
LSTM 梳理 及 python3 實現
RNN迴圈神經網路,在“時間序列”,“可變長序列到序列” 或“在上下文模型”中有著非常廣泛的應用。現在論文中說到RNN,基本上說的就是LSTM,同時也有GRU用了比LSTM更少的gate和引數,可以達到類似的效果。
本文主要是介紹RNN,LSTM的原理,及舉一個程式的例子來說明如何用TF實現LSTM。
RNN
首先,DNN是輸入feature全連結到下一層的神經元,通過一個linear regression加到神經元,神經元上有一個啟用函式(通常RNN的啟用函式是Sigmod函式,使用ReLU會產生指數爆炸的問題。不過有一篇論文說ReLU訓練RNN比LSTM效果還好。CNN用的是ReLU、leaky ReLU、ELU,maxout、tanh),然後輸出的feature按照同樣的方法堆幾層,最後一個softmax輸出結果。
其中,DNN是instance(基於例項)的一種MDP(馬爾可夫決策過程,即無後效性或無記憶性),只考慮當前狀態,不考慮之前的狀態。但在具體應用時,會發現在處理有些任務時,具有memory的網路才能夠解決問題。比如進行視訊行為分析,一個人的手停在半空中,你說他的手是要往上還是往下?只有結合之前的視訊才能夠更有效做出判斷。所以,給神經網路以記憶。
所以,RNN就把前一個輸出的hinding layer或output儲存起來,在下一次輸入時,把上一次儲存的值輸入進來。如下圖所示:所以上一次的輸出或hinding layer,會影響下一次的輸出,同時會更新儲存的值。

當然,RNN可以有多個隱層,如下圖:不要看它是有這麼多,其實它就是一個網路,表示的是不同的時刻。
同理CPU的流水線,每過一個時刻,各個暫存器的狀態就會更新,這裡的暫存器就是memory,藍色的箭頭。
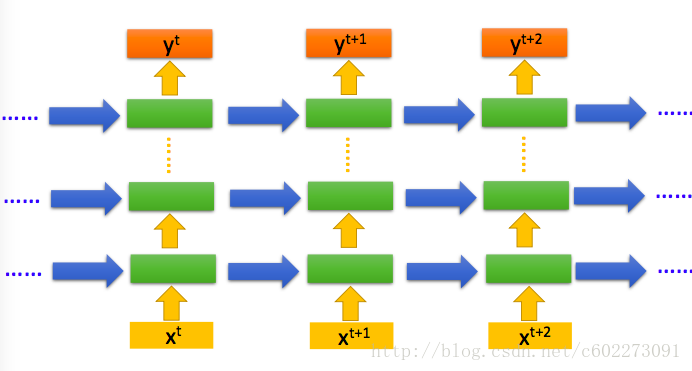
RNN的網路結構還有下圖,其實總結起來就是要儲存memory,但是這裡的RNN一般會儲存上一個狀態的memory,通俗來說就是它只有上一個時刻的記憶。
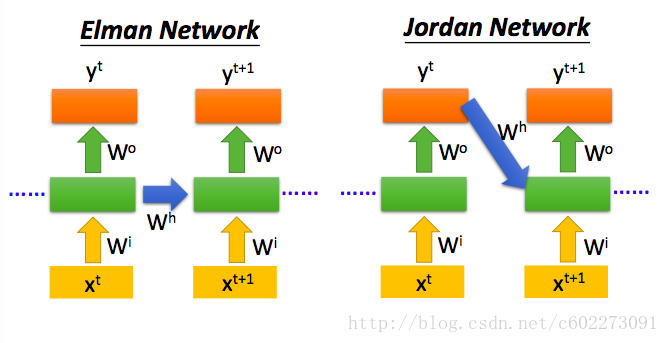
這裡的雙向的RNN訓練時,比如訓練一個sentence auto-encoder,下面的訓練的輸入時正向的,上面的輸入正好和下面的sentence順序相反,為什麼要這麼訓練呢?我覺得這樣的話就使得這個RNN有了prediction的功能。
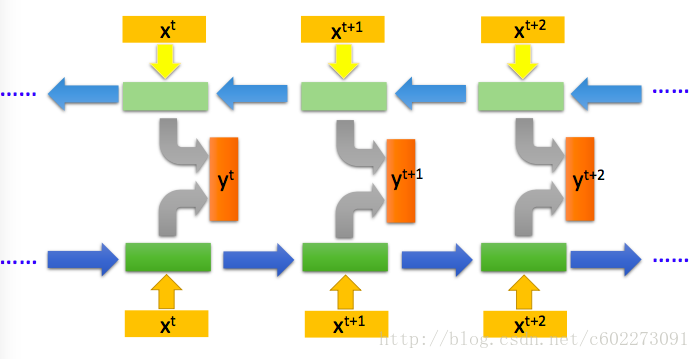
其實熟悉DNN的話,其實就是在DNN的基礎上加入了memory這個東西,同時把memory作為input。但是在training的時候就有了不少技巧。
RNN在訓練的時候,會有gradient vanishing和gradient explode的情況。一個是指數爆炸,一個是後向傳遞的時候引數接近於0,權值沒有被更新。使用LSTM可以解決gradient vanishing的問題,因為memory和input操作都是加法。【7】【8】在RNN的作者訓練RNN的時候,增加了一個叫做Clipping的操作,將梯度限制在一定的範圍內,不讓它超過一定的範圍。
LSTM
LSTM圖例如下 :
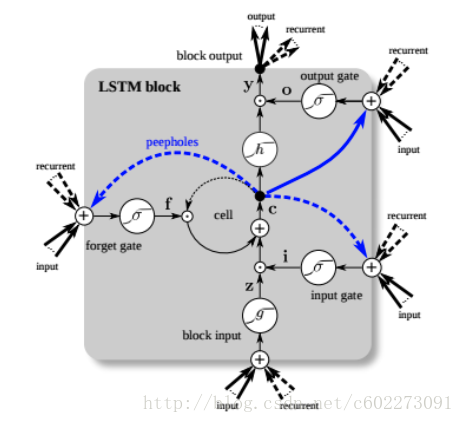
這裡先來把整個框架畫出來:在輸入的地方有一個input gate,來判斷輸入是否有效。gate開啟輸入才會進入memory cell。在與memory gate相連的有一個Forget gate,這裡的作用是,判斷是否把memory置為0,置為0就是Forget。然後有一個輸出Gate,是否對外進行輸出。這些gate的開關都是由神經網路決定的(其實就是由輸入的feature進行了一個linear regression,再輸入到Gate function,某種啟用函式,Sigmoid)。
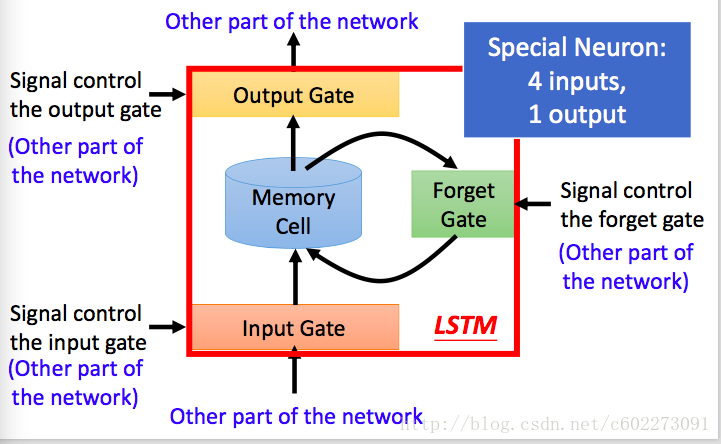
下圖中對memory cell進行了詳細的解釋:zizi,zz,zfzf,zozo是四個gate,由input feature經過linear regression得到。輸入的z通過activation function之後變成了g(z),然後這個g(z)和f(zi)相乘送進了memory cell,得到新的memory:這裡面的c就是memory,f(zf)如果是0,那麼Forget Gate啟動,memory被清空。否則就保留memory。輸出的a受到output gate的控制。 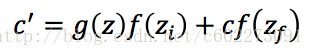
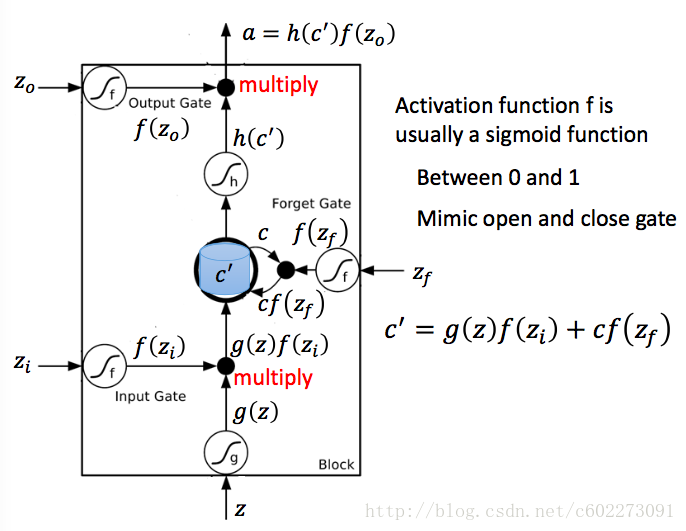
其實通過對比就會發現,LSTM和CNN很像,因為每個gate的input feature也是從最原始的輸入通過linear regression這種線性變化來的。
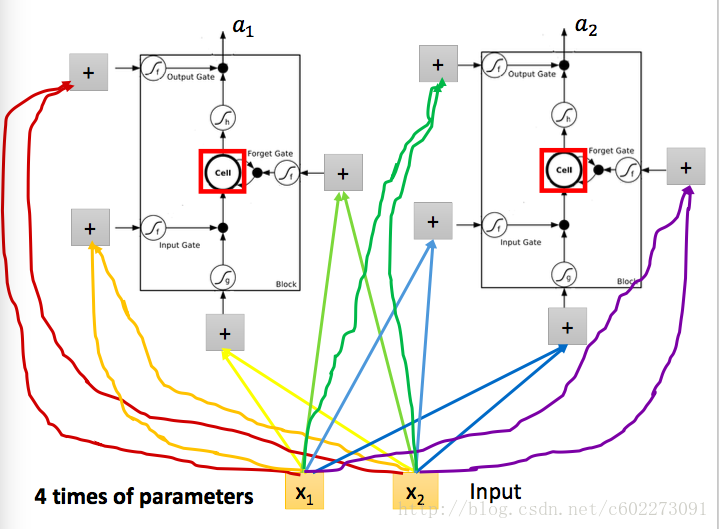
當然實際在計算的時候輸入的不僅僅是有input feature,還有memory,還有memory的輸出。

Example
目前RNN的應用:
- sentiment anlysis 情感分析:輸入一個序列,輸出的是情感,比如對某部電影的評價。
- speech recognition:輸入原始的聲音訊號,輸出的是識別的文字。聲音被分成了多個片段,然後每個片段對應一個字,其中有一個null的字,表示什麼都沒有。
- machine translation:進行機器翻譯,首先是輸入sequence,然後輸入結束後輸出,有終止符表示停止了。
- syntactic parsing:對一句話進行語法組織。
- sequence-to-sequence Auto-Encoder:輸入一句話,然後進行encode,再decoder,把整句話恢復回來。用這樣的方法,可以獲取它的sequence feature,接著可以用來做匹配。如果是聲音,就可以進行聲音的匹配,不過這裡匹配出來的是語義上的聯絡。用這個方法就可以從語料庫裡面選出語義類似的片段,進行可以得出文字。這裡面可以看到有兩個部分,一個部分是LSTM Encoder,一個是LSTM的Decoder,使用Encoder輸入input sequence,LSTM的Decoder就是輸出回答,那麼就是所謂的問答系統。非常神奇~
- image caption generation:輸入圖片,輸出描述的話。
- Attention-based model:(Neural Turing Machine)會把各種資源表示成feature vector儲存在memory之中。然後會訓練一個RNN從memory中選擇合適的專案,然後整合輸出。
- Reading Comprehension:給題目,然後一堆選項,需要找到合適的選項,這些都是可以用LSTM進行訓練。
- Visual Question Answering:比如給你一副圖片,然後提問題,這個人穿什麼顏色的衣服?然後會回答:xxx
- speech Question Answering:比如託福的聽力材料。
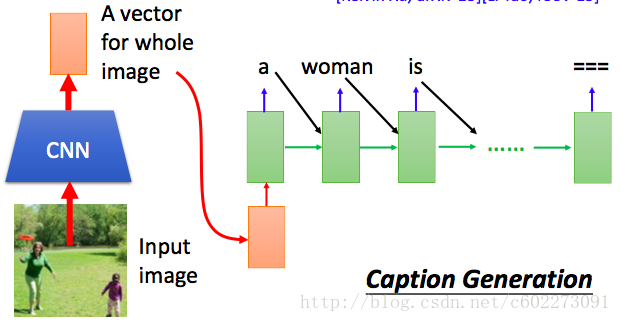
Attention Model:以前的馮諾依曼機架構在人工智慧領域已經是下面的model。

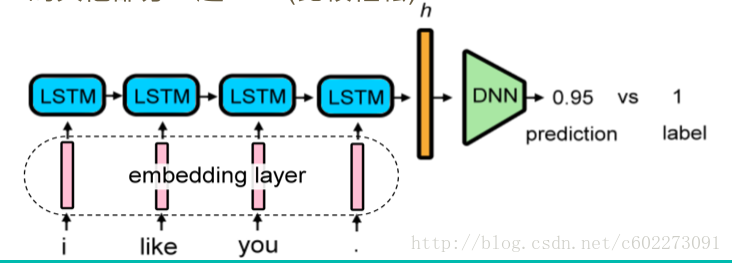
example:首先,進行資料預處理,把每個詞進行word2vec(或叫做word embedding),每個輸入的embedding layer通過LSTM之後,就會獲得整個句子的feature vector,通過一個DNN就可以得出這句話是Negative或是Positive的。其中,還有一種Vector h表示方法就是bag of words,把文字每個詞進行切割,得到每個詞的個數,得到一句話的vector。
在資料中還有沒有標記的資料,可以使用EM演算法,KNN等等進行標記。這裡提供的是使用已經標記好的資料訓練的模型對未標記的資料進行標記。
首先建立一個utils目錄,理由有一個util.py。對資料進行預處理,構建vocabulary等。
import os
import tensorflow as tf
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
import _pickle as pk
# calss to address the data.
class DataManager:
def __init__(self):
self.data = {}
def add_data(self,name,data_path,with_label=True):
print('read data from %s ...' % data_path)
X, Y = [], []
with open(data_path, 'r') as f:
for line in f:
if with_label:
lines = line.strip().split(' +++$+++ ')
X.append(lines[1])
Y.append(int(lines[0]))
else:
X.append(line)
if with_label:
self.data[name] = [X,Y]
else:
self.data[name] = [X]
def tokenize(self, vocab_size):
print('Create new tokenizer')
self.tokenizer = Tokenizer(num_words=vocab_size)
for key in self.data:
print('Tokenizing %s' %key)
texts = self.data[key][0]
self.tokenizer.fit_on_texts(texts)
def save_tokenizer(self, path):
print('Save tokenizer to %s' % path)
pk.dump(self.tokenizer, open(path, 'wb'))
def load_tokenizer(self, path):
print('Load tokenizer from %s' % path)
self.tokenizer = pk.load(open(path, 'rb'))
def to_sequence(self, maxlen):
self.maxlen = maxlen
for key in self.data:
print('Converting %s to sequence ' % key)
tmp = self.tokenizer.texts_to_sequences(self.data[key][0])
self.data[key][0] = np.array(pad_sequences(tmp, maxlen=maxlen))
def to_bow(self):
for key in self.data:
print ('Converting %s to tfidf'%key)
self.data[key][0] = self.tokenizer.texts_to_matrix(self.data[key][0],mode='count')
# Convert label to category type, call this function if use categorical loss
def to_category(self):
for key in self.data:
if len(self.data[key]) == 2:
self.data[key][1] = np.array(to_categorical(self.data[key][1]))
def get_semi_data(self,name,label,threshold,loss_function) :
# if th==0.3, will pick label>0.7 and label<0.3
label = np.squeeze(label)
index = (label>1-threshold) + (label<threshold)
semi_X = self.data[name][0]
semi_Y = np.greater(label, 0.5).astype(np.int32)
if loss_function=='binary_crossentropy':
return semi_X[index,:], semi_Y[index]
elif loss_function=='categorical_crossentropy':
return semi_X[index,:], to_categorical(semi_Y[index])
else :
raise Exception('Unknown loss function : %s'%loss_function)
def get_data(self,name):
return self.data[name]
# split data to two part by a specified ratio
# name : string, same as add_data
# ratio : float, ratio to split
def split_data(self, name, ratio):
data = self.data[name]
X = data[0]
Y = data[1]
data_size = len(X)
val_size = int(data_size * ratio)
return (X[val_size:],Y[val_size:]),(X[:val_size],Y[:val_size])主函式 main.py 如下:
import sys, argparse, os
import keras
import _pickle as pk
import readline
import numpy as np
from keras import regularizers
from keras.models import Model
from keras.layers import Input, GRU, LSTM, Dense, Dropout, Bidirectional
from keras.layers.embeddings import Embedding
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping, ModelCheckpoint
import keras.backend.tensorflow_backend as K
import tensorflow as tf
from utils.util import DataManager
parser = argparse.ArgumentParser(description='Sentiment classification')
parser.add_argument('model')
parser.add_argument('action', choices=['train','test','semi'])
# training argument
parser.add_argument('--batch_size', default=128, type=float)
parser.add_argument('--nb_epoch', default=20, type=int)
parser.add_argument('--val_ratio', default=0.1, type=float)
parser.add_argument('--gpu_fraction', default=0.3, type=float)
parser.add_argument('--vocab_size', default=20000, type=int)
parser.add_argument('--max_length', default=40,type=int)
# model parameter
parser.add_argument('--loss_function', default='binary_crossentropy')
parser.add_argument('--cell', default='LSTM', choices=['LSTM','GRU'])
parser.add_argument('-emb_dim', '--embedding_dim', default=128, type=int)
parser.add_argument('-hid_siz', '--hidden_size', default=512, type=int)
parser.add_argument('--dropout_rate', default=0.3, type=float)
parser.add_argument('-lr','--learning_rate', default=0.001,type=float)
parser.add_argument('--threshold', default=0.1,type=float)
# output path for your prediction
parser.add_argument('--result_path', default='result.csv',)
# put model in the same directory
parser.add_argument('--load_model', default = None)
parser.add_argument('--save_dir', default = 'model/')
args = parser.parse_args()
train_path = 'data/training_label.txt'
test_path = 'data/testing_data.txt'
semi_path = 'data/training_nolabel.txt'
def simpleRNN(args):
inputs = Input(shape=(args.max_length,))
# Embedding layer
embedding_inputs = Embedding(args.vocab_size,
args.embedding_dim,
trainable=True)(inputs)
# RNN
return_sequence = False
dropout_rate = args.dropout_rate
if args.cell == 'GRU':
RNN_cell = GRU(args.hidden_size,
return_sequences=return_sequence,
dropout=dropout_rate)
elif args.cell == 'LSTM':
RNN_cell = LSTM(args.hidden_size,
return_sequences=return_sequence,
dropout=dropout_rate)
RNN_output = RNN_cell(embedding_inputs)
# DNN layer
outputs = Dense(args.hidden_size//2,
activation='relu',
kernel_regularizer=regularizers.l2(0.1))(RNN_output)
outputs = Dropout(dropout_rate)(outputs)
outputs = Dense(1, activation='sigmoid')(outputs)
model = Model(inputs=inputs,outputs=outputs)
# optimizer
adam = Adam()
print ('compile model...')
# compile model
model.compile( loss=args.loss_function, optimizer=adam, metrics=[ 'accuracy',])
return model
def main():
# limit gpu memory usage
def get_session(gpu_fraction):
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_fraction)
return tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
K.set_session(get_session(args.gpu_fraction))
save_path = os.path.join(args.save_dir,args.model)
if args.load_model is not None:
load_path = os.path.join(args.save_dir,args.load_model)
### process data###
#####read data#####
dm = DataManager()
print ('Loading data...')
if args.action == 'train':
dm.add_data('train_data', train_path, True)
elif args.action == 'semi':
dm.add_data('train_data', train_path, True)
dm.add_data('semi_data', semi_path, False)
else:
raise Exception ('Implement your testing parser')
# prepare tokenizer
print ('get Tokenizer...')
if args.load_model is not None:
# read exist tokenizer
dm.load_tokenizer(os.path.join(load_path,'token.pk'))
else:
# create tokenizer on new data
dm.tokenize(args.vocab_size)
if not os.path.isdir(save_path):
os.makedirs(save_path)
if not os.path.exists(os.path.join(save_path,'token.pk')):
dm.save_tokenizer(os.path.join(save_path,'token.pk'))
# convert to sequences
dm.to_sequence(args.max_length)
# initial model
print ('initial model...')
model = simpleRNN(args)
print (model.summary())
if args.load_model is not None:
if args.action == 'train':
print ('Warning : load a exist model and keep training')
path = os.path.join(load_path,'model.h5')
if os.path.exists(path):
print ('load model from %s' % path)
model.load_weights(path)
else:
raise ValueError("Can't find the file %s" %path)
elif args.action == 'test':
print ('Warning : testing without loading any model')
# training
if args.action == 'train':
(X,Y),(X_val,Y_val) = dm.split_data('train_data', args.val_ratio)
earlystopping = EarlyStopping(monitor='val_acc', patience = 3, verbose=1, mode='max')
save_path = os.path.join(save_path,'model.h5')
checkpoint = ModelCheckpoint(filepath=save_path,
verbose=1,
save_best_only=True,
save_weights_only=True,
monitor='val_acc',
mode='max' )
history = model.fit(X, Y,
validation_data=(X_val, Y_val),
epochs=args.nb_epoch,
batch_size=args.batch_size,
callbacks=[checkpoint, earlystopping] )
# testing
elif args.action == 'test' :
raise Exception ('Implement your testing function')
# semi-supervised training
elif args.action == 'semi':
(X,Y),(X_val,Y_val) = dm.split_data('train_data', args.val_ratio)
[semi_all_X] = dm.get_data('semi_data')
earlystopping = EarlyStopping(monitor='val_acc', patience = 3, verbose=1, mode='max')
save_path = os.path.join(save_path,'model.h5')
checkpoint = ModelCheckpoint(filepath=save_path,
verbose=1,
save_best_only=True,
save_weights_only=True,
monitor='val_acc',
mode='max' )
# repeat 10 times
for i in range(10):
# label the semi-data
semi_pred = model.predict(semi_all_X, batch_size=1024, verbose=True)
semi_X, semi_Y = dm.get_semi_data('semi_data', semi_pred, args.threshold, args.loss_function)
semi_X = np.concatenate((semi_X, X))
semi_Y = np.concatenate((semi_Y, Y))
print ('-- iteration %d semi_data size: %d' %(i+1,len(semi_X)))
# train
history = model.fit(semi_X, semi_Y,
validation_data=(X_val, Y_val),
epochs=2,
batch_size=args.batch_size,
callbacks=[checkpoint, earlystopping] )
if os.path.exists(save_path):
print ('load model from %s' % save_path)
model.load_weights(save_path)
else:
raise ValueError("Can't find the file %s" %path)
if __name__ == '__main__':
main() 如果是訓練模型,那就是:python main.py train –cell LSTM
如果加入semi-supervised learning,那就是:python main.py semi –load_model