
python3(五)無監督學習
正文
回到頂部1 關於機器學習
機器學習是實現人工智慧的手段, 其主要研究內容是如何利用資料或經驗進行學習, 改善具體演算法的效能
多領域交叉, 涉及概率論、統計學, 演算法複雜度理論等多門學科
廣泛應用於網路搜尋、垃圾郵件過濾、推薦系統、廣告投放、信用評價、欺詐檢測、股票交易和醫療診斷等應用
機器學習的分類
監督學習 (Supervised Learning)
從給定的資料集中學習出一個函式, 當新的資料到來時, 可以根據這個函式預測結果, 訓練集通常由人工標註
無監督學習 (Unsupervised Learning)
相較於監督學習, 沒有人工標註
強化學習(Reinforcement Learning,增強學習)
通過觀察通過什麼樣的動作獲得最好的回報, 每個動作都會對環境有所影響, 學習物件通過觀察周圍的環境進行判斷
半監督學習(Semi-supervised Learning)
介於監督學習和無監督學習
深度學習 (Deep Learning)
利用深層網路神經模型, 抽象資料表示特徵
在Python中使用Scikit-learn(簡化為sklearn)這一模組來處理機器學習
主要是依賴於numpy, scipy和matplotlib庫
開源可複用
sklearn中機器學習模型十分豐富, 需要根據問題的型別來選擇適當的模型
sklearn常用的函式

關於sklearn庫
sklearn是scikit-learn的簡稱,是一個基於Python的第三方模組。sklearn庫集成了一些常用的機器學習方法,在進行機器學習任務時,並不需要實現演算法,只需要簡單的呼叫sklearn庫中提供的模組就能完成大多數的機器學習任務。
安裝sklearn庫需要安裝numpy, scipy(sklearn的基礎, 集成了多種數學演算法和函式), matplotlib(資料繪圖工具)
注意安裝有順序: numpy -> scipy -> matplotlib -> sklearn
2 sklearn庫中的標準資料集及基本功能
2.1 標準資料集

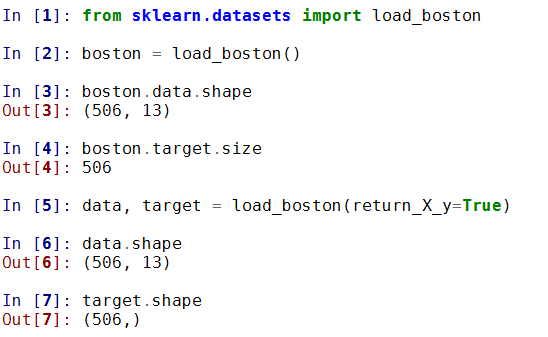
1) 波士頓房價資料集
波士頓房價資料集包含506組資料,每條資料包含房屋以及房屋周圍的詳細資訊。其中包括城鎮犯罪率、一氧化氮濃度、住宅平均房間數、到中心區域的加距離以及自住房平均房價等。因此,波士頓房價資料集能夠應用到迴歸問題上。
載入資料集
sklearn.datasets.load_boston()
其中有引數return_X_y, 設定為True是會返回(data, target)兩個資料, 預設為False, 只返回data(包含了data和target兩個部分的內容)
具體使用
2) 鳶尾花資料集
鳶尾花資料集採集的是鳶尾花的測量資料以及其所屬的類別
測量資料包括: 萼片長度、萼片寬度、花瓣長度、花瓣寬度
類別共分為三類: Iris Setosa,Iris Versicolour,Iris Virginica, 該資料集可用於多分類問題
載入資料集
sklearn.datasets. load_iris()
同樣有引數return_X_y, 使用方法雷同
具體例項

3) 手寫數字資料集
手寫數字資料集包括1797個0-9的手寫數字資料,每個數字由8*8大小的矩陣構成,矩陣中值的範圍是0-16,代表顏色的深度。
載入資料集
sklearn.datasets.load_digits()
return_X_y: 效果依舊, True返回(data, target), 預設False直接返回全部內容
n_class: 設定資料類別, 返回資料的類別比設定類別低的資料樣本, 設定為5就會返回0~4的資料
基本使用

2.2 sklearn庫的基本功能
sklearn庫的共分為6大部分,分別用於完成分類任務、迴歸任務、聚類任務、降維任務、 模型選擇以及資料的預處理
1) 分類任務

2) 迴歸任務

3) 聚類任務

4) 降維任務
3 關於無監督學習
無監督學習的目標
利用無標籤的資料學習資料的分佈或資料與資料之間的關係被稱作無監督學習
有監督學習和無監督學習的最大區別在於資料是否有標籤
無監督學習最常應用的場景是聚類(clustering)和降維(DimensionReduction)
聚類
聚類(clustering),就是根據資料的“相似性”將資料分為多類的過程
評估兩個不同樣本之間的“相似性” ,通常使用的方法就是計算兩個樣本之間的“距離”。使用不同的方法計算樣本間的距離會關係到聚類結果的好壞
1) 歐氏距離
歐氏距離是最常用的一種距離度量方法,源於歐式空間中兩點的距離。
計算公式

直觀表示
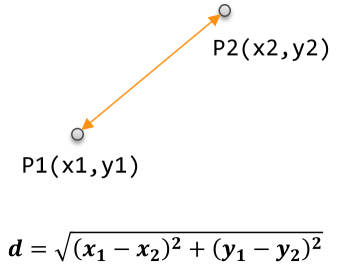
2) 曼哈頓距離
曼哈頓距離也稱作“城市街區距離”,類似於在城市之中駕車行駛,從一個十字路口到另外一個十字樓口的距離(x與y兩個方向的距離之和)
計算公式

直觀表示

3) 馬氏距離
馬氏距離表示資料的協方差距離,是一種尺度無關的度量方式。也就是說馬氏距離會先將樣本點的各個屬性標準化,再計算樣本間的距離。
計算公式, 其中s是協方差矩陣
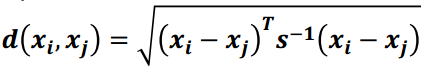
馬氏空間的距離

4) 夾角餘弦
餘弦相似度用向量空間中兩個向量夾角的餘弦值作為衡量兩個樣本差異的大小。餘弦值越接近1,說明兩個向量夾角越接近0度,表明兩個向量越相似
計算公式

二維空間顯示

sklearn提供的常用聚類演算法函式包含在sklearn.cluster這個模組中
以同樣的資料集應用於不同的演算法,可能會得到不同的結果,演算法所耗費的時間也不盡相同,這是由演算法的特性決定的
sklearn.cluster
sklearn.cluster模組提供的各聚類演算法函式可以使用不同的資料形式作為輸入
標準資料輸入格式:[樣本個數,特徵個數]定義的矩陣形式
相似性矩陣輸入格式:即由[樣本數目,樣本數目]定義的矩陣形式,矩陣中的每一個元素為兩個樣本的相似度,如DBSCAN,AffinityPropagation(近鄰傳播演算法)接受這種輸入。如果以餘弦相似度為例,則對角線元素全為1. 矩陣中每個元素的取值範圍為[0,1]
具有代表性的聚類函式

降維
降維就是在保證資料所具有的代表性特徵或分佈的情況下, 將高維資料轉化為低維資料的過程
作用:
資料視覺化
作為中間過程, 起到精簡資料, 提高其他機器學習演算法效率的作用
分類和降維
聚類和分類都是無監督學習的典型任務,任務之間存在關聯,比如某些高緯資料的分類可以通過降維處理更好的獲得,另外學界研究也表明代表性的分類演算法如k-means與降維演算法如NMF之間存在等價性
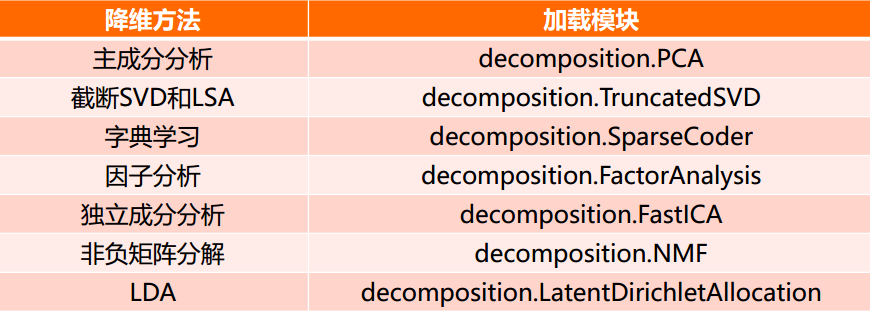
sklearn和降維
降維是機器學習領域的一個重要研究內容,有很多被工業界和學術界接受的典型演算法,截止到目前sklearn庫提供7種降維演算法
降維過程也可以被理解為對資料集的組成成份進行分解(decomposition)的過程,因此sklearn為降維模組命名為decomposition, 在對降維演算法呼叫需要使用sklearn.decomposition模組
sklearn.decomposition的常用演算法

4 K-means方法及應用
k-means演算法也就是k均值演算法
k-means演算法以k為引數,把n個物件分成k個簇, 使簇內具有較高的相似度, 而簇間的相似度較低
處理結果如下
1 隨機選擇k個點作為初始的聚類中心;
2 對於剩下的點,根據其與聚類中心的距離,將其歸入最近的簇
3 對每個簇,計算所有點的均值作為新的聚類中心
4 重複2、 3直到聚類中心不再發生改變
k-meams方法的處理過程如下

建立k-means例項
建立例項
sklearn.cluster.Kmeans()
n_clusters: 用於指定聚類中心的個數, 一般設定此引數, 別的引數使用預設值
init: 初始聚類中心的初始化方法, 預設值是k-means++
max_iter: 最大的跌打次數, 預設值是30
建立例項後, 可以通過例項物件呼叫fit_predict()計算簇中心以及為簇分配序號
其中會傳入引數data, 用於傳入需要載入的資料
返回的結果是一個label, 是聚類後各個資料所屬的標籤
k-means例項還有一個引數 cluster_centers_, 可以通過處理該引數的值來得到更進一步的處理資料
k-means的應用
處理中國1999年各省份的消費水平
處理的技術路線: sklearn.cluster.Kmeans
資料模型為

具體例項程式碼如下
?| 12345678910111213141516171819202122232425262728 | import numpy as npfrom sklearn.cluster import KMeansdef loadData(filePath):fr = open(filePath,'r+')lines = fr.readlines()retData = []retCityName = []for line in lines:items = line.strip().split(",")retCityName.append(items[0])retData.append([float(items[i]) for i in range(1,len(items))])return retData,retCityNameif __name__ == '__main__':data,cityName = loadData('31省市居民家庭消費水平-city.txt')km = KMeans(n_clusters=4)label = km.fit_predict(data)expenses = np.sum(km.cluster_centers_,axis=1)#print(expenses)CityCluster = [[],[],[],[]]for i in range(len(cityName)):CityCluster[label[i]].append(cityName[i])for i in range(len(CityCluster)):print("Expenses:%.2f" % expenses[i])print(CityCluster[i]) |
程式結果

深入程式解釋
label是一個列表型別, 具體的值是 對應的資料被分成哪一類的索引
也就是說, 遍歷cityname的時候同步取得label的值, 就可以對應的把城市名字放到合適的分類中, 這就是下面這句話的來源
?| 1 | CityCluster[label[i]].append(cityName[i]) |
生成的cluster_centers_是一個二維資料, 是一個列表裡面套列表, 裡面列表儲存的是一個分類中, 每個城市的值對應處理得到的結果
所以對這個值在1維上相加得到的就是每一個聚類的綜合的值, 這就是這句話的來源
?| 1 | expenses = np.sum(km.cluster_centers_,axis=1) |
深入k-means
k-means在計算兩條資料相似性時, 預設是使用歐式距離, 且沒有給對應的引數來修改這個預設的計算距離的方法
如果需要修改這個預設的距離方式, 需要修改原始碼
原始碼位置為C:\Python36\Lib\site-packages\sklearn\metrics\pairwise.py
162行的euclidean_distances()函式
建議使用scipy.spatial.distance.cdist方法
回到頂部5 DBSCAN方法及應用
DBSCAN演算法是一種基於密度的聚類演算法
DBSCAN演算法聚類的時候不要預先指定簇的個數
因而最終的簇的個數不確定
DBSCAN演算法將資料點分為三類
核心點: 在半徑Eps內含有超過MinPts資料的點
邊界點: 在半徑Eps內點的數量小於MinPts, 但是落在核心點的鄰域內
噪音點: 既不是核心點也不是邊界點的點
DBSCAN的演算法流程
1.將所有點標記為核心點、邊界點或噪聲點;
2.刪除噪聲點;
3.為距離在Eps之內的所有核心點之間賦予一條邊;
4.每組連通的核心點形成一個簇;
5.將每個邊界點指派到一個與之關聯的核心點的簇中(哪一個核心點的半徑範圍之內)
獲得密度聚類的例項
設Eps=3, MinPts=3, 採用曼哈頓距離聚類

處理核心點, 邊界點, 噪聲點

將不超過Eps=3的點相互圈起來形成一個簇, 核心點鄰域內的點都會被加入到這個簇當中

建立DBSCAN的例項
使用程式碼
sklearn.cluster.DBSCAN()
其中有幾個引數
eps: 兩個樣本被看做鄰居節點的最大距離
min_samples: 簇的樣本數
metric: 距離的計算方式
建立完畢DBSCAN的物件之後
可以後 DBSCAN物件.fix(資料) 來生成一個結果, 這個結果有一個屬性是labels_
這個就是我們需要的標籤
其中標籤中值為-1表示噪聲
例項處理, 學生上網時間分佈
資料

分別是 記錄編號, 學生編號, MAC地址, IP地址, 開始上網時間, 結束上網時間, 上網時長(秒), …
具體程式碼
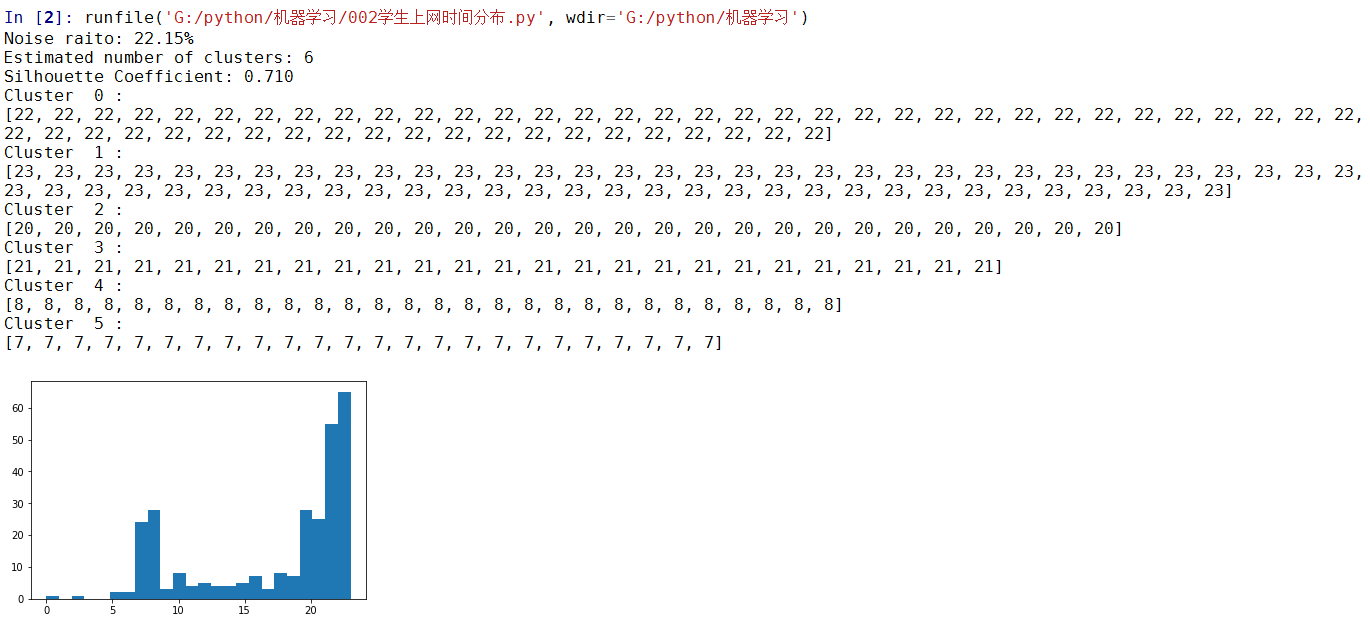
?| 123456789101112131415161718192021222324252627282930313233343536 | import numpy as npimport sklearn.cluster as skcfrom sklearn import metricsimport matplotlib.pyplot as pltonlinetimes = {}with open("學生月上網時間分佈-TestData.txt", encoding="utf8") as f:for line in f:info_list = line.strip().split(',')mac = info_list[2]onlinetime = int(info_list[6])# 獲取上網的起始時候的小時 "2014-07-21 08:14:29.287000000" 這個的08starttime = int(info_list[4].split(' ')[1].split(':')[0])onlinetimes[mac] = (starttime, onlinetime)real_X = np.array([onlinetimes[key] for key in onlinetimes]).reshape((-1, 2))# 只獲取上網的時間點X = real_X[:, 0:1]db = skc.DBSCAN(eps=0.01, min_samples=20).fit(X)labels = db.labels_# 獲得噪聲點比例raito = len(labels[labels[:] == -1]) / len(labels)print('Noise raito:', format(raito, '.2%'))# 顯示演算法效能n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)print('Estimated number of clusters: %d' % n_clusters_)print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels))for i in range(n_clusters_):print('Cluster ', i, ':')print(list(X[labels == i].flatten()))plt.hist(X, 24)plt.show() |
實驗結果
處理資料的技巧
如果原始資料不協調, 不利於資料處理, 可以對原始資料進行無損變化來使得資料大小更加合適處理
具體的處理辦法就是取對數變換
回到頂部6 PCA方法及其應用
PCA(Principal Component Analysis), 主成分分析, 是最常用的一種降維方法, 通常用於高維資料集的探索與視覺化, 還可以用作資料壓縮和預處理等
PCA可以把具有相關性的高維變數合成為線性無關的低維變數,稱為主成分。主成分能夠儘可能保留原始資料的資訊
相關術語
1) 方差
是各個樣本和樣本均值的差的平方和的均值,用來度量一組資料的分散程度
公式
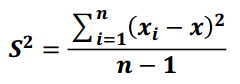
2) 協方差
用於度量兩個變數之間的線性相關性程度,若兩個變數的協方差為0,則可認為二者線性無關。協方差矩陣則是由變數的協方差值構成的矩陣(對稱陣)
公式
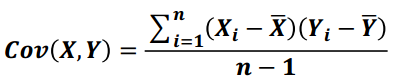
3) 特徵向量
矩陣的特徵向量是描述資料集結構的非零向量
公式

主成分分析的原理
矩陣的主成分就是其協方差矩陣對應的特徵向量,按照對應的特徵值大小進行排序,最大的特徵值就是第一主成分,其次是第二主成分,以此類推
使用PCA
建立PCA物件
sklearn.decomposition.PCA()
主要有兩個引數
n_components: 指定主要成分的個數
svd_solver: 設定特徵值分解的方法, 預設為auto, 其他可選的還有full, arpack, randomized
建立PCA物件之後, 可以通過呼叫fit_transform(data)函式傳入需要降維的資料, 返回的資料就是降維之後處理完畢的資料
例項, 處理鳶尾花資料集
鳶尾花資料集是(150, 4)
可以利用PCA將資料集處理成(150, 2)的資料
處理鳶尾花資料讓其從4維資料程式設計2位平面資料, 具體程式碼如下
?| 1234567891011121314151617181920212223242526272829 | import matplotlib.pyplot as pltfrom sklearn.decomposition import PCAfrom sklearn.datasets import load_irisdata = load_iris()y = data.targetX = data.datapca = PCA(n_components=2)reduced_X = pca.fit_transform(X)red_x, red_y = [], []blue_x, blue_y = [], []green_x, green_y = [], []for i in range(len(reduced_X)):if y[i] == 0:red_x.append(reduced_X[i][0])red_y.append(reduced_X[i][1])elif y[i] == 1:blue_x.append(reduced_X[i][0])blue_y.append(reduced_X[i][1])else:green_x.append(reduced_X[i][0])green_y.append(reduced_X[i][1])plt.scatter(red_x, red_y, c='r', marker='x')plt.scatter(blue_x, blue_y, c='b', marker='D')plt.scatter(green_x, green_y, c='g', marker='.')plt.show() |
具體結果

7 NMF方法及其例項
NMF(Non-negative Matrix Factorization, 非負矩陣分解), 是在矩陣中所有元素均為非負數約束條件之下的矩陣分解方法
基本思想:給定一個非負矩陣V,NMF能夠找到一個非負矩陣W和一個非負矩陣H,使得矩陣W和H的乘積近似等於矩陣V中的值

W矩陣:基礎影象矩陣, 相當於從原矩陣V中抽取出來的特徵
H矩陣:係數矩陣
NMF能夠廣泛應用於影象分析、文字挖掘和語音處理等領域
矩陣分解優化目標: 最小化W矩陣H矩陣的乘積和原始矩陣之間的差別,目標函式如下

基於KL散度的優化目標, 損失函式如下
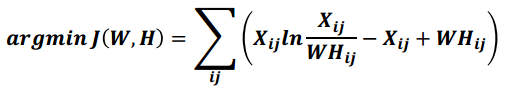
在sklearn庫中,可以使用sklearn.decomposition.NMF載入NMF演算法,主要引數有
生成NMF物件
sklearn.decomposition.NMF()
n_components:用於指定分解後矩陣的單個維度k
init:W矩陣和H矩陣的初始化方式,預設為‘ nndsvdar’
使用NMF對人臉資料進行特徵提取
使用 NMF物件.fit(資料) 來處理資料, 生成的內容還是在NMF物件中
獲取處理資料 NMF物件.components_ 獲取得到的資料
具體使用PCA和NMF處理人臉資料並且對比展示的程式碼如下
?| 123456789101112131415161718192021222324252627282930313233343536373839404142434445 | from numpy.random import RandomStateimport matplotlib.pyplot as pltfrom sklearn.datasets import fetch_olivetti_facesfrom sklearn import decompositionn_row, n_col = 2, 3n_components = n_row * n_colimage_shape = (64, 64)# Load faces datadataset = fetch_olivetti_faces(shuffle=True, random_state=RandomState(0))faces = dataset.datadef plot_gallery(title, images, n_col=n_col, n_row=n_row):plt.figure(figsize=(2. * n_col, 2.26 * n_row)) |