
hadoop工作原理
什麼是hadoop?
Hadoop無非就是:HDFS(檔案系統),yarn(任務調配),mapReduce(程式設計模型,大資料並行運算),我們安裝完hadoop就已經包括了以上;
Hadoop叢集其實就是HDFS叢集,說到HDFS,下面來談談什麼是HDFS
HDFS:其實就是個檔案系統,和fastDFS類似,像百度雲,阿里雲等就是個檔案儲存系統,當然一般如果僅僅是為了用來儲存檔案的話直接fastDFS這個就已經夠了,HDFS目的不單單是用來儲存檔案這麼簡單,它還涉及分散式計算等。
HDFS工作原理,用文字有點難以表達,那麼我就直接畫個圖吧:
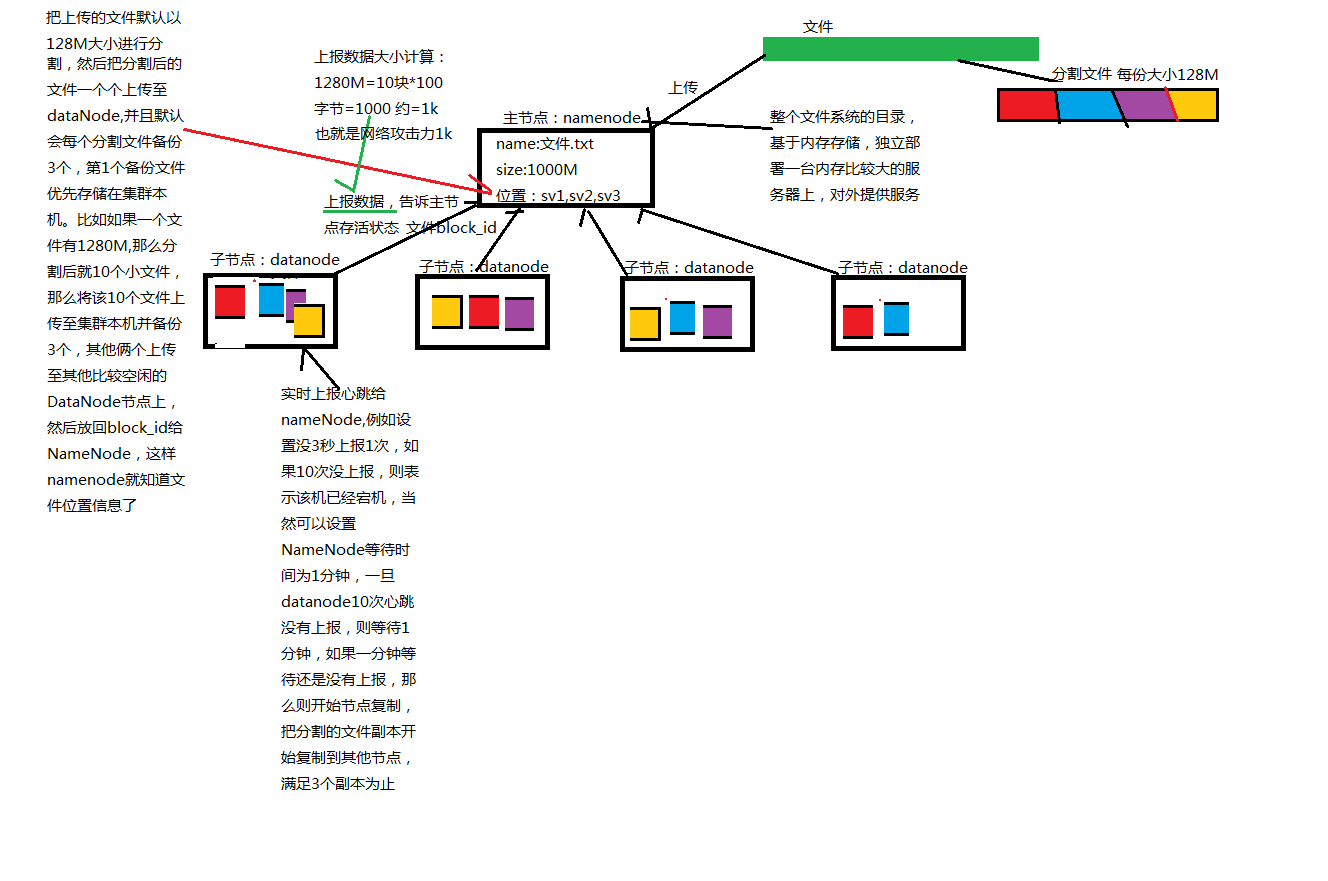
HDFS分有NameNode和DataNode,NameNode是整個檔案系統目錄,基於記憶體儲存,儲存的是一些檔案的詳細資訊,比如檔名、檔案大小、建立時間、檔案位置等。Datanode是檔案的資料資訊,也就是檔案本身,不過是分割後的小檔案。上面圖已經有做了介紹了,這裡就不再贅述了。
Yarn:是一種新的 Hadoop資源管理器,它是一個通用資源管理系統,可為上層應用提供統一的資源管理和排程,它的引入為叢集在利用率、資源統一管理和資料共享等方面帶來了巨大好處。
MapReduce:MapReduce是一種程式設計模型,用於大規模資料集(大於1TB)的並行運算。概念"Map(對映)"和"Reduce(歸約)",是它們的主要思想,都是從函數語言程式設計語言裡借來的,還有從向量程式語言裡借來的特性。它極大地方便了程式設計人員在不會分散式並行程式設計的情況下,將自己的程式執行在分散式系統上。當前的軟體實現是指定一個Map(對映)函式,用來把一組鍵值對對映成一組新的鍵值對,指定併發的Reduce(歸約)函式,用來保證所有對映的鍵值對中的每一個共享相同的鍵組。
Mapreduce工作原理如下圖:
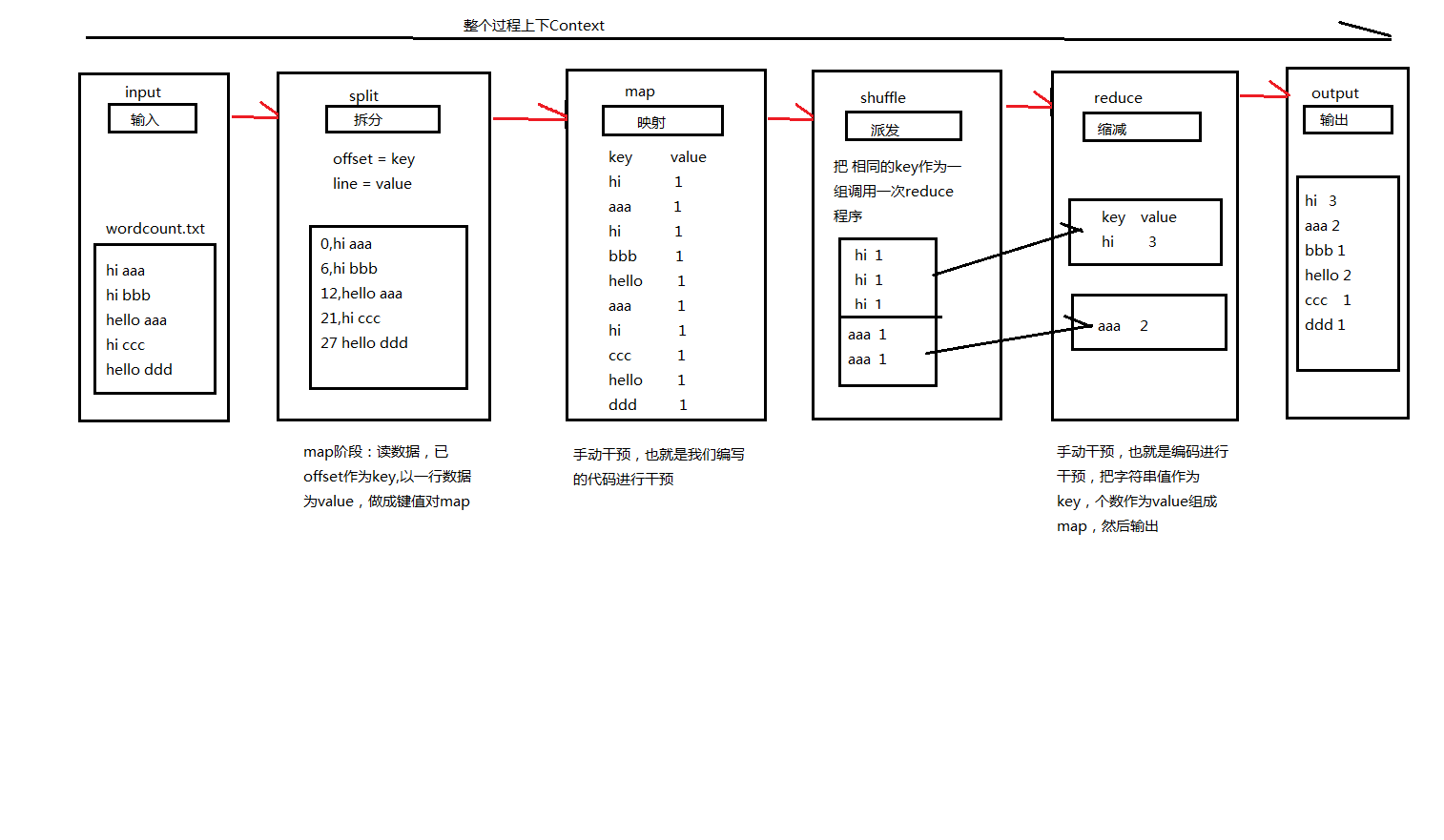
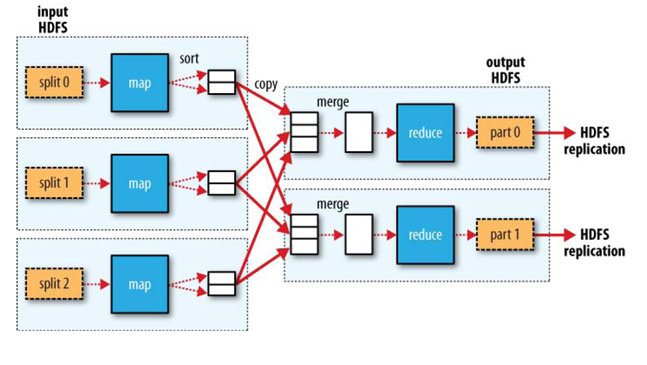
MapReduce所編寫好的程式將跑在各個DataNode上,這裡有個概念就是計算向資料移動,也就是DataNode的資料檔案儲存在這裡,我的程式傳送到DataNode節點上去讀取資料和分析資料就好了。期間會有出現各個DataNode之間進行資料傳送,比如說節點DataNode1進行這臺機讀取資料時進行shuffle時需要把相同的key作為一組呼叫一次reduce,那麼如果這時當然會有一些同key的在其他節點DataNode上的,所以就需要進行資料傳送。Input這裡的wordcount.txt就是DataNode上的檔案資料。Split階段是MapReduce一定會執行的,這是它的規則,而map階段就是我們必須進行手動干預的,也就是編碼對資料進行分析,分析成map檔案,然後再shuffle階段中自發進行資料派送,規則是以同樣的key為一組呼叫reduce階段進行資料壓縮,reduce也是進行手動干預的,我們編碼進行資料計算,計算同key的個數,統計完後就可以輸出一個檔案出來了,這整個過程資料的傳輸都是放在context這個上下文中。下面是借鑑網上的一張圖,HDFS與MapReduce之間的關係協助大概就是這麼個意思。
以上純屬個人的一點淺薄認識,如有不對的地方望指正。