
深度長文教你徹底掌握C++/C指標(一):基石
一.基礎
C++或者C裡面最容易讓人糊塗應該是指標了,不管是初學者甚至是有經驗的童鞋有時候在用指標的時候也會出現一些很隱蔽的錯誤.
指標本身就是一個很繞的概念,而指標又能夠和很多的結構比如陣列(二維陣列),字串,記憶體分配和管理等等一些聯絡起來變成更加繞的概念.所以基礎不好的同學常常會犯一些很無厘頭的錯誤,但是高手也會犯錯誤,而且更加隱蔽.
接下來所有的文章內容並不能夠保證你能夠完完全全避免開發中的錯誤,但是文章的目標是幫助很多童鞋對於指標概念做一個系統性的歸納.減少犯錯誤的機率.或者是幫助剛剛入門的boy更加快速深入的理解指標,把基礎打得紮實一點.
恩,很多人都說指標很難,那為什麼還要學指標呢?對於這樣的問題,拒絕回答.
Ⅰ.記憶體和地址
我們已經很熟悉一些基本的儲存單位了,比如一個bit(位)用儲存0或者1.也可以把幾個bit合起來表示更大的數字,比如一個byte(位元組)就包含了8個bit.這些都是很基礎很簡單的東西.然後我們可以把計算機的記憶體想象成一個位元組陣列,記憶體中的每一個地址表示一個位元組.

每個位元組中都能夠儲存一定位數的內容,因此,每個位元組都能夠通過一些地址來標識.有時候,一個位元組不夠,怎麼辦呢?那麼就同時用很多個位元組來表示,比如一個int在我的系統裡面就用了4個位元組。
下面的圖是上面那幅圖片每兩個位元組合併在一起之後樣子.這個因為是兩個位元組合併,所以它成為比一個位元組更大的記憶體單位(廢話),能夠儲存的資訊就更多(廢話).但是雖然一個字是兩個位元組合併的,但是它仍然只包含一個地址,也就是說,合併之後只需要一個地址來找到合併之後的記憶體.

因此,我們可以得到:
1.記憶體中的每個位置都由一個獨一無二的地址表示.
2.記憶體中的每個位置都包含一個值.
通俗一點,我們可以通過一個地址,來找到記憶體中的某個具體位置,然後訪問到(得到)該位置的值(允許的話).這就是記憶體和地址簡單的思想.
Ⅱ.指標含義與建立方式
指標這個名字確實折磨過很多人,這個名字是個好名字,同時也是一個非常不好的名字. 說它好,是因為指標這個東西很形象的體現了它的功能:指標指標,指到某個地方某個位置.非常形象. 它不是個好名字是因為她的名字有時候掩蓋了它的真實含義.一般來說,指標是一個其值為地址的變數。(就是一個儲存地址的變數)
所以,要養成一種條件反射,看到指標首先不是想到他能夠指向哪裡,而是想到這個變數存放的是一個地址,是這個地址指向哪里哪里
反覆的把上面的概念消化之後,我們就來看兩個基本的運算子:&(取址運算子)和*(間接訪問運算子/解引用指標)
首先是&運算子:當它後面跟一個變數名的時候,給出這個變數名的地址.
#include <iostream>
using namespace std;
int main()
{
int a=5;
double b=10.4;
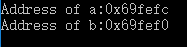
cout<<"Address of a:"<<&a<<endl;
cout<<"Address of b:"<<&b<<endl;
}
至於*運算子:就是後面跟一個指標的時候,得到指標指向的記憶體中的內容.
#include <iostream>
using namespace std;
int main()
{
int a=5;
double b=10.4;
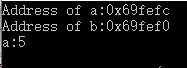
cout<<"Address of a:"<<&a<<endl;
cout<<"Address of b:"<<&b<<endl;
cout<<"a:"<<*(&a)<<endl;
}
通過上面的例子你會發現,這裡輸出的地址是16進位制的整形.其實事實上,在大多數系統的內部,指標所存的地址值一般是一個無符號的整數。但是,這並不代表指標和整形有一樣的運算規則。指標型別是一種新的型別,而不是一種整數型別。ANSI專門為指標提供了%p輸出格式
理解上面兩個基本的運算子之後,就可以正式開始講指標的建立了.
宣告指標的模板:
指向地址的資料型別 * 指標變數名;其中,*號必須帶,用以表明現在建立的是一個指標型別的變數.同時,當你看到建立變數的語句中帶有星號*的話,那麼說明那個變數必定是一個指標變數!
是不是很簡單!舉一個例子進一步來理解上面那個的含義.比如我想建立一個指標變數(存放地址的變數),這個指標(地址)是指向一個儲存整形的記憶體.那麼我就可以寫為:int * leo;同理,指向char的我可以寫成char * c;其實是很簡單的.
這裡結合前面的內容,簡單的寫一個例子,並且介紹一些寫法.(最開始讓初學者迷惑的地方就是這裡了,因為建立時候的*號,解除指標時候的*號,各種符號混在一起,一般就直接懵逼了.但是要是好好掌握一些經驗結論,這裡很容易過去.)
#include <iostream>
using namespace std;
int main()
{
int a=5,b=6,c=7,d=8;
double e=3.1415;
//單獨賦值,並且*和p_a緊挨著
int *p_a=&a;
//多個賦值(既有指標,又有普通變數)
int * p_b=&b,* p_c=&c,*p_d=&d,temp=100;
//單獨賦值,double型別
double * p_e=&e;
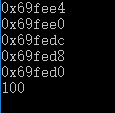
cout<<p_a<<endl<<p_b<<endl<<p_c<<endl<<p_d<<endl<<p_e<<endl;
cout<<temp<<endl;
}
上面這個例子有一些可以提煉的經驗:
首先,就是建立指向int或者double的指標的建立方式,這個前面都講了很多次了.在這個例子裡面也可以很容易的找到,所以這裡就不囉嗦了.
然後就是建立時候的寫法.比如 int *p_a=&a;這句話中,*號是緊挨著p_a的,而在int * p_b=&b,* p_c=&c,*p_d=&d,temp=100; 這句話中,*號是可以不挨著p_b和p_c的.也就是說,建立指標變數的時候,星號的位置是很自由的.只要是出現了星號,而不管中間是不是有空格,我們便認為,這算是建立了一個指標變數.
在別人寫的程式碼中,你會看到很多的寫法,其實本質就是這樣.比如有些人喜歡寫成int* p_a=&a;在這裡,*號緊挨著int,因為有人理解為int的指標型別即int*.所以,寫法這麼多,初學者肯定是會迷惑的,記住前面的經驗,這樣就見怪不怪了.
接下來,還是在int * p_b=&b,* p_c=&c,*p_d=&d,temp=100;這句話裡面,最後接了一個temp=100,千萬不要也把temp也當做了一個指標變數,他只是一個普通的變數.也就是說,同一句話裡面,可以混合多種型別的賦值,指標的帶*號,普通的不帶*號.
Ⅲ.使用指標
使用指標的方式有很多,我們這裡談談最基礎的,後面會更加深入的講指標的使用.前面已經講過了指標的建立,接下來主要是講指標的初始化問題和賦值以及解除引用等等問題.
首先是初始化問題.在前面的那一個例子中,我們在建立指標的時候都順便初始化了,那是不是建立指標就一定要初始化?肯定不是!建立指標的時候也可以不初始化.因為有時候你建立一個指標只是為了後續的工作,根本沒有東西拿來初始化.那麼到現在,我們解決了第一個問題,那就是建立指標可以初始化也可以不初始化,.那麼你肯定會說,這麼簡單為什麼要單獨拿出來講?是因為後來的某些操作是要考慮是否初始化的問題的.好了,不繞彎了,這裡的操作主要是講間接訪問(解引用指標)帶來的一些問題.不多說,直接上例子.
#include <iostream>
using namespace std;
int main()
{
int num=5;
//p_a沒有初始化
int *p_a1,*p_a2;
cout<<"p_a1:"<<p_a1<<endl;
cout<<"p_a2:"<<p_a2<<endl;
int *p_b=#
cout<<"p_b:"<<p_b<<endl;
//同類型指標可以賦值
//沒有初始化的指標依然可以被賦值(地址)
p_a1=p_b;
p_a2=#
cout<<"changed p_a1:"<<p_a1<<endl;
cout<<"changed p_a2:"<<p_a2<<endl;
}
一句一句來分析這個例子.首先我們建立了一個整形,值為5,然後我們建立了兩個指向int型別的指標p_a1,P_a2,但是我們沒有初始化.從最後的執行結果來看,指標不初始化是可行的.然後建立了一個指標p_b並且初始化了,所以從結果來看,就是num的地址.
接下來有兩句:p_a1=p_b; p_a2=#
前面那句是直接把p_b這個指向int型別的指標直接賦給了p_a1這個也是指向int型別的指標,那麼從效果上面來看,相當於p_a1和p_b指向同樣的地址…..好了,不裝逼了,因為指標就是儲存地址的嘛,其實就是把這個變數中儲存的地址賦給了另外一個變數…..非常簡單.
後面第二句就是說,即使不初始化,我還是能夠接收地址.(類比int n;n=5).
所以總結起來就是即使沒有初始化,我依然能夠兩個指標之間賦值(型別肯定要一樣啦)和接受地址.也沒有什麼困難的.那麼接著看.
把上面的程式碼小小的改動一些,程式碼變成下面這樣.
#include <iostream>
using namespace std;
int main()
{
int num=5;
//p_a沒有初始化
int *p_a1,*p_a2;
cout<<"p_a1:"<<p_a1<<endl;
cout<<"p_a2:"<<p_a2<<endl;
*p_a1=12;
cout<<*p_a1<<endl;
}這裡就加了一句*p_a1=12;這句話是很危險的.我們建立了一個指向int的指標,但是並沒有初始化,也就是說,指標會得到一個隨機的地址(至少大部分系統上面是這樣),可建立指標的過程並不包含對於某個整形記憶體上空間的開闢.
*p_a1=12;的過程就是把12這個整形放到p_a1指向的記憶體的過程.但是空間都沒有開闢,怎麼放呢?所以這個語句最終是不是執行成功都取決於運氣.不同的系統上面可以有不同的結果.但是這樣的話就算是執行成功了又有什麼意義呢?
所以,其他的都不說,至少在解引用指標的時候,你需要保證你的指標被正確的初始化或者正確的被賦過某個地址.不然,那樣的解引用指標操作無意義且危險.
重要:
既然前面談到了解引用指標(間接訪問),那就再來說說指標常量與指標的強制轉化.
假如我們想在一個地址500存放一個整數100,沒錯,我們已經知道這個地址是500了,所以我們就能夠這麼賦值
*500=100;這句話的意思是很明確的,先把地址500解引用然後把100放進這個記憶體.但是這句話是錯的,因為前面說過指標型別是一種特殊的型別.但是我們這裡的500就是一個很普通的整形.他是能夠表示500這個地址沒有錯,但是它的型別不適合.因此,我們要把這個普通的整形強制轉換為指向整形的指標型別.因此可以這樣寫
*(int *)500=100其實使用這個的機會很少,但是並不意味這個不重要,首先在某些硬體問題裡面確實是想訪問某些硬體上面特定的地址的時候我們可以用這個方法.後面講到記憶體管理的時候,也會回來這裡.
Ⅳ.指標運算
指標的運算有算術運算和關係運算(比較大小等等),但是在這裡僅僅是提一下,因為這部分的內容是和後面指標與陣列有關係的.在後面指標與陣列會單獨講這些.
Ⅴ.NULL指標和void*
有很多對於指標不是很熟悉的童鞋在上資料結構課的時候一般是很懵逼的,因為用C講資料結構的時候,涉及到很多的記憶體開闢回收,以及指標問題(鏈式結構).然後很多人沒有學好不是因為邏輯能力差,而是因為在一些程式碼或者是虛擬碼中對於指標的認識模稜兩可.以至於本來程式碼是學習資料結構思想的好工具,變為了學習資料結構的負擔.
首先先講NULL指標.
NULL指標是一種非常特殊的指標(廢話,不然單獨說它幹嘛?),不指向任何東西.表示不指向任何東西的指標(哦,感覺好厲害的樣子).但是事實上面,這種技巧非常有用.(當你被連結串列虐的時候就知道了).
我們怎麼把一個指標變為NULL指標呢?很簡單,賦給這個指標一個0就行了.不用轉化,就是整形的0.同樣,直接賦NULL也是行的.看下面的例子.
#include <iostream>
using namespace std;
int main()
{
//測試NULL是不是0
if(NULL==0)
cout<<"yes"<<endl;
//轉化為NULL指標
int *p_a=0;
int *p_b=NULL;
}
例子很簡單,就不解釋了.
有一個非常重要的是,因為NULL不指向任何地方,所以,也就肯定不能夠解引用了.這點一定要注意.因為連地址都沒有,怎麼得到不存在的地址中的值呢?所以要是想你的程式健壯,最好是在解引用之前加一個判斷是否為NULL指標的步驟,要是你有足夠的信心以後都不會有問題,那麼不加也罷.
下面這個例子是當我試圖對一個NULL指標解引用之後的程式執行情況.(就是上面那個例子加了一句話而已)
#include <iostream>
using namespace std;
int main()
{
//測試NULL是不是0
if(NULL==0)
cout<<"yes"<<endl;
//轉化為NULL指標
int *p_a=0;
int *p_b=NULL;
//試圖解引用
cout<<*p_a<<endl;
}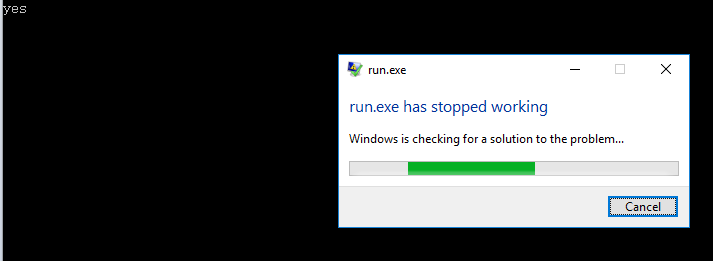
直接崩了,其實也挺好,至少比找不到的隱形錯誤要好.
前面的例子中有一句是判斷NULL==0的,這裡需要注意一下,NULL是一個預處理的變數,值為0,在標頭檔案cstdlib中定義,(我這裡並沒有顯式載入也能夠用),因此用到NULL這個預處理變數的時候,儘量帶上cstdlib標頭檔案,規範一點,避免不必要的錯誤.
說到這裡,其實你反而應該疑惑了,我們前面已經說過了,指標存放的是一個地址.一般來說,地址是整形沒錯,但是它是一種新的型別來表示地址.和整形並不能夠相容或者運算.但是當使用0來表示空指標的時候,我們便會疑惑,0到底是整形常量還是一個指標常量?
因此,在C++11中,新引入了一種特殊型別的字面值nullptr來初始化指標為空指標.他能夠被轉換成任何型別的指標.
#include <iostream>
int fun(int num)
{
return num+10;
}
int main()
{
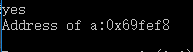
//表示式0==nullptr為真值
if(0==nullptr)
std::cout<<"yes"<<std::endl;
int a=5;
int *p=nullptr;
p=&a;
std::cout<<"Address of a:"<<p<<std::endl;
return 0;
}
講到現在,發現前面很多的錯誤都是由於解引用沒有初始化的指標引起來的.所以,這裡提個建議,就是儘量定義了物件之後再定義指向這個物件的指標,對於不清楚的指向哪裡的指標,一律初始化為nullptr(C++11)或者NULL(0).之後再判斷是否指向物件再進行相應的操作.
接下來講void*.
Void*是一種特殊型別的指標,能夠用來存放任何型別物件的地址.通俗來說,就是我不知道這個指標指向的是什麼型別的物件.
要是還是理解不了那就上例子:
#include <iostream>
int fun(int num)
{
return num+10;
}
int main()
{
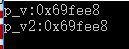
double x=25.5;
//普通指標的話型別要嚴格保證
double *p=&x;
//void* 型別可以接受任意型別物件地址
void *p_v=&x;
void *p_v2=p;
std::cout<<"p_v:"<<p_v<<std::endl;
std::cout<<"p_v2:"<<p_v2<<std::endl;
}
Void *暫時瞭解到這裡就行了,後面記憶體分配的時候還會專門和他打交道.
Ⅵ.指標的指標
指標的指標就是指向指標的指標.再多講就繞暈了.直接看定義和例子吧.
#include <iostream>
int main()
{
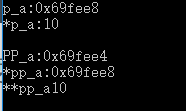
int a=10;
int *p_a=&a;
int **pp_a=&p_a;
std::cout<<"p_a:"<<p_a<<std::endl<<"*p_a:"<<*p_a<<std::endl;
std::cout<<std::endl;
std::cout<<"PP_a:"<<pp_a<<std::endl<<"*pp_a:"<<*pp_a<<std::endl<<"**pp_a"<<**pp_a<<std::endl;
}
通過這個例子,我們發現其建立方式也是和普通指標的建立方式是差不多的,除了建立時候的兩個星號**.那建立指標必定需要指標型別,指標型別怎麼選擇呢?通俗一點說,就是跟著前面的走:我們發現建立整形時候使用的是int,比如這裡的int a=10;.那我們建立指向a的指標的時候,肯定必須也要是int了,比如這裡的int *p_a=&a;.最後建立指標的指標的時候,也就用int了.比如這裡的int **pp_a=&p_a; .並不困難
另外一個就是解引用的時候,帶上兩個星號,就回到的最開始的那個變數.這麼說有點模糊.詳細來說,**pp_a因為*的從右向左的結合性,這個表示式可以寫成*(*pp_a),那麼我們知道pp_a存放的是p_a的地址,*pp_a就是表示p_a這個地址中存放的內容即a的地址(不能暈!!!).那麼*(*pp_a)就相當於*p_a或者a.
至此,基本的概念部分就結束啦.