server。第二步是,證書服務,生成一個證書;第三步是Key工廠,在其中緩衝了很多序列,可以直接拿到公鑰、私鑰,然後通過指紋免密Server做認證。
風控指紋裝置
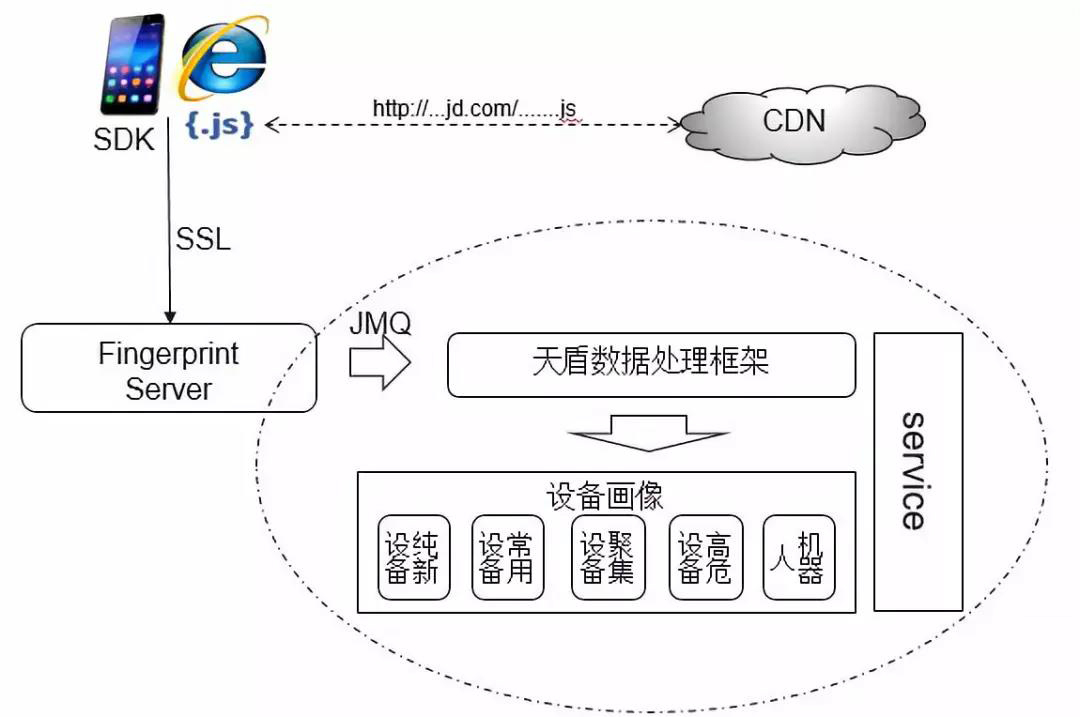
如圖通過SSL實現CDN與客戶端的互動作為前提,將客戶端收集的瀏覽器環境軟資訊放到Fingerprint Server中,並將所有蒐集過來的裝置資料在後臺進行裝置畫像的製作。
智慧化風控建設
怎樣進行人機識別?
1、基於裝置的智慧識別
通過裝置狀態識別:裝置狀態的運動包含幾個維度,不同的運動在感測器和陀螺儀的表現是不一樣,通過裝置運動狀態可以進行人機識別。
通過充放電識別:機器和普通使用者在使用裝置時的充放電狀態是不一樣的,普通使用者的手機不會一直處於充電狀態中。
通過借貸軟體識別:經過使用者授權,獲取使用者使用的借款軟體相關資料。
通過這幾個識別指徵,輸出識別安全指數評測,可通過後臺或伺服器檢測出使用裝置的資訊。
2、通過生物識別
使用者進行同一操作時的使用習慣也是不一樣的,通過感測器和陀螺儀的感應資料,可以判斷使用裝置的是否是本人。
智慧化風控建設
無監督學習——社群發現
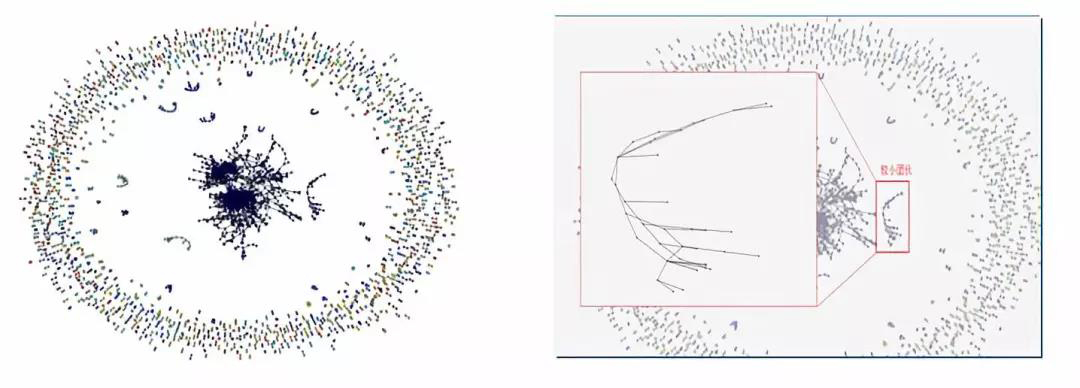
如圖確定IP、手機號、地址、座標、裝置、wifi等多維權重計算;通過多維計算出“度”—[0-1],通過模型確定閾值;A-B達到閾值即產生邊,頂點是賬戶。
社群發現對團伙作案、突發事件、潛在風險都能夠有效識別。
機器學習平臺
機器學習平臺包括指標自動加工平臺、模型智慧訓練平臺、模型智慧評估平臺、模型管理執行平臺。通過四大平臺的協作,能有效地提高資料處理的效率、降低複雜度、增加產出,有利於統一進行管理。
指標自動加工平臺:通過指標自動加工平臺,實現對線上資料、線下資料的統一管理。
模型智慧訓練平臺:實現模型的並行化訓練,配置化訓練。
模型智慧評估平臺:實現對樣本資料的實時加工,配置化管理。
模型管理執行平臺:實現對模型的生命週期管理,支援Python、Spark-MLIB、SCIKIT-learn、Tensorflow等演算法庫
資料遷移特徵

支援斷點續傳、流量的調節、多資料來源、容災、彈性、多活。
分佈排程中心
1、Job生命週期
Job生命週期包括:Open—Load——Lock——Execute——Finish——End——Reset。
Open:每次排程被觸發都生成唯一的一次作業,在排程方儲存該作業的每個狀態並更新至ZK。進行事件通知。
Execute:執行任務是非同步化的。open階段和lock階段都是同步執行,lock和Execute都是在叢集上完成分片。
Finish:本次作業完成後等待下次排程被觸發,生命週期重新開始。進行事件本地通知。
2、核心角色
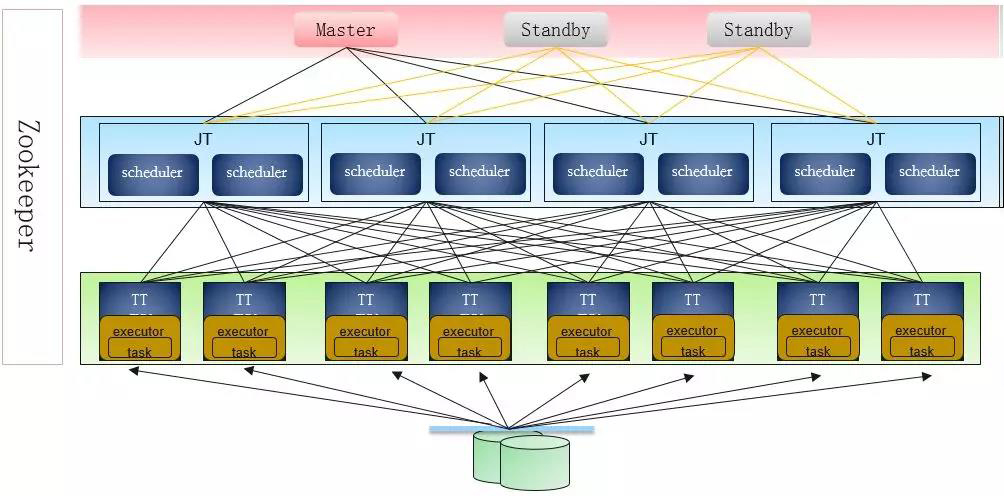
借鑑JT的思路,由Master將這些任務分配到不同的JT中去。
3、通訊實現
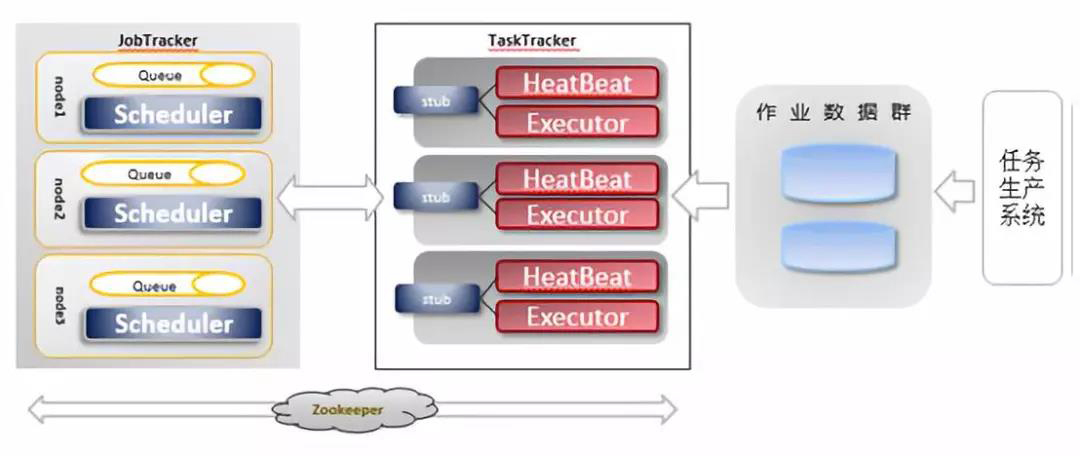
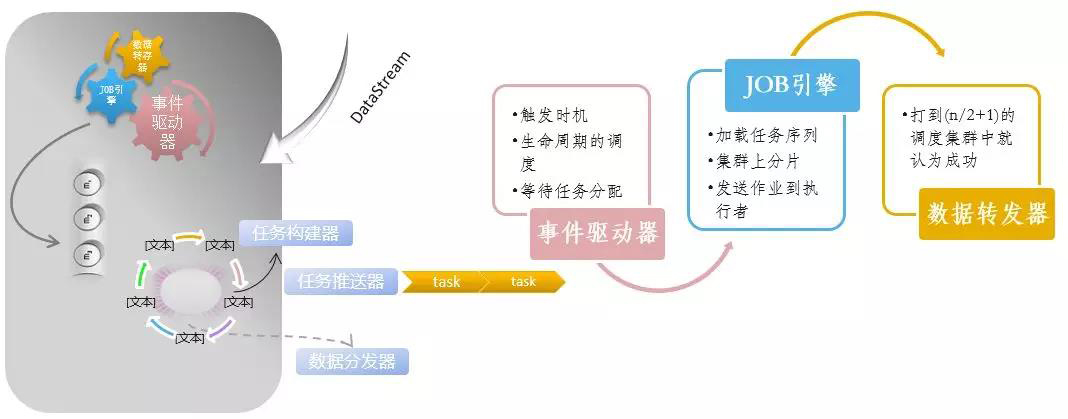
4、內部設計
機器學習平臺
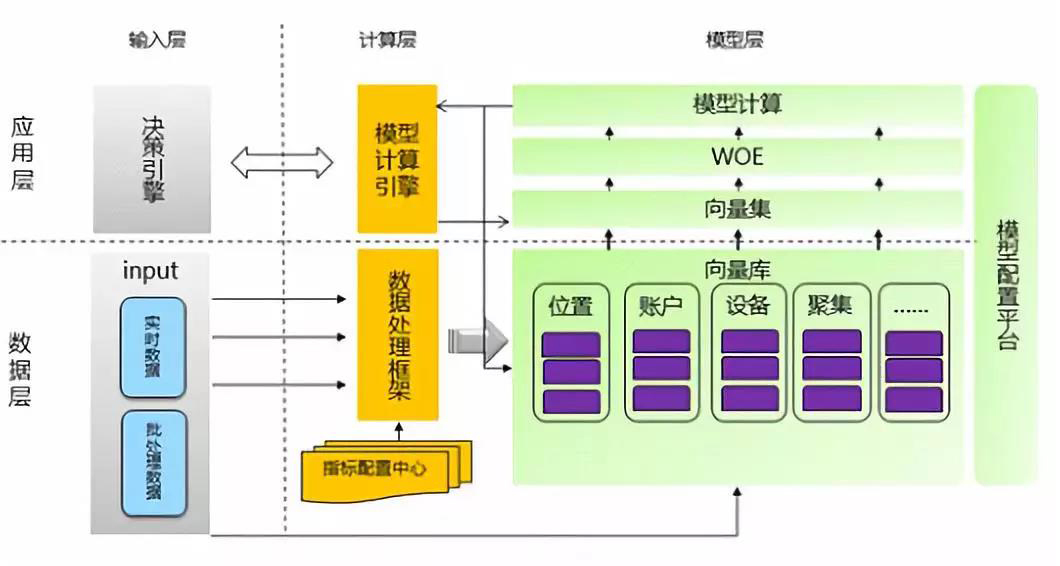
在資料層中,實時資料和批量處理資料進行指標配置後,通過資料處理框架進入到向量庫中,然後進入到向量集中,通過WOE統一轉化將資料全部放入到模型計算引擎中,最後通過決策引擎直接產生結果。
計算機視覺——人臉識別
人臉檢測
基於深度學習演算法模型,模型能準確檢測人臉,精確定位人臉框,並且準確標記人臉輪廓、眼、口、鼻、眉毛等關鍵點。
活體檢測
動作活體通過脣語、搖頭、眨眼等動作識別活體;靜默活體基於人臉特徵、雙目立體視覺等方式實現活體檢測。
人臉比對
基於深度學習演算法模型,通過提取人臉特徵,計算兩張人臉相似度,從而判斷是否同一個人,並給出相似度評分。
人臉檢索
基於深度學習演算法模型,演算法模型對給定的一張照片,與指定人臉庫中的N個人臉進行檢索,找出最相似的一張臉或多張人臉,即1:N人臉檢索。
人臉防偽
有效防止照片、仿生臉、視訊等攻擊行為,並且對複雜背景的攻擊和真人能進行有效識別,實現安全可靠的人臉識別應用。
本文根據安卓綠色聯盟講師王美青在技術沙龍上的分享整理而成。首發於安卓綠色聯盟微信公眾號。