Hadoop學習筆記-MapReduce工作原理
本文從一個初學者的角度出發,用通俗易懂的語言介紹Hadoop中MapReduce的工作原理。在介紹MapReduce工作原理前,本文先介紹HDFS的工作原理及架構,再介紹MapReduce的工作原理以及Shuffle的過程。
HDFS
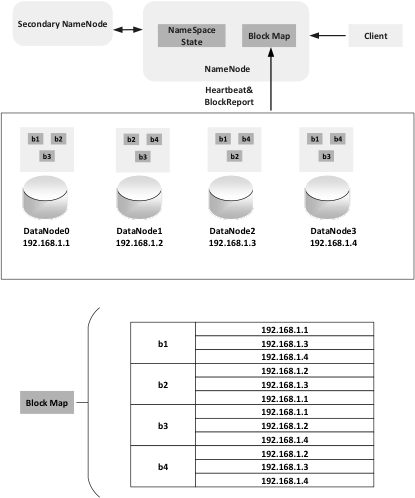
HDFS是Hadoop的分散式檔案系統,HDFS中的檔案會預設儲存3份,儲存在不同的機器上,提供容錯機制,副本丟失或者宕機的自動恢復。HDFS的架構如下圖所示,總體上採用Master/Slave的架構。整個HDFS架構由Client、NameNode、Secondary NameNode和DataNode構成,NameNode負責儲存整個叢集的元資料資訊,Client可以根據元資料資訊找到對應的檔案。DataNode負責資料的實際儲存,當一個檔案上傳到HDFS的時候,DataNode會按照Block為基本單位分佈在各個DataNode中,而且為了保護資料的一致性和容錯性,一般一份資料會在不同的DataNode上預設儲存三份。如下架構圖所示,當Client端上傳了一個檔案,這個檔案被分成了4個block存在4個不同的DataNode裡頭,每個block會預設的儲存三份,分別存在不同的DataNode裡。而NameNode中的Block Map則維護著每個block和DataNode的配置關係,這樣,整個檔案在DataNode中的儲存結構就在NameNode中記錄下來。SecondaryNameNode不是NameNode的熱備份,主要是為了承擔一部分NameNode中比較消耗記憶體的工作而設定。
MapReduce
MapReduce的工作過程分成兩個階段,map階段和reduce階段。每個階段都有鍵值對作為輸入輸出,map函式和reduce函式的具體實現由程式設計師完成。MapReduce的框架和HDFS分散式檔案系統是執行在一組相同的節點上,也就是說計算節點和儲存節點通常在一起,這種配置就允許框架在那些已經存好資料的節點上高效的排程任務,所以一般情況下,map執行的節點通常與其所要處理的那個block資料的儲存節點是同一個。MapReduce的框架也是採用Master/Slave的方式組織,如下圖所示,也是由四部分組成,分別為Client、JobTracker、TaskTracker以及Task。JobTracker主要負責資源監控和作業排程。JobTracker監控TaskTracker是否存活,任務執行的狀態以及資源的使用情況,並且把得到的資訊交給TaskSceduler。TaskSceduler根據每個TaskTracker的情況給分配響應的任務,在Hadoop系統中,TaskSceduler是一個可插拔的模組,Hadoop的使用者可以根據自己的需求定製TaskSceduler,實現自己的目標。
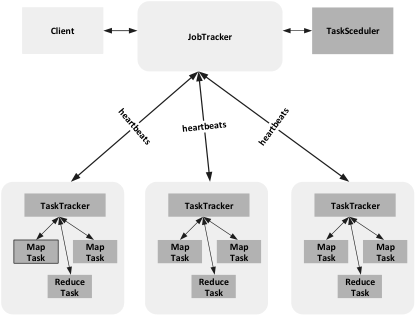
TaskTracker會週期性的通過heartbeats向JobTracker傳送資源的使用情況,任務的執行狀況等資訊,同時會接收JobTracker的指令,TaskTracker把自己可支配的資源分成若干個Slot,Task只有拿到一個Slot資源才能執行任務。
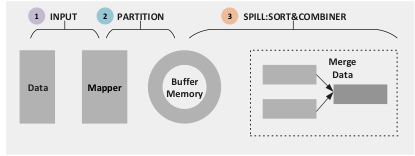
Task任務分成Map Task和Reduce Task兩種任務,都是由TaskTracker進行排程的。Map 任務的資料來源於HDFS,而資料在HDFS中的儲存方式是block,而在Map 任務中,處理的資料單元是Split,一般情況下,Split是一個邏輯概念,包括資料的起始位置,資料長度等資訊,Split和block資料的對應關係可以由使用者定義,Split的多少決定了Map Task的多少,一個Split只由一個Map Task進行處理。Map Task先把需要處理的Split轉化成key/value對,然後呼叫使用者自定義的map()函式,生成map的臨時結果,分成partition存在本地磁碟中,Reduce Task會對每個partition的資料進行Reduce操作,Reduce的輸出結果會輸出到HDFS上。
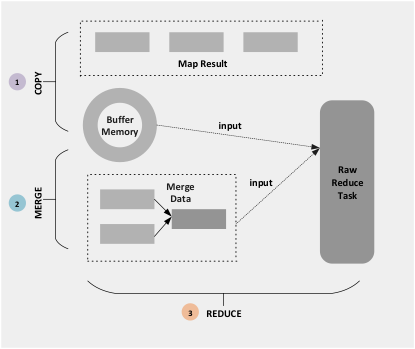
MapReduce的技術核心在於Shuffle,Shuffle這個過程存在的最基本的目的在於減少在跨節點拉取資料的過程中的頻寬開銷以及IO的損耗,因為Map Task最終處理的結果會產生很多中間的臨時檔案,而且Map Task和Reduce Task很有可能不在同一個節點上執行,很多情況下Reduce Task執行的時候需要跨節點的拉取資料,所以必須使拉取的資料量儘量小,以免整個叢集的資源大量消耗在IO中。Shuffle的過程橫跨Map Task和Reduce Task。Shuffle在Map端的過程如下圖所示。Map Task讀取Split的資料之後,經過使用者的Map()函式之後輸出的是一個一個的鍵值對,假設這個MapReduce任務中有8個MapTask,3個Reduce Task,Map Task的輸出最終由哪個Reduce來處理,可以通過Partition來實現。在MapReduce預設的實現中,Partition只是對Key進行雜湊操作然後取模,預設取模的方式是為了平衡每個Reduce之間的任務量,如果使用者對Partition有特殊的需求,也可以定製並設定到Job上。Partition的輸出結果會被寫入臨時記憶體緩衝區,記憶體緩衝區的大小是有限制的,一般情況下預設為100MB,在達到緩衝區的臨界值的情況下,需要將緩衝區的資料寫入磁碟,才能再重新啟用這個緩衝區。從記憶體往磁碟寫資料的過程稱為Spill(溢寫)。在溢寫操作啟動後,需要溢寫的這部分記憶體被鎖定,被鎖定的記憶體資料將會被記錄到磁碟中去,而溢寫的過程不會影響Map()的輸出結果往緩衝區輸入。在溢寫操作過程中,資料寫入磁碟前,會對資料進行一個二次快速排序,首先是對資料所屬的Partition排序,然後對每個Partition中再按照Key排序。Sort的輸出包括一個索引檔案和資料檔案。如果使用者定義了Combiner,則會對Sort後的資料進行一個簡單的Reduce,使得Map端得到的資料更加緊湊。每當記憶體資料達到Spill的臨界值的時候,都會進行Spill操作,從而會產生多個Spill檔案,在Map任務完成之前,所有的Spill檔案都會被歸併排序為一個索引檔案和資料檔案。
當Spill歸併完畢之後,Map端刪除所有的臨時檔案並且告知TaskTracker其Map任務已經完成,Reduce端可以開展工作,工作流程如下圖所示。Reduce端一開始的主要工作是把Map端的輸出結果拷貝,同樣,Map端的輸出結果通常會先輸出到緩衝區中,如果緩衝區不足,會溢寫到磁碟中,溢寫到磁碟過程中,merge的操作一直在進行,如果Map端的輸出結果計較小,沒有填滿緩衝區,這資料會直接從緩衝區直接進入Reduce操作,Reduce操作完成後,輸出結果會直接放到HDFS上。