
Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization(二)
接著上篇Asm2Vec神經網路模型流程繼續,接下來探討具體過程和細節。
一.為彙編函式建模
二.訓練,評估
先來看第一部分為彙編函式建模,這個過程是將儲存庫中的每一個彙編函式建模為多個序列。由於控制流圖的原始線性佈局覆蓋了一些無效的執行路徑,不能直接使用它作為訓練序列。相反,可以將控制流程圖建模為邊緣覆蓋序列和隨機遊動,除此之外,還要考慮函式內聯等編譯器優化。
1.1選擇性被擴張. 函式內聯這種技術,用被呼叫函式的主體替換呼叫指令。擴充套件了原來的彙編函式,並通過刪除呼叫開銷提高了其效能。它顯著地修改了控制流圖,是彙編克隆搜尋[12][13]的一個主要挑戰。本文采用讓函式呼叫指令有選擇地被呼叫函式的主體展開,BinGo[12]內聯所有標準庫呼叫,以確保語義正確。本文不用內聯任何庫呼叫,因為庫呼叫tokens之間的詞彙語義已經被模型很好地捕獲了(之前提到過的這些訓練彙編程式碼不包含任何庫內聯呼叫,直接用普通的彙編程式碼訓練Asm2Vec模型,得到三類tokens(運算元,操作,庫函式呼叫)每一個token的200維數值向量)。對於遞迴呼叫的處理,採用被呼叫函式的入度和出度比作為解耦指標,決定被呼叫函式是否展開。
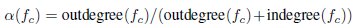
設定閾值為0.01,呼叫別人為出度,被別人呼叫為入度。如果發現被呼叫函式比呼叫函式具有相當的長度,展開後類似於被呼叫函式。因此,新增一個額外的度量來過濾掉冗長的呼叫:

如果被呼叫函式長度佔呼叫函式長度的比小於0.6,或者呼叫函式小於10行指令,則內聯被呼叫函式。
1.2邊緣覆蓋. 為了生成一個彙編函式的多個序列,從已經內聯擴張的控制流程圖中隨機取樣所有的邊,直到原始圖中的所有邊都被覆蓋。對於每條取樣邊,將它們的彙編程式碼串聯起來,形成一個新的序列。這樣,可以確保控制流程圖被完全覆蓋。及時控制流程圖中的基本快被分割或者合併,模型也可以產生類似的序列。
1.3隨機路線. CACompare[13]使用隨機輸入序列來分析彙編函式的I/O行為,隨機輸入模擬有效執行流上的隨機路線。受此方法的啟發,本文通過在已經擴充套件的CFG上用填充多個隨機路線的方式針對一個彙編函式進行擴充套件彙編序列。Dominator是一個在控制流分析和編譯器優化中廣泛使用的蓋簾。如果一個基本必須通過另一個基本塊才能到達另一個基本塊,那麼該基本塊就占主導地位。多個隨機遊走將使覆蓋主導其他塊的基本塊(主導塊)的概率更高。這些主導塊可以指示迴圈機構,也可以覆蓋重要分支條件。使用隨機路線可以被認為是一種自然方法來優化處理那些主導塊。
第二部分主要是訓練的過程,評估的流程,以及實驗所用的相關配置。
訓練過程演算法如下:

演算法1針對儲存庫中的每一個函式,通過邊取樣和隨機路線的方式生成了序列。對於每個序列,它遍歷每個指令並應用Asm2Vec更新向量(第10行到第19行)。如演算法1,訓練過程不需要等效彙編函式之間的ground-truth對映。

對於給定一個查詢ft,用一個向量表示它,初始化為接近0的很小值。然後用神經網路遍歷關於此函式的每一個序列和每一條指令。在每一個預測步驟中,針對token t生成的兩個向量t,和t1(用來做預測的),只傳播錯誤給查詢ft向量,整個訓練結束後,就有了函式ft的向量和屬於儲存庫中函式的向量和所有tokens字典D中由token t生成的兩個向量t, t1組成的向量相同,搜尋匹配的衡量,通過計算向量之間的餘弦相似度。
可擴充套件性對於二進位制克隆搜尋很重要,因為儲存庫中可能有數百萬個程式集函式,在大規模的彙編程式碼上訓練Asm2Vec是可行的。一個類似的文字模型已經被證明可以擴充套件到數十億個文字樣本來訓練[21]。在本文研究中,使用成對相似性來搜尋最近鄰居。在低維固定長度向量之間進行兩兩搜尋是快速的。