
【機器學習】異常點檢測_sklearn
注意Novelty和Outlier的區別
novelty detection:
The training data is not polluted by outliers, and we are interested in detecting anomalies in new observations.
outlier detection:
The training data contains outliers, and we need to fit the central mode of the training data, ignoring the deviant observations.
即Novelty Detection要求所有訓練資料都是正常的,不包含異常點,模型用於探測新加入的點是否異常;OneClassSVM屬於此類
而Outlier Detection允許訓練資料中有異常點,模型會盡可能適應訓練資料而忽視異常點;EllipticEnvelope、IsolationForest、LocalOutlierFactor屬於此類
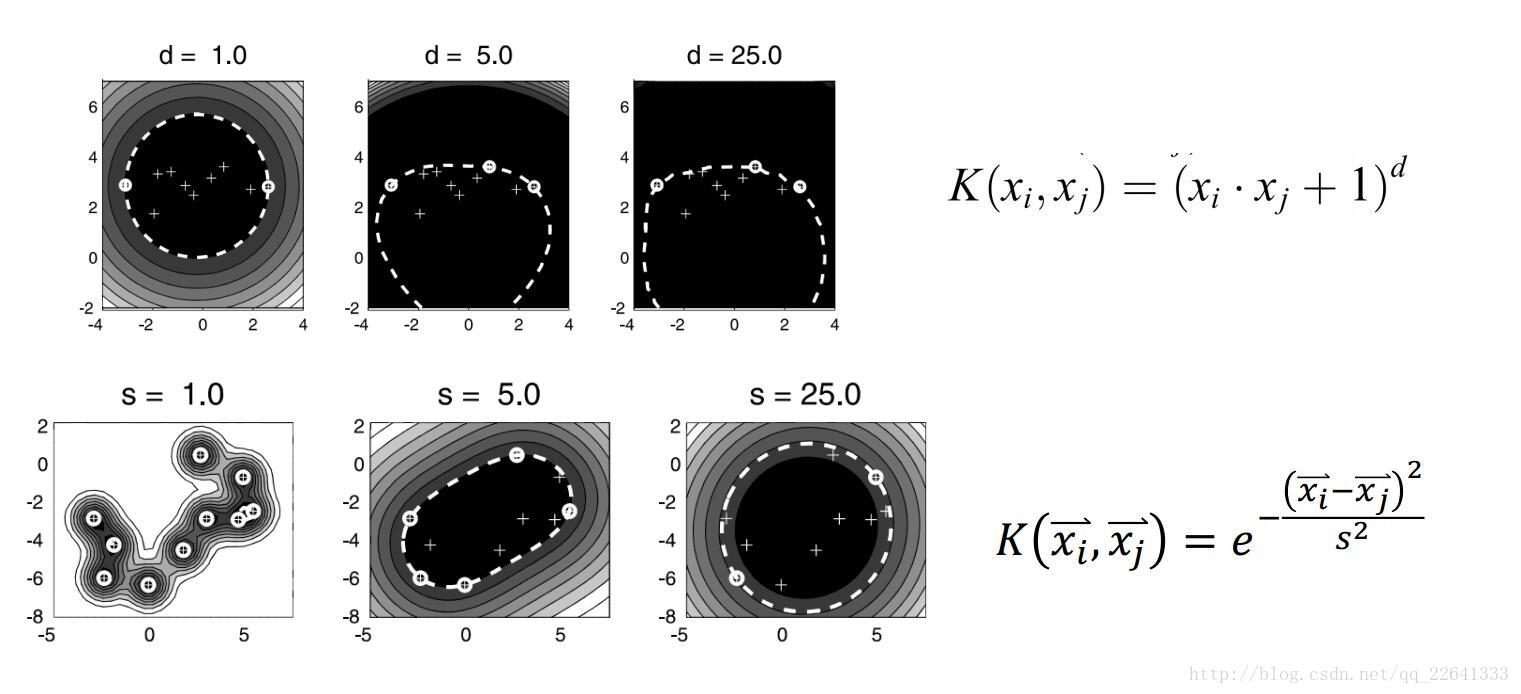
OneClassSVM
一分類SVM,等同於SVDD,sklearn中為svm.OneClassSVM,參考
class sklearn.svm.OneClassSVM(kernel=’rbf’, degree=3, gamma 基本思想:確定一個超球體,使得球儘可能小,而又包含了儘可能多的點,球內視為正,球外視為異常。則目標函式
通過C來調節球的大小和誤分類點的懲罰程度,當點再球內或邊界上則,邊界上的稱為支援向量SV,外部為BSV
對應的可以將原始資料對映到高維空間,然後在高維空間中找到這個超球體,再映射回低維度

EllipticEnvelope
魯棒協方差估計,沒太看懂,以後再補吧。大概就是畫個把目標資料包進去的超橢球,其中橢球形狀考慮協方差、馬氏距離什麼的。。。
class sklearn.covariance.EllipticEnvelope(store_precision=True, assume_centered=False, support_fraction=None, contamination=0.1, random_state=None)
-
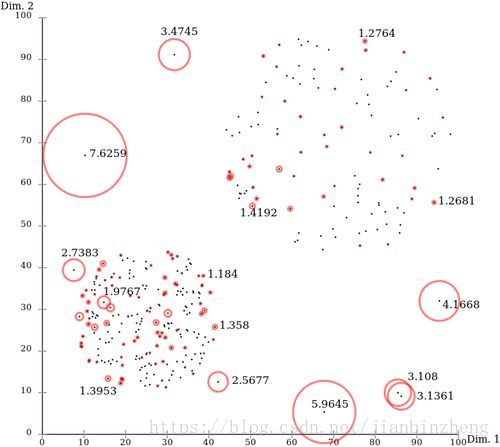
Isolation Forest
孤立森林。N棵二叉樹,每棵樹選取部分/全部資料,每次隨機選取一個特徵,隨機選取一個切點(max和min之間),直到每個/相同點分配到葉子,得到每個點的路徑距離d(跟到葉子結點),N棵樹的d的均值即為點的距離。d越小,越異常(離得遠,易被分出來);d越大,越正常。
class sklearn.ensemble.IsolationForest(n_estimators=100, max_samples=’auto’, contamination=0.1, max_features=1.0, bootstrap=False, n_jobs=1, random_state=None, verbose=0)
-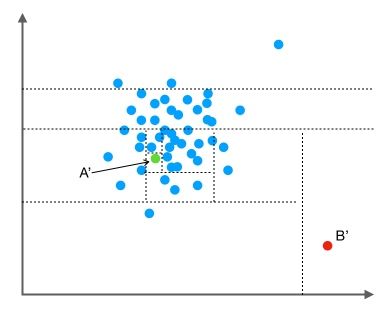

Local Outlier Factor
基於密度的演算法。LOF為1,則點p的區域性密度與鄰居類似;若LOF<1,則其在相對密集的區域;若LOF>>1,則p與其他點比較疏遠(鄰居密度大,而自己密度小)
K鄰近距離(K-distance):對點p最近的幾個點中,第k近的點到p的距離
可達距離(reachability distance):p與o的可達距離reach-dist(p,o)為資料點o的K-鄰近距離和p-o距離的較大值
區域性可達密度(local reachability density):點p與K個鄰近點的平均可達距離的倒數
區域性異常因子(local outlier factor):如果一個數據點跟其他點比較疏遠的話,那麼顯然它的區域性可達密度就小,這是絕對區域性密度。LOF演算法用相對區域性密度(區域性異常因子),為點p的鄰居的平均區域性可達密度跟資料點p的區域性可達密度的比值。
class sklearn.neighbors.LocalOutlierFactor(n_neighbors=20, algorithm=’auto’, leaf_size=30, metric=’minkowski’, p=2, metric_params=None, contamination=0.1, n_jobs=1)
-
上面幾種方法的對比
- 對於聚合比較好的資料集,OneClassSVM不太適用

- 對於雙峰的資料集,EllipticEnvelope不太適用,其他三個都可以,其中OneClassSVM易過擬合

- 對於強烈非高斯分佈的,EllipticEnvelope非常不使用,其他三個可以

其他的一些異常檢測方法
- 基於正態分佈的一元離群點檢測方法,68.3%、95.4%、99.7%
- 馬氏距離
- 四分位分割
- DBSCAN
- PCA