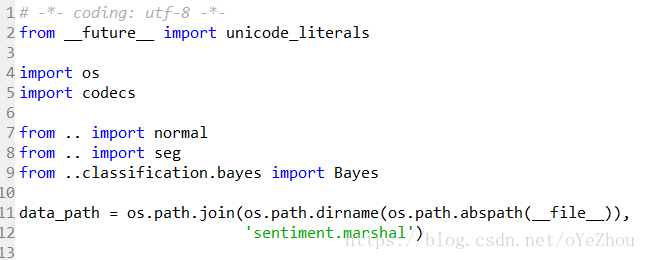
snownlp:自定義訓練樣本與模型儲存
snownlp包,是中文自然語言處理的一個Python包,可以用來處理分詞、情感分析等。
安裝該包之後,在各個功能目錄下預設會有一個訓練好的模型,當我們呼叫諸如情感分析的功能時,會使用該模型進行情感預測。然而,如果我們有自己的語料庫可以用來訓練,則可以大大提高預測的準確率。
我們現在從該包的檔案儲存入手,來看一看它是如何儲存並應用模型的。
1、找到snownlp包的安裝目錄
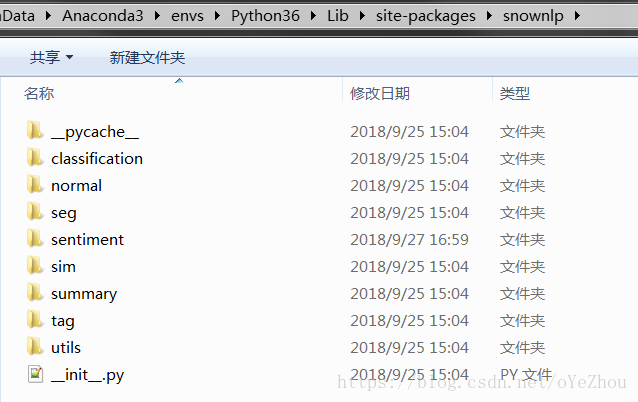
本人是在Anaconda上安裝的,路徑如上圖所示。該包下包含了多個資料夾,其中seg、sentiment、tag分別代表:分詞、情感分析、詞性標註。這三個功能是可以通過訓練自己提供的語料來制定與自己行業更為貼近的模型的。
下面以情感分析模組為例,來詳細探究其如何訓練與儲存模型的。
2、情感分析語料與模型檔案
開啟sentiment資料夾,可以看到裡面有兩個txt檔案:neg.txt、pos.txt,這兩個檔案分別為消極情緒語料、積極情緒語料。
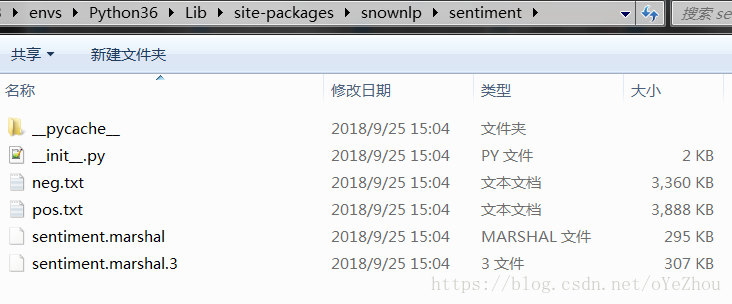
還有一個sentiment.marshal和一個sentiment.marshal.3檔案,該檔案均為通過預設語料訓練得到的模型,其區別在於前者是Python3版本之前的序列化檔案,後者是Python3版本的序列化檔案。關於這一點,我們可以從原始碼中找到答案:可以看到,如果當前的python版本為3,則在檔名後面新增字尾“.3”。
class Bayes(object): ... def save(self, fname, iszip=True): d = {} d['total'] = self.total d['d'] = {} for k, v in self.d.items(): d['d'][k] = v.__dict__ if sys.version_info[0] == 3: fname = fname + '.3' if not iszip: marshal.dump(d, open(fname, 'wb')) else: f = gzip.open(fname, 'wb') f.write(marshal.dumps(d)) f.close() ...
3、模型訓練與儲存
我們現在已經知道了模型是從何處呼叫訓練資料,以及將序列化的模型儲存在何處了,接下來看看如何呼叫相關方法來訓練我們自己的語料並儲存訓練好的模型。
sentiment提供了訓練和儲存的方法:
from snownlp import sentiment
sentiment.train('neg.txt','pos.txt')通過指定你自己的樣本資料,來訓練模型,這個過程及其漫長(取決於你的語料庫大小)。
訓練好之後,即可利用save方法將模型儲存起來:
sentiment.save('sentiment.marshal')儲存過程將第2部分的原始碼,會根據當前的Python版本儲存不同的字尾。
4、使用自己訓練的模型
我們可以通過修改sentiment目錄下__init__.py檔案中的data_path,來指定我們自己的模型路徑,這樣在以後匯入snownpl.sentiment時,即可直接使用預測功能,來判斷目標的情感值了。