
機器學習中的高斯過程
轉自:http://www.datalearner.com/blog/1051459170229238
關於高斯過程,其實網上已經有很多中文部落格的介紹了。但是很多中文部落格排版實在是太難看了,而且很多內容介紹也不太全面,搞得有點雲裡霧裡的。因此,我想自己發表一個相關的內容,大多數內容來自於英文維基百科和幾篇文章。
來源1:https://en.wikipedia.org/wiki/Gaussian_process
來源2:Gaussian Processes in Machine Learning
來源3:Gaussian Processes for Regression and Classification: A Quick Introduction
我們還是先來個引言吧。隨機過程是碩士研究生的課程了,很不幸,我就掛了。然而現在還是無可避免繼續接觸,只能說命裡有時躲不掉啊 。隨機過程英文是stochastic
process或者random process。在概率和統計中,隨機過程是一個統計過程,它可以理解成一組隨機變數的變化。簡單說就是,有很多點,每個點都是一個隨機變數,很多個隨機變數點有次序的在一起就成了隨機過程。所以可以說隨機過程是一個關於時間t(連續區間可以是時間也可以是空間之類的)分佈。每個t都有個對應的隨機變數。當t是離散的時候,它就是一組隨機變數的序列,比如markov chain。那麼高斯過程就可以理解成每個t的值都是來自於一個高斯分佈。高斯過程很重要,原因是它已經被研究的很成熟了,如果我們把問題用高斯過程建模,那麼很多相關知識我們就已經知道了。高斯過程的應用有很多,可以作為貝葉斯推斷的先驗,也可以用來做迴歸和分類。
。隨機過程英文是stochastic
process或者random process。在概率和統計中,隨機過程是一個統計過程,它可以理解成一組隨機變數的變化。簡單說就是,有很多點,每個點都是一個隨機變數,很多個隨機變數點有次序的在一起就成了隨機過程。所以可以說隨機過程是一個關於時間t(連續區間可以是時間也可以是空間之類的)分佈。每個t都有個對應的隨機變數。當t是離散的時候,它就是一組隨機變數的序列,比如markov chain。那麼高斯過程就可以理解成每個t的值都是來自於一個高斯分佈。高斯過程很重要,原因是它已經被研究的很成熟了,如果我們把問題用高斯過程建模,那麼很多相關知識我們就已經知道了。高斯過程的應用有很多,可以作為貝葉斯推斷的先驗,也可以用來做迴歸和分類。
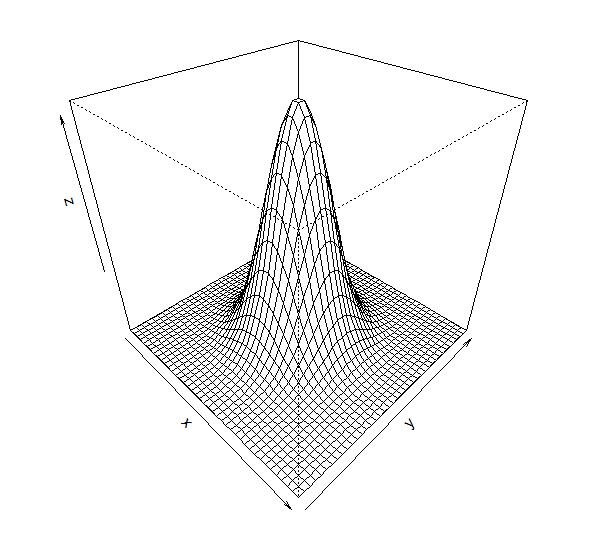
我們用如下的R語言程式碼生成了一個二維高斯分佈。
x<-y<-seq(-4,4,length=40)f<-function(x,y){(exp(-0.5*x^2-0.5*y^2))/(2*pi)}z<-outer(x,y,f)persp(x,y,z,theta=45,phi=35)
1、高斯過程
定義:高斯過程是指隨機變數的一個集合,其中任意有限個樣本的線性組合都有一個聯合高斯分佈。
一個高斯過程是由均值函式m(x)和協方差函式k(x,x∗)確定的。它可理解成高斯分佈的一個生成過程(或者叫泛化?generalization)。高斯分佈的均值和協方差是向量和矩陣(意思就是多維高斯分佈的均值和方差是確定的值,比如均值是(0.1,0.2,0.5)。),而高斯過程的均值和方差則分別是均值函式和協方差矩陣函式。我們有如下公式(1):
f∼gp(m,k)
它的含義是函式f是一個高斯過程,其均值函式為m,協方差函式為k。
我們這裡將簡單說一下從分佈到隨機過程的生成。其實就是說明一下怎麼把高斯過程理解成一個分佈。來自高斯分佈的一個向量中的單個隨機變數的索引是它們在向量中的位置。對於高斯過程來說,隨機函式f(x)的引數x就是索引集合,每個輸入的x都與隨機變數f(x)關聯,也就是這個函式在這個位置上的值。為了方便表示,我們舉個例子,假設x的取值是自然數(也就是1,2,..,n),同時這些值也就是索引。考慮如下的高斯過程:
f∼gp(m,k)
其中,m(x)=41x2,k(x,x∗)=exp(−21(x−x∗)2),(2)
為了理解這個過程,我們可以從函式f中抽取樣本。為了只處理有限情況,我們要求f是有限的。我們如何抽取樣本呢?給定x的值我們可以利用公式(2)來估算均值向量和協方差矩陣(下面是公式3)。
μi=m(xi)=41x2,i=1,...,n
∑ij=k(xi,xj)=exp(−21(xi−xj)2),i,j=1,...,n.
為了區別隨機過程和分佈,我們使用m和k表示過程,μ和∑表示分佈。我們現在可以從這個分佈中產生一個向量(公式4)。
f∼N(μ,∑)
我們可以使用matlab畫出f的影象(如圖1所示):
xs =(-5:0.2:5)’; ns = size(xs,1); keps =1e-9;m =inline(’0.25*x.^2’);K =inline(’exp(-0.5*(repmat(p’’,size(q))-repmat(q,size(p’’))).^2)’);fs = m(xs)+ chol(K(xs,xs)+keps*eye(ns))’*randn(ns,1);plot(xs,fs,’.’)