
MySQL--eq_range_index_dive_limit引數學習,MYSQL 5.6 5.7處理資料分佈不均的問題
官方文件如下描述:
This variable indicates the number of equality ranges in an equality comparison condition when the optimizer should switch from using index dives to index statistics in estimating the number of qualifying rows. It applies to evaluation of expressions that have either of these equivalent forms, where the optimizer uses a nonunique index to look up col_name values:
col_name IN(val1, ..., valN)
col_name = val1 OR ... OR col_name = valN
In both cases, the expression contains N equality ranges. The optimizer can make row estimates using index dives or index statistics. If eq_range_index_dive_limit is greater than 0, the optimizer uses existing index statistics instead of index dives if there are eq_range_index_dive_limit or more equality ranges. Thus, to permit use of index dives for up to N equality ranges, set eq_range_index_dive_limit to N + 1. To disable use of index statistics and always use index dives regardless of N, set eq_range_index_dive_limit to 0.
簡單來說就是根據eq_range_index_dive_limit引數設定的閥值來按照不同演算法預估影響行數,對於IN或OR條件中的每個範圍段視為一個元組,對於元組數低於eq_range_index_dive_limit引數閥值時使用index dive,高於閥值時使用
index dive:針對每個元組dive到index中使用索引完成元組數的估算,類似於使用索引進行實際查詢得到影響行數
index statistics:即根據索引的統計數值進行估算,例如索引統計資訊計算出每個等值影響100條資料,那麼IN條件中包含5個等值則影響5*100條記錄
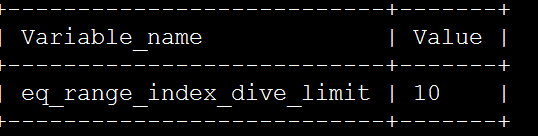
在MySQL 5.6版本中引入eq_range_index_dive_limit引數,預設值為10,通常業務在使用IN時會超過10個值,因此在MySQL 5.7版本中將預設閥值設為200。
========================================
測試環境:
MySQL版本:5.6.20
測試用例表:t_disk_check_result_his,該表存放的1200+臺伺服器的約95萬條磁碟資料
測試目的:通過各種角度來驗證index dive和index statistics兩種方式的優缺點
1、檢查引數
show variables like '%eq_range_index_dive_limit%';
2、檢視查詢使用到的索引和表
SHOW INDEX FROM t_disk_check_result_his \G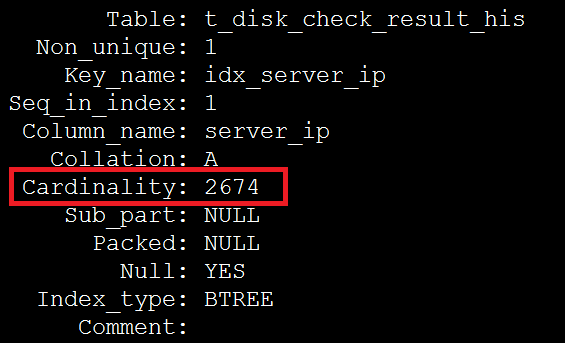
show table status like 't_disk_check_result_his' \G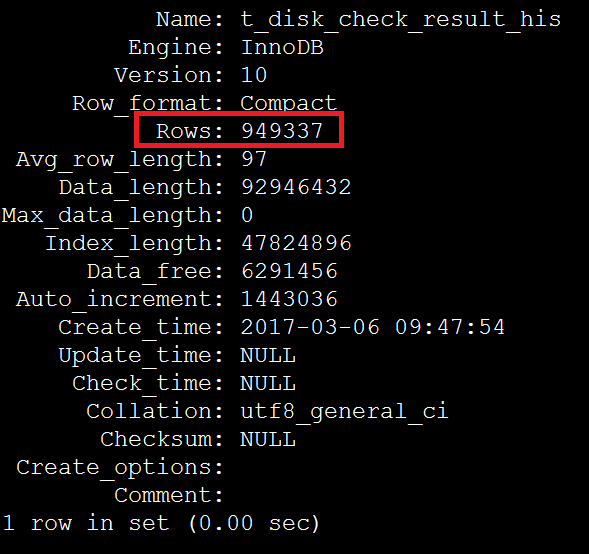
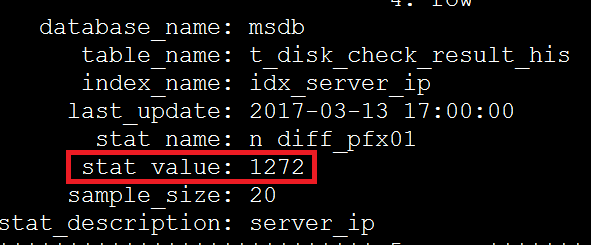
SELECT *
FROM innodb_index_stats
WHERE table_name='t_disk_check_result_his'\G
3、檢視SQK執行計劃
DESC SELECT *
FROM t_disk_check_result_his
WHERE server_ip IN(
'1.1.1.1',
'1.1.1.2',
'1.1.1.3',
);
調整IN條件中的值數量,檢視影響行數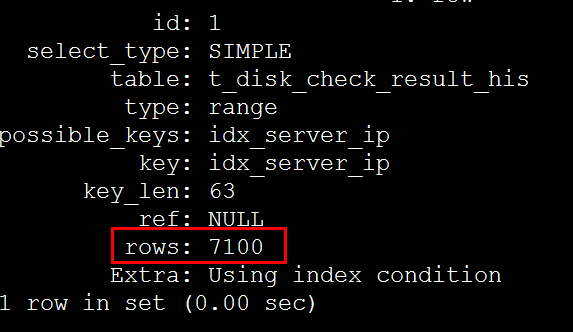
經過多次測試,得到以下資料:
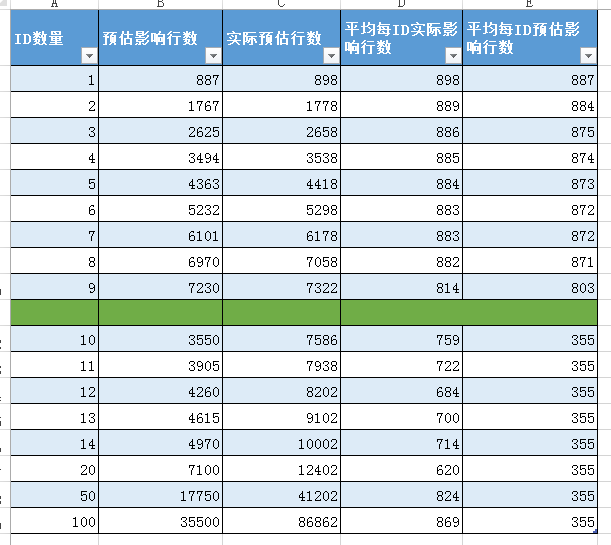
根據步驟2在索引上獲得的資料,949337/2674=355 恰好等於超過eq_range_index_dive_limit引數閥值的平均影響行數,
實際執行發現,對於低於eq_range_index_dive_limit引數閥值的查詢,預估影響行數和實際影響行數相差不多,較為準確。
========================================
使用profiling來檢視, IN條件中包含9個server_ip時,即使用index dive方式消耗如下:
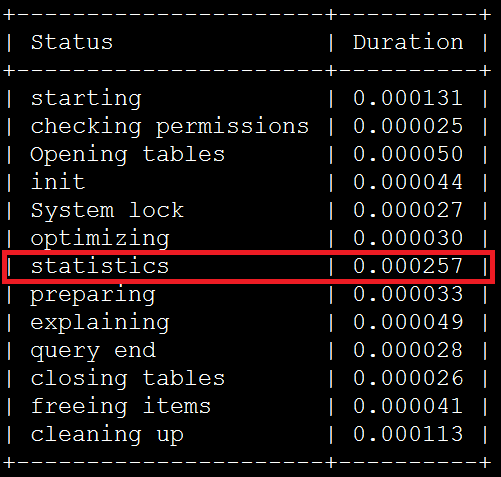
IN條件中包含11個server_ip時,即使用index dive方式消耗如下:
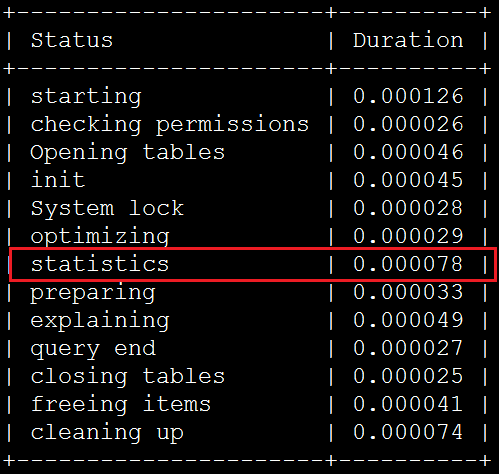
在statistics步驟中,使用index dive方式消耗的時間約是index statistics方式的3.3倍。
========================================
將eq_range_index_dive_limit引數設定為10,來測試IN條件中包含100個server_ip的資源消耗:
將eq_range_index_dive_limit引數設定為200,來測試IN條件中包含100個server_ip的資源消耗:
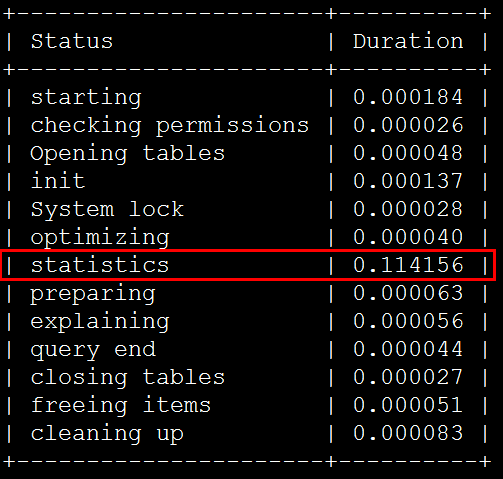
IN條件中包含100個server_ip的相同條件下,使用index dive方式消耗的時間約是index statistics方式的213倍
========================================
結論:
在使用IN或者OR等條件進行查詢時,MySQL使用eq_range_index_dive_limit引數來判斷使用index dive還是使用index statistics方式來進行預估:
1、當低於eq_range_index_dive_limit引數閥值時,採用index dive方式預估影響行數,該方式優點是相對準確,但不適合對大量值進行快速預估。
2、當大於或等於eq_range_index_dive_limit引數閥值時,採用index statistics方式預估影響行數,該方式優點是計算預估值的方式簡單,可以快速獲得預估資料,但相對偏差較大。
=======================================
參考連線:
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html
http://www.cnblogs.com/zhiqian-ali/p/6113829.html
http://blog.163.com/li_hx/blog/static/18399141320147521735442/
MYSQL 5.6 5.7處理資料分佈不均的問題(eq_range_index_dive_limit引數)
處理資料分佈不均,orace資料庫使用額外的統計資料直方圖來完成,而MYSQL
中統計資料只有索引的不同值這樣一個統計資料,那麼我們製出如下資料:
mysql> select * from test.testf;
+------+----------+
| id | name |
+------+----------+
| 1 | gaopeng |
| 2 | gaopeng1 |
| 3 | gaopeng1 |
| 4 | gaopeng1 |
| 5 | gaopeng1 |
| 6 | gaopeng1 |
| 7 | gaopeng1 |
| 8 | gaopeng1 |
| 9 | gaopeng1 |
| 10 | gaopeng1 |
+------+----------+
10 rows in set (0.00 sec)
name 上有一個普通二級索引
mysql> analyze table test.testf;
+------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------+---------+----------+----------+
| test.testf | analyze | status | OK |
+------------+---------+----------+----------+
1 row in set (0.21 sec)
分別作出如下執行計劃:
mysql> explain select * from test.testf where name='gaopeng';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | testf | NULL | ref | name | name | 63 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test.testf where name='gaopeng1';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | testf | NULL | ALL | name | NULL | NULL | NULL | 10 | 90.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到執行計劃是正確的,name='gaopeng'的只有一行選擇了索引,name='gaopeng1'的有9行走了全表。
按理說如果只是記錄不同的那麼這兩個語句的選擇均為1/2,應該會造成執行計劃錯誤,而MYSQL 5.6 5.7中
都做了正確的選擇,那是為什麼呢?
其實原因就在於 eq_range_index_dive_limit這個引數,我們來看一下trace
[email protected]: | | | | | | | | | | | opt: (null): "gaopeng1 <= name <= | [email protected]: | | | | | | | | | | | opt: (null): "gaopeng <= name <= g
[email protected]: | | | | | | | | | | | opt: ranges: ending struct | [email protected]: | | | | | | | | | | | opt: ranges: ending struct
[email protected]: | | | | | | | | | | | opt: index_dives_for_eq_ranges: 1 | [email protected]: | | | | | | | | | | | opt: index_dives_for_eq_ranges: 1
[email protected]: | | | | | | | | | | | opt: rowid_ordered: 1 | [email protected]: | | | | | | | | | | | opt: rowid_ordered: 1
[email protected]: | | | | | | | | | | | opt: using_mrr: 0 | [email protected]: | | | | | | | | | | | opt: using_mrr: 0
[email protected]: | | | | | | | | | | | opt: index_only: 0 | [email protected]: | | | | | | | | | | | opt: index_only: 0
[email protected]: | | | | | | | | | | | opt: rows: 9 | [email protected]: | | | | | | | | | | | opt: rows: 1
[email protected]: | | | | | | | | | | | opt: cost: 11.81 | [email protected]: | | | | | | | | | | | opt: cost: 2.21
我們可以看到 index_dives_for_eq_ranges均為1,rows: 9 rows: 1都是正確的,那麼可以確定是index_dives_for_eq_ranges的作用,實際上
這是一個引數eq_range_index_dive_limit來決定的(equality range optimization of many-valued comparisions),預設為
mysql> show variables like '%eq%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| eq_range_index_dive_limit | 200 |
在官方文件說這個取值是等值範圍比較的時候有多少個需要比較的值
如:
id=1 or id=2 or id=3 那麼他取值就是3+1=4
而這種方法會得到精確的資料,但是增加的是時間成本,如果將
eq_range_index_dive_limit 設定為1:則禁用此功能
eq_range_index_dive_limit 設定為0:則始終開啟
eq_range_index_dive_limit 設定為N:則滿足N-1個這樣的域。
那麼我們設定為eq_range_index_dive_limit=1 後看看
mysql> explain select * from test.testf where name='gaopeng1';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | testf | NULL | ref | name | name | 63 | const | 5 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test.testf where name='gaopeng';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | testf | NULL | ref | name | name | 63 | const | 5 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
可以看到執行計劃已經錯誤 name='gaopeng1' 明顯不應該使用索引,我們再來看看trace
[email protected]: | | | | | | | | | | | opt: ranges: ending struct
[email protected]: | | | | | | | | | | | opt: index_dives_for_eq_ranges: 0
[email protected]: | | | | | | | | | | | opt: rowid_ordered: 1
[email protected]: | | | | | | | | | | | opt: using_mrr: 0
[email protected]: | | | | | | | | | | | opt: index_only: 0
[email protected]: | | | | | | | | | | | opt: rows: 5
[email protected]: | | | | | | | | | | | opt: cost: 7.01
index_dives_for_eq_ranges: 0 rows: 5這個5就是10*1/2導致的,而index_dives_for_eq_ranges=0就是禁用了
在5.7官方文件 p1231頁也有相應說明