
python3(六)監督學習
正文
回到頂部1 監督學習
利用一組帶標籤的資料, 學習從輸入到輸出的對映, 然後將這種對映關係應用到未知資料, 達到分類或者迴歸的目的
(1) 分類: 當輸出是離散的, 學習任務為分類任務
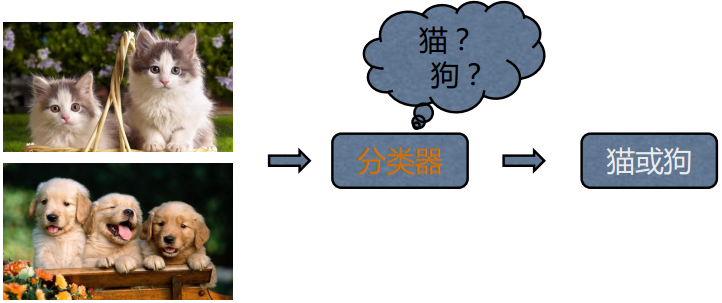
輸入: 一組有標籤的訓練資料(也叫觀察和評估), 標籤表明了這些資料(觀察)的所屬類別, 圖中”貓”和”狗”就是標籤
輸出: 分類模型根據這些訓練資料, 訓練自己的模型引數, 學習出一個適合這組資料的分類器, 當有新資料(非訓練資料)需要進行類別判斷, 就可以將這組資料作為輸入送給學習好的分類器進行判斷(得到標籤)
訓練集: 訓練模型已經標註的資料, 用來建立模型發現規律
測試集: 已標註的資料, 只不過把標註隱藏了, 再送給訓練好的模型, 比對結果與原來的標註, 評判該模型的學習能力
一般來說, 獲得了一組標註好的資料, 70%當做訓練集, 30%當做測試集, 另外還有交叉驗證法, 自助法來評估學習模型
評價標準
1) 準確率
所有預測對的
把正類預測成正類(TP)
把負類預測成負類(TN)
準確率 = (TP+TN)/總數量
2) 精確率
以二分類為例
預測為正的樣本是真的正樣本
把正類預測為正類(TP)
把負類預測為正類(FP)
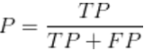
3) 召回率
樣本中的正比例有多少被預測正確
把正類預測成正類(TP)
把正類預測成負類(FN)

sklearn提供的分類函式有:
K近鄰(knn), 樸素貝葉斯(naivebayes), 支援向量機(svm), 決策樹(decision tree), 神經網路模型(Neural networks)
(2) 迴歸: 當輸出是連續的, 學習任務是迴歸任務
通過迴歸, 可以瞭解兩個或多個變數是否相關, 方向及其強度, 可以建立數學模型來觀察特定變數以及預測特定的變數
迴歸可以根據給出的自變數估計因變數的條件期望
sklearn提供的迴歸函式放在了兩個子模組
sklearn.linear_model, 線性函式: 普通線性迴歸函式(LinearRegression), 嶺迴歸(Ridge), Lasso
sklearn.preprocessing, 非線性迴歸: 多項式迴歸(PolynomialFeatures)
迴歸應用
對一些帶有時序資訊的資料進行預測或者趨勢擬合, 在金融以及其他涉及時間序列分析的領域
股票趨勢預測
交通流量預測
回到頂部2 分類
2.1 人體運動資訊評級例項
可穿戴裝置可以獲取人體各項資料, 通過這些資料可以進行分析和建模, 可以對使用者狀況進行判斷
在資料來源中有一個特徵檔案*.feature, 一個標籤檔案*.label
特徵檔案包含41列特徵


溫度: 靜止時人體一般維持在36.5度上下, 當溫度高於37度時, 可能是進行短時間的劇烈運動
一型/二型三軸加速區: 這是兩個型號的加速度感測器, 兩個加速度感測器可以相互印證來保證資料的完整性準確性, 獲得的資料是在x,y,z三個軸上的加速度, 如z軸上加速度劇增, 很有可能就是人體向上跳
陀螺儀: 獲得使用者當前身體的角度, 可以判斷姿態
磁場: 檢測使用者周圍磁場強度和數值大小, 可以幫助我們理解使用者所在的環境, 一般地, 人在一個辦公場所, 使用者座位的周圍的磁場大體上是固定的, 因此當磁場發生改變時, 可以推測使用者的位置和場景發生了變化
標籤檔案對應於特徵檔案的每一行, 總共有25中姿態
2.2 基本分類模型
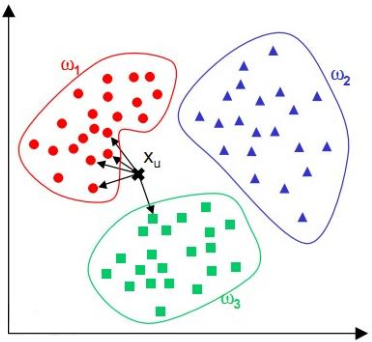
(1) k近鄰分類器(KNN)
原有已經分類好的點, 現加入新的點, 判斷其類別就是檢視所有點與它的距離, 取前K個, 這K個點哪一部分的的點的數量多, 這個新加入的點就屬於哪一部分
建立knn分類器
sklearn.neighbors.KNeighborsClassifier()
n_neighbors: 用於指定分類器中K的大小, 預設為5
weights: 設定K個點對分類結果影響的權重, 預設平均權重uniform, 距離權重(越近權重越高)distance, 或者是自定義計算函式
algorithm: 尋找臨近點的方法, 預設為auto(根據資料自動選擇), ball_tree, kd_tree, brute等
使用kkn

X = [[0],[1],[2],[3]]
y = [0,0,1,1]
from sklearn.neighbors import KNeighborsClassifier
neight = KNeighborsClassifier(n_neighbors=3)
neight.fit(X,y)
Out[5]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=3, p=2,
weights='uniform')
neight.predict([[1.1]])
Out[6]: array([0])
其中X是資料, y是標籤, 使用predict()來預測新的點, 檢查前3個點, 應該是[1],[2],[0]主要是標籤0的資料點, 因此[1.1]被劃分到標籤0中
關於k的選取
較大的k值, 由於鄰域較大, 有可能和他就近的分類點不多, 所以可能結果出錯
較小的k值, 鄰域較小, 有可能鄰居是噪聲點, 導致過擬合
一般來說, 選擇較小的k, 然後使用交叉驗證選取最優的k值
(2) 決策樹
一般是詢問分類點的屬性決定走向的分支, 不斷查詢獲得最終的分類
無房產單身年收入55k的決策效果
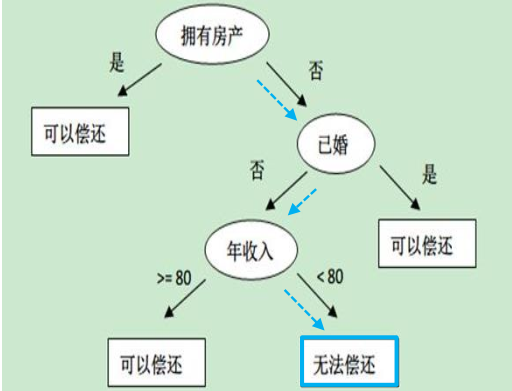
建立決策樹
sklearn.tree.DecisionTree.Classifier()
criterion: 選擇屬性的準則, gini(基尼係數), entropy(資訊增益)
max_features: 從多少個特徵中選擇最優特徵, 預設是所有特徵個數, 還可以是固定數目, 百分比等
決策樹的使用
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
clf = DecisionTreeClassifier()
iris = load_iris()
cross_val_score(clf, iris.data, iris.target, cv=10)
Out[12]:
array([ 1. , 0.93333333, 1. , 0.93333333, 0.93333333,
0.86666667, 0.93333333, 1. , 1. , 1. ])
cross_val_score是一個計算交叉驗證值的函式
iris.data作為資料集, iris.target作為目標結果
cv=10表示使用10折交叉驗證
同樣可以使用 clf.fit(X,y)來生成, clsf.predict(x)進行函式預測
(3) 樸素貝葉斯
樸素貝葉斯是以貝葉斯定理為基礎的多分類的分類器
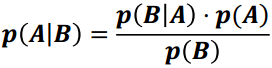
sklearn實現了三個樸素貝葉斯分類器

區別在於假設某一特徵的所有屬於某個類別的觀測值符合特定分佈, 分類問題的特徵包括人的身高, 身高符合高斯分佈, 這類問題適合高斯樸素貝葉斯
建立樸素貝葉斯
sklearn.naive_bayes.GaussianNB()
priors: 給定各個類別的先驗概率, 空(按訓練資料的實際情況進行統計), 給定先驗概率(訓練過程不能更改)
樸素貝葉斯的使用
import numpy as np
X = np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
Y = np.array([1,1,1,2,2,2])
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB(priors=None)
clf.fit(X,Y)
Out[18]: GaussianNB(priors=None)
clf.predict([[-0.8,-1]])
Out[19]: array([1])
樸素貝葉斯是典型的生成學習方法, 由訓練資料學習聯合概率分佈, 並求得後驗概率分佈
樸素貝葉斯一般在小規模資料上的表現很好, 適合進行多分類任務
2.3 運動狀態程式
程式流程:
從特徵檔案和標籤檔案中將所有的資料載入到記憶體中, 並對缺失值進行簡單的資料預處理
建立分類器, 使用訓練集進行訓練
測試集預測, 通過計算模型整體的準確率和召回率, 評估模型
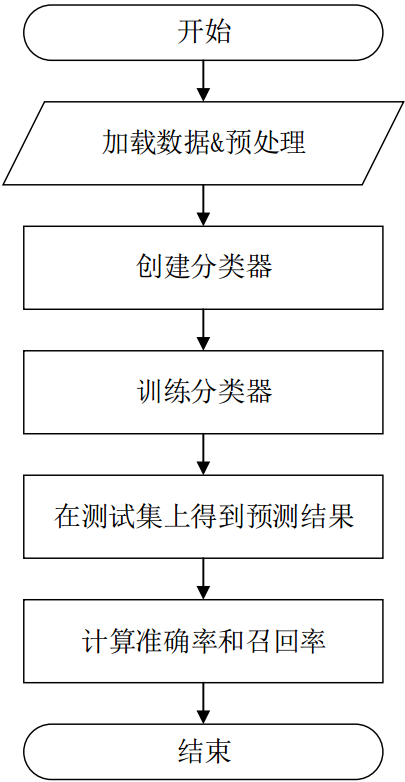
1) 模組的匯入
?| 12345678910 | import pandas as pdimport numpy as np from sklearn.preprocessing import Imputerfrom sklearn.cross_validation import train_test_split from sklearn.metrics import classification_reportfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.naive_bayes import GaussianNB |
匯入numpy庫和pandas庫
從sklearn庫中匯入預處理模組Imputer
匯入自動生成訓練集和測試集的模組train_test_split
匯入預測結果評估模組classification_report
再匯入三個演算法: K近鄰分類器KNeighborsClassifier, 決策樹分類器DecisionTreeClassifier和高斯樸素貝葉斯函式GaussianNB
2) 資料匯入函式
?| 12345678910111213141516 | def load_datasets(feature_paths, label_paths):feature = np.ndarray(shape=(0,41))label = np.ndarray(shape=(0,1))for file in feature_paths:df = pd.read_table(file, delimiter=',', na_values='?', header=None)imp = Imputer(missing_values='NaN', strategy='mean', axis=0)imp.fit(df)df = imp.transform(df)feature = np.concatenate((feature, df))for file in label_paths:df = pd.read_table(file, header=None)label = np.concatenate((label, df))label = np.ravel(label)return feature, label |
編寫資料匯入函式,設定傳入兩個引數,分別是特徵檔案的列表feature_paths和標籤檔案的列表label_paths。
定義feature陣列變數,列數量和特徵維度一致為41;定義空的標籤變數,列數量與標籤維度一致為1。
使用pandas庫的read_table函式讀取一個特徵檔案的內容,其中指定分隔符為逗號、缺失值為問號且檔案不包含表頭行。
使用Imputer函式,通過設定strategy引數為‘ mean’,使用平均值對缺失資料進行補全。 fit()函式用於訓練前處理器,transform()函式用於生成預處理結果。
將預處理後的資料加入feature,依次遍歷完所有特徵檔案
遵循與處理特徵檔案相同的思想,我們首先使用pandas庫的read_table函式讀取一個標籤檔案的內容,其中指定分隔符為逗號且檔案不包含表頭行。
由於標籤檔案沒有缺失值,所以直接將讀取到的新資料加入label集合,依次遍歷完所有標籤檔案,得到標籤集合label。
最後函式將特徵集合feature與標籤集合label返回。
3) 主函式的編寫
?| 123456789101112131415161718192021222324252627282930313233 | if __name__ == '__main__':''' 資料路徑 '''featurePaths = ['A/A.feature','B/B.feature','C/C.feature','D/D.feature','E/E.feature']labelPaths = ['A/A.label','B/B.label','C/C.label','D/D.label','E/E.label']''' 讀入資料 '''x_train,y_train = load_datasets(featurePaths[:4],labelPaths[:4])x_test,y_test = load_datasets(featurePaths[4:],labelPaths[4:])x_train, x_, y_train, y_ = train_test_split(x_train, y_train, test_size = 0.0)print('Start training knn')knn = KNeighborsClassifier().fit(x_train, y_train)print('Training done')answer_knn = knn.predict(x_test)print('Prediction done')print('Start training DT')dt = DecisionTreeClassifier().fit(x_train, y_train)print('Training done')answer_dt = dt.predict(x_test)print('Prediction done')print('Start training Bayes')gnb = GaussianNB().fit(x_train, y_train)print('Training done')answer_gnb = gnb.predict(x_test)print('Prediction done')print('\n\nThe classification report for knn:')print(classification_report(y_test, answer_knn))print('\n\nThe classification report for DT:')print(classification_report(y_test, answer_dt))print('\n\nThe classification report for Bayes:')print(classification_report(y_test, answer_gnb)) |
設定資料路徑feature_paths和label_paths。
使用python的分片方法,將資料路徑中的前4個值作為訓練集,並作為引數傳入load_dataset()函式中,得到訓練集合的特徵x_train,訓練集的標籤y_train。
將最後一個值對應的資料作為測試集,送入load_dataset()函式中,得到測試集合的特徵x_test,測試集的標籤y_test。
使用train_test_split()函式,通過設定測試集比例test_size為0,將資料隨機打亂,便於後續分類器的初始化和訓練。
使用預設引數建立K近鄰分類器,並將訓練集x_train和y_train送入fit()函式進行訓練,訓練後的分類器儲存到變數knn中。
使用測試集x_test,進行分類器預測,得到分類結果answer_knn。
使用預設引數建立決策樹分類器dt,並將訓練集x_train和y_train送入fit()函式進行訓練。訓練後的分類器儲存到變數dt中。
使用測試集x_test,進行分類器預測,得到分類結果answer_dt。
使用預設引數建立貝葉斯分類器,並將訓練集x_train和y_train送入fit()函式進行訓練。訓練後的分類器儲存到變數gnb中。
使用測試集x_test,進行分類器預測,得到分類結果answer_gnb。
使用classification_report函式對分類結果,從精確率precision、召回率recall、 f1值f1-score和支援度support四個維度進行衡量。
分別對三個分類器的分類結果進行輸出
回到頂部3 迴歸
3.1 線性迴歸
線性迴歸(Linear Regression)是利用數理統計中迴歸分析,來確定兩種或兩種以上變數間相互依賴的定量關係的一種統計分析方法。
線性迴歸利用稱為線性迴歸方程的最小平方函式對一個或多個自變數和因變數之間關係進行建模。 這種函式是一個或多個稱為迴歸係數的模型引數的線性組合。只有一個自變數的情況稱為簡單迴歸,大於一個自變數情況的叫做多元迴歸