
效能測試如何定位瓶頸
伺服器效能監控:
Nmon介紹
Nmon 工具是 IBM 提供的免費的在AIX與各種Linux作業系統上廣泛使用的監控與分析工具。該工具可將伺服器的系統資源耗用情況收集起來並輸出一個特定的檔案,並可利用
excel 分析工具nmonanalyser進行資料的統計分析。並且,nmon執行不會佔用過多的系統資源,通常情況下CPU利用率不會超過2%。針對不同的操作 系統版本,nmon有相應版本的程式。
Nmon安裝及使用
上傳nmon_linux_14i.tar.gz到/usr/local/src資料夾下。
執行以下操作:
以上Nmon配置成功後,Nmon工具使用比較簡單,在nmon 目錄下或者其他任意目錄,輸入nmon
[[email protected] nmon]#nmon

出現此畫面,說明已安裝成功。
輸入c可顯示CPU的資訊,“m”對應記憶體、“n”對應網路,“d”可以檢視磁碟資訊;“t”可以檢視系統的程序資訊;“

資料採集
以上實現的是對伺服器的實時監控,在實際的效能測試中我們需要把一段時間之內的資料記錄下來,可以使用如下命令
nmon analyser工具應用
1) 下載後開啟nmon analyser v33g.xls。下載檔案見附件
2) 調整excel巨集的安全級別,調整為最低或者如下操作

3) 然後點選Analyser nmon data 按鈕,選擇下載下來的.csv檔案,然後就會轉化成.excel檔案,生成圖形化的檔案,例如:

基於命令列的效能監控工具
1. dstat - 多型別資源統計工具
該命令整合了vmstat,iostat和ifstat三種命令。同時增加了新的特性和功能可以讓你能及時看到各種的資源使用情況,從而能夠使你對比和整合不同的資源使用情況。通過不同顏色和區塊佈局的介面幫助你能夠更加清晰容易的獲取資訊。它也支援將資訊資料匯出到cvs格式檔案中,從而用其他應用程式開啟,或者匯入到資料庫中。你可以用該命令來監控cpu,記憶體和網路狀態隨著時間的變化。

5. sar - 效能監控和瓶頸檢查
sar 命令可以將作業系統上所選的累積活動計數器內容資訊輸出到標準輸出上。其基於計數值和時間間隔引數的審計系統,會按照指定的時間間隔輸出指定次數的監控資訊。如果時間間隔引數為設定為0,那麼sar命令將會顯示系統從開機到當時時刻的平均統計資訊。有用的命令如下:
# sar -u 2 3 # sar -u -f /var/log/sa/sa05 # sar -P ALL 1 1 # sar -r 1 3 # sar -W 1 3
6. Saidar - 簡單的統計監控工具
Saidar是一個簡單且輕量的系統資訊監控工具。雖然它無法提供大多效能報表,但是它能夠通過一個簡單明瞭的方式顯示最有用的系統執行狀況資料。你可以很容易地看到執行時間、平均負載、CPU、記憶體、程序、磁碟和網路介面統計資訊。
Usage: saidar [-d delay] [-c] [-v] [-h] -d 設定更新時間(秒) -c 彩色顯示 -v 顯示版本號 -h 顯示本幫助

8. Sysdig - 系統程序的高階檢視
Sysdig是一個能夠讓系統管理員和開發人員以前所未有方式洞察其系統行為的監控工具。其開發團隊希望改善系統級的監控方式,通過提供關於儲存,程序,網路和記憶體子系統的統一有序以及粒度可見的方式來進行錯誤排查,並可以建立系統活動記錄檔案以便你可以在任何時間輕鬆分析。
簡單例子:
# sysdig proc.name=vim # sysdig -p"%proc.name %fd.name" "evt.type=accept and proc.name!=httpd" # sysdig evt.type=chdir and user.name=root # sysdig -l # sysdig -L # sysdig -c topprocs_net # sysdig -c fdcount_by fd.sport "evt.type=accept" # sysdig -p"%proc.name %fd.name" "evt.type=accept and proc.name!=httpd" # sysdig -c topprocs_file # sysdig -c fdcount_by proc.name "fd.type=file" # sysdig -p "%12user.name %6proc.pid %12proc.name %3fd.num %fd.typechar %fd.name" evt.type=open # sysdig -c topprocs_cpu # sysdig -c topprocs_cpu evt.cpu=0 # sysdig -p"%evt.arg.path" "evt.type=chdir and user.name=root" # sysdig evt.type=open and fd.name contains /etc

9. netstat - 顯示開放的埠和連線
它是Linux管理員使用來顯示各種網路資訊的工具,如檢視什麼埠開放和什麼網路連線已經建立以及何種程序執行在該連線之上。同時它也顯示了不同程式間開啟的Unix套接字的資訊。作為大多數Linux發行版本的一部分,netstat的許多命令在netstat和它的不同輸出中有詳細的描述。最為常用的如下:
$ netstat | head -20 $ netstat -r $ netstat -rC $ netstat -i $ netstat -ie $ netstat -s $ netstat -g $ netstat -tapn
10. tcpdump - 洞察網路封包
tcpdump可以用來檢視網路連線的封包內容。它顯示了傳輸過程中封包內容的各種資訊。為了使得輸出資訊更為有用,它允許使用者通過不同的過濾器獲取自己想要的資訊。可以參照的例子如下:
# tcpdump -i eth0 not port 22 # tcpdump -c 10 -i eth0 # tcpdump -ni eth0 -c 10 not port 22 # tcpdump -w aloft.cap -s 0 # tcpdump -r aloft.cap # tcpdump -i eth0 dst port 80
11. vmstat - 虛擬記憶體統計資訊
vmstat是虛擬記憶體(virtual memory statistics)的縮寫,作為一個記憶體監控工具,它收集和顯示關於記憶體,程序,終端和分頁和I/O阻塞的概括資訊。作為一個開源程式,它可以在大部分Linux發行版本中找到,包括Solaris和FreeBSD。它用來診斷大部分的記憶體效能問題和其他相關問題。

12. free - 記憶體統計資訊
free是另一個能夠在終端中顯示記憶體和交換空間使用的命令列工具。由於它的簡易,它經常用於快速檢視記憶體使用或者是應用於不同的指令碼和應用程式中。在這裡你可以看到這個小程式的許多應用。幾乎所有的系統管理員日常都會用這個工具。:-)

13. Htop - 更加友好的top
Htop基本上是一個top改善版本,它能夠以更加多彩的方式顯示更多的統計資訊,同時允許你採用不同的方式進行排序,它提供了一個使用者友好的介面。

15. lsof - 列表顯示開啟的檔案
lsof命令,意為“list open files”, 用於在許多類Unix系統中顯示所有開啟的檔案及開啟它們的程序。在大部分Linux發行版和其他類Linux作業系統中系統管理員用它來檢查不同的程序打開了哪些檔案。
# lsof +p process_id # lsof | less # lsof –u username # lsof /etc/passwd # lsof –i TCP:ftp # lsof –i TCP:80
你可以找到 更多例子 在lsof 文章
16. iftop - 類似top的了網路連線工具
iftop是另一個基於網路資訊的類似top的程式。它能夠顯示當前時刻按照頻寬使用量或者上傳或者下載量排序的網路連線狀況。它同時提供了下載檔案的預估完成時間。

17. iperf - 網路效能工具
iperf是一個網路測試工具,能夠建立TCP和UDP資料連線並在網路上測量它們的傳輸效能。它支援調節關於時間,協議和緩衝等不同的引數。對於每一個測試,它會報告頻寬,丟包和其他的一些引數。

如果你想用使用這個工具,可以參考這篇文章: 如何安裝和使用iperf
18. Smem - 高階記憶體報表工具
Smem是最先進的Linux命令列工具之一,它提供關於系統中已經使用的和共享的實際記憶體大小,試圖提供一個更為可靠的當前記憶體使用資料。
$ smem -m $ smem -m -p | grep firefox $ smem -u -p $ smem -w -p
圖形化或基於Web的效能工具
19. Icinga - Nagios的社群分支版本
Icinga是一個開源免費的網路監控程式,作為Nagios的分支,它繼承了前者現有的大部分功能,同時基於這些功能又增加了社群使用者要求已久的功能和補丁。

20. Nagios - 最為流行的監控工具
作為在Linux上使用最為廣泛和最為流行的監控方案,它有一個守護程式用來收集不同程序和遠端主機的資訊,這些收集到的資訊都通過功能強大的web介面進行呈現。

你可以在文章“如何安裝nagios”裡面找到更多的資訊
21. Linux process explorer - Linux下的procexp
Linux process explorer是一個Linux下的圖形化程序瀏覽工具。它能夠顯示不同的程序資訊,如程序數,TCP/IP連線和每一個程序的效能指標。作為Windows下procexp在Linux的替代品,是由Sysinternals開發的,其目標是比top和ps提供更好使用者體驗。

22. Collectl - 效能監控工具
你可以既可以通過互動的方式使用這個效能監控工具,也可以用它把報表寫到磁碟上,並通過web伺服器來訪問。它以一種易讀易管理的格式,顯示了CPU,磁碟,記憶體,網路,網路檔案系統,程序,slabs等統計資訊。

23. MRTG - 經典網路流量監控圖形工具
這是一個採用rrdtool的生成圖形的流量監控工具。作為最早的提供圖形化介面的流量監控工具,它被廣泛應用在類Unix的作業系統中。檢視我們關於如何使用MRTG的文章獲取更多關於安裝和配置的資訊。

24. Monit - 簡單易用的監控工具
Monit是一個用來監控程序,系統載入,檔案系統和目錄檔案等的開源的Linux工具。你能夠讓它自動化維護和修復,也能夠在執行錯誤的情景下執行特定動作或者發郵件報告提醒系統管理員。如果你想要用這個工具,你可以檢視如何使用Monit的文章。

25. Munin - 為伺服器提供監控和提醒服務
作為一個網路資源監控工具,Munin能夠幫助分析資源趨勢和檢視薄弱環節以及導致產生效能問題的原因。開發此軟體的團隊希望它能夠易用和使用者體驗友好。該軟體是用Perl開發的,並採用rrdtool來繪製圖形,使用了web介面進行呈現。開發人員推廣此應用時聲稱當前已有500多個監控外掛可以“即插即用*”。
效能測試這種測試方式在發生過程中,其中一個過渡性的工作,就是對執行過程中的問題,進行定位,對功能的定位,對負載的定位,最重要的,當然就是問題中說的“瓶頸”,接觸效能測試不深,更非專家,自己的理解,瓶頸產生在以下幾方面:
1、網路瓶頸,如頻寬,流量等形成的網路環境
2、應用服務瓶頸,如中介軟體的基本配置,CACHE等
3、系統瓶頸,這個比較常用:應用伺服器,資料庫伺服器以及客戶機的CPU,記憶體,硬碟等配置
4、資料庫瓶頸,以ORACLE為例,SYS中預設的一些引數設定
5、應用程式本身瓶頸,這個是測試過程中最需要去關注的,需要測試人員和開發人員配合執行,然後定位
逐步細化分析,先可以監控一些常見衡量CPU,記憶體,磁碟的效能指標,進行綜合分析,然後根據所測系統具體情況,進行初步問題定位,然後確定更詳細的監控指標來分析。
懷疑記憶體不足時:
方法1:
【監控指標】:Memory Available MBytes ,Memory的Pages/sec, page read/sec, Page Faults/sec
【參考值】:
如果 Page Reads/Sec 比率持續保持為 5,表示可能記憶體不足。
Page/sec 推薦00-20(如果伺服器沒有足夠的記憶體處理其工作負荷,此數值將一直很高。如果大於80,表示有問題)。
方法2:根據Physical Disk 值分析效能瓶頸
【監控指標】:Memory Available MBytes ,Pages read/sec,%Disk Time 和 Avg.Disk Queue Length
【參考值】:%Disk Time建議閾值90%
當記憶體不足時,有點程序會轉移到硬碟上去執行,造成效能急劇下降,而且一個缺少記憶體的系統常常表現出很高的CPU利用率,因為它需要不斷的掃描記憶體,將記憶體中的頁面移到硬碟上。
懷疑記憶體洩漏時
【監控指標】:Memory Available MBytes ,Process\Private Bytes和Process\Working Set,PhysicalDisk/%Disk Time
【說明】:
Windows資源監控中,如果Process\Private Bytes計數器和Process\Working Set計數器的值在長時間內持續升高,同時Memory\Available bytes計數器的值持續降低,則很可能存在記憶體洩漏。記憶體洩漏應該通過一個長時間的,用來研究分析當所有記憶體都耗盡時,應用程式反應情況的測試來檢驗。
CPU分析
【監控指標】:
System %Processor Time CPU,Processor %Processor Time CPU
Processor%user time 和Processor%Privileged Time
system\Processor Queue Length
Context Switches/sec 和%Privileged Time
【參考值】:
System\%Total processor time不持續超過90%,如果伺服器專用於SQL Server,可接受的最大上限是80-85% ,合理使用的範圍在60%至70%。
Processor %Processor Time小於75%
system\Processor Queue Length值,小於CPU數量的總數+1
CPU瓶頸問題
1、System\%Total processor time如果該值持續超過90%,且伴隨處理器阻塞,則說明整個系統面臨著處理器方面的瓶頸.
注:在某些多CPU系統中,該資料雖然本身並不大,但CPU之間的負載狀況極不均衡,此時也應該視作系統產生了處理器方面的瓶頸.
2、排除記憶體因素,如果Processor %Processor Time計數器的值比較大,而同時網絡卡和硬碟的值比較低,那麼可以確定CPU 瓶頸。(記憶體不足時,有點程序會轉移到硬碟上去執行,造成效能急劇下降,而且一個缺少記憶體的系統常常表現出很高的CPU利用率,因為它需要不斷的掃描記憶體,將記憶體中的頁面移到硬碟上。)
造成高CPU使用率的原因:
頻繁執行程式,複雜運算操作,消耗CPU嚴重
資料庫查詢語句複雜,大量的 where 子句,order by, group by 排序等,CPU容易出現瓶頸
記憶體不足,IO磁碟問題使得CPU的開銷增加
磁碟I/O分析
【監控指標】:PhysicalDisk/%Disk time,PhysicalDisk/%Idle Time,Physical Disk\ Avg.Disk Queue Length, Disk sec/Transfer
【參考值】:%Disk Time建議閾值90%
Windows資源監控中,如果% Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec頁面讀取操作速率很低,則可能存在磁碟瓶徑。
Processor%Privileged Time該引數值一直很高,且如果在 Physical Disk 計數器中,只有%Disk time 比較大,其他值都比較適中,硬碟可能會是瓶頸。若幾個值都比較大, 那麼硬碟不是瓶頸。若數值持續超過80%,則可能是記憶體洩露。如果 Physical Disk 計數器的值很高時該計數器的值(Processor%Privileged Time)也一直很高, 則考慮使用速度更快或效率更高的磁碟子系統。
Disk sec/Transfer 一般來說,該數值小於15ms為最好,介於15-30ms之間為良好,30-60ms之間為可以接受,超過60ms則需要考慮更換硬碟或是硬碟的RAID方式了.
---------------------------------------------
Average Transaciton Response Time(事務平均響應時間)隨著測試時間的變化,系統處理事務的速度開始逐漸變慢,這說明應用系統隨著投產時間的變化,整體效能將會有下降的趨勢
Transactions per Second(每秒通過事務數/TPS)當壓力加大時,點選率/TPS曲線如果變化緩慢或者有平坦的趨勢,很有可能是伺服器開始出現瓶頸
Hits per Second(每秒點選次數)通過對檢視“每秒點選次數”,可以判斷系統是否穩定。系統點選率下降通常表明伺服器的響應速度在變慢,需進一步分析,發現系統瓶頸所在。
Throughput(吞吐率)可以依據伺服器的吞吐量來評估虛擬使用者產生的負載量,以及看出伺服器在流量方面的處理能力以及是否存在瓶頸。
Connections(連線數)當連線數到達穩定狀態而事務響應時間迅速增大時,新增連線可以使效能得到極大提高(事務響應時間將降低)
Time to First Buffer Breakdown(Over Time)(第一次緩衝時間細分(隨時間變化))可以使用該圖確定場景或會話步驟執行期間伺服器或網路出現問題的時間。
碰到過的效能問題:
1. 在高併發的情況下,產生的處理失敗(比如:資料庫連線池過低,伺服器連線數超過上限,資料庫鎖控制考慮不足等)
2. 記憶體洩露(比如:在長時間執行下,記憶體沒有正常釋放,發生宕機等)
3. CPU使用偏離(比如:高併發導致CPU使用率過高)
4. 日誌列印過多,伺服器無硬碟空間
如何定位這些效能問題:
1. 檢視系統日誌,日誌是定位問題的不二法寶,如果日誌記錄的全面,很容易通過日誌發現問題。
比如,系統宕機時,系統日誌列印了某方法執行時丟擲out of memory的錯誤,我們就可以順藤摸瓜,很快定位到導致記憶體溢位的問題在哪裡。
2. 利用效能監控工具,比如:JAVA開發B/S結構的專案,可以通過JDK自帶的Jconsole,或者JProfiler,來監控伺服器效能,Jconsole可以遠端監控伺服器的CPU,記憶體,執行緒等狀態,並繪製變化曲線圖。
利用Spotlight可以監控資料庫使用情況。
我們需要關注的效能點有:CPU負載,記憶體使用率,網路I/O等
3. 工具和日誌只是手段,除此之外,還需要設計合理的效能測試場景
具體場景有:效能測試,負載測試,壓力測試,穩定性測試,浪湧測試等
好的測試場景,能更加快速的發現瓶頸,定位瓶頸
4. 瞭解系統引數配置,可以進行後期的效能調優
最後要說的是:做效能測試的時候,我們一定要確保瓶頸不要發生在我們自己的測試指令碼和測試工具上。
效能問題伺服器、主機、應用、程式碼、資料庫、網路等各種影響,所以要定位問題是不容易的。最好是使用監測的工具,從IT環境的整體佈局來考慮,定位到效能的瓶頸。zabbix、newrelix,國內的監控寶都可以考慮。
<img src="https://pic4.zhimg.com/cbb4e690554d971cad94287bc6f6fde7_b.png" data-rawwidth="812" data-rawheight="419" class="origin_image zh-lightbox-thumb" width="812" data-original="https://pic4.zhimg.com/cbb4e690554d971cad94287bc6f6fde7_r.png">當然,如果知道一些資料標準的話,對定位效能瓶頸是非常有幫助的。還是可以從第三方的工具中獲得一些標準。比如這個: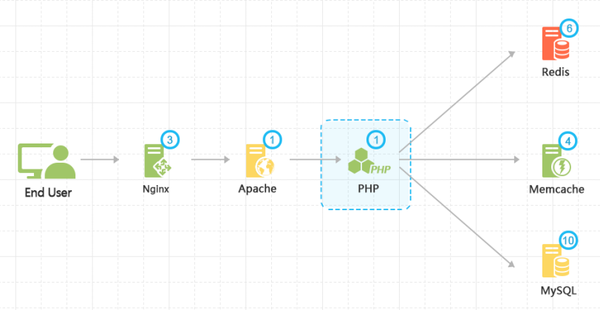 當然,如果知道一些資料標準的話,對定位效能瓶頸是非常有幫助的。還是可以從第三方的工具中獲得一些標準。比如這個:
當然,如果知道一些資料標準的話,對定位效能瓶頸是非常有幫助的。還是可以從第三方的工具中獲得一些標準。比如這個:

這張表是我從監控寶抄下來的有關響應時間的閾值。從一定程度上可以反應使用者的容忍程度,若測試是發現響應時間超出了這個範圍,就是你的瓶頸了,改做相應的改善。