
OpenVX, 運算加速庫, NVIDIA
OpenVX
Khronos Group
Khronos Group是一個行業組織,建立開放標準以實現平行計算、圖形、視覺、感測處理和動態媒體在各種平臺和裝置上的編寫和加速。Khronos標準包括Vulkan, OpenGL, OpenGL ES, WebGL, OpenCL, SPIR, SYCL, WebCL, OpenVX, EGL, OpenMAX, OpenVG, OpenSL ES, StreamInput, COLLADA和glTF。
OpenSL:音訊的硬體加速介面。
Vulkan:OpenGL的升級版本。在OpenGL中Context和單一執行緒是繫結的,所以所有需要作用於Context的操作,例如改變渲染狀態,繫結Shader,呼叫Draw Call,都只能在單一執行緒上進行。Vulkan中不再需要依賴於繫結在某個執行緒上的Context,而是用全新的基於Queue的方式向GPU遞交任務,並且提供多種Synchronization的元件讓多執行緒程式設計更加親民。
簡單來說,Khronos的任務就是建立一個統一的硬體和軟體之間的API,這樣無論軟體廠商,還是硬體廠商,都能各行其道,互不干擾了。
概述
官網:
https://www.khronos.org/openvx/

上圖給出了OpenVX的主要用途,以及它和Khronos其他兄弟專案之間的關係。
OpenVX本身也是一個系列標準。它包括:
OpenVX:一個傳統的CV介面。提供包括直方圖、Harris、Canny等特徵運算元的API。
OpenVX SC(Safety Critical):安全版的OpenVX。
OpenVX NN Extension:專門用於提供NN加速方面的API。目前主要集中於CNN的加速,即卷積、池化等操作,對其他NN支援有限。此外,這些API主要用於預測,而非訓練。
Khronos官方提供了一個OpenVX的軟體參考實現,用於軟硬體廠商的測試工作。
相關API文件和參考實現(sample code)參見:
https://www.khronos.org/registry/OpenVX/
Host & Device
和OpenGL類似,一般將CPU稱作Host,而將GPU稱作Device。App執行在Host上,而硬體加速由Device實現。
Device上的記憶體一般不能直接訪問,需要使用vxCreateScalar、vxCreateTensor之類的API,將相關資料傳到Device上。
類似的,有些API也分為Host版本和Device版本,前者用於Host和Device之間的資料交換,而後者用於Device內部資料的交換。
比如,vxCreateTensorAddressing和vxCreateTensorView,都是選擇tensor的某一部分,前者是Host API,而後者是Device API。
陣列的儲存格式
和OpenGL一樣,OpenVX中的tensor,也是列優先儲存的。而C語言是行優先儲存的。
行優先/列優先的概念參見:
http://blog.csdn.net/zhoxier/article/details/8058176
陣列按行/列儲存
OpenCL
官網:
https://www.khronos.org/opencl/
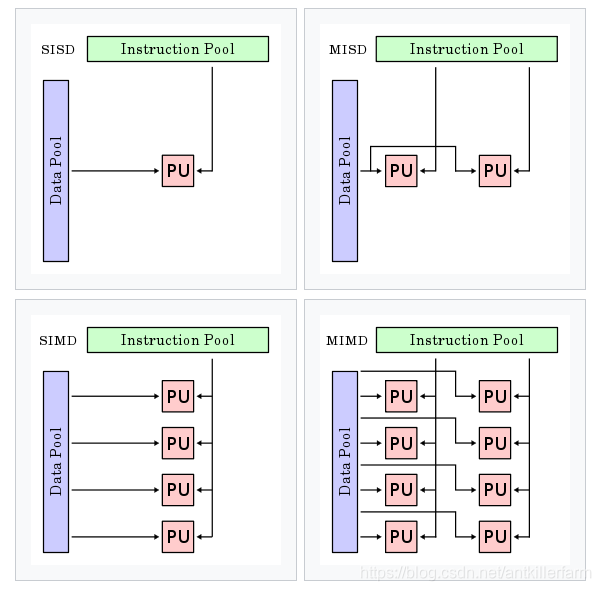
按照Michael J. Flynn的分類方法,計算機的體系結構可分為如下四類:
Single instruction stream single data stream (SISD)
Single instruction stream, multiple data streams (SIMD)
Multiple instruction streams, single data stream (MISD)
Multiple instruction streams, multiple data streams (MIMD)
原圖地址:
https://en.wikipedia.org/wiki/Flynn's_taxonomy
CPU通常是SISD和SIMD的,而GPU則是MISD的,超級計算機則是MIMD的。
OpenCL是一個硬體中立標準,原則上和計算機的體系結構無關。當然現實中,我們主要使用GPU進行運算加速。
和OpenGL、OpenVX的專用性不同,OpenCL主要定位於通用數學運算。OpenGL年代久遠也就罷了。對於像OpenVX這樣的新標準,有的時候其內部實現也有可能依賴於OpenCL。畢竟無論哪個領域的專用計算,最終都可以分解為基本的數學運算。
簡單來說,OpenVX的封裝粒度在層一級,而OpenCL最多隻提供到矩陣運算一級的API。
術語:
Shared Virtual Memory,SVM
Memory consistency model
Multisample anti-aliasing,MSAA
參考:
http://blog.csdn.net/leonwei/article/details/8880012
從零開始學習OpenCL開發(一)架構
SYCL
SYCL是Khronos提供的基於OpenCL的C++介面層。
官網:
ComputeCpp
ComputeCpp是Codeplay公司提供的SYCL介面的實現。它除了支援OpenCL之外,還支援CUDA和C++AMP。
官網:
https://www.codeplay.com/products/computesuite/computecpp
OpenVG
OpenVG是針對諸如Flash和SVG的向量圖形演算法庫提供底層硬體加速介面的免授權費、跨平臺應用程式介面API。
官網:
https://www.khronos.org/openvg/
OpenVG和OpenGL 3D的差異:
1.OpenVG能實現的功能,OpenGL 3D都能實現,後者的功能要強大的多。
2.OpenGL 3D的基本圖元是三角形,而OpenVG的基本圖元是Path,也就是閉合曲線。通常來說,Path的頂點要遠少於三角形。例如,繪製一個圓形,要用很多三角形擬合,但使用Path的話,用3段Bézier curve就可以表示了。
3.OpenVG支援物體任意縮放而不失真,而OpenGL 3D中的物體在大解析度下會有鋸齒。

上圖是OpenVG的pipeline。
運算加速庫
MKL
Intel Math Kernel Library是一套經過高度優化和廣泛執行緒化的數學例程,專為需要極致效能的科學、工程及金融等領域的應用而設計。
官網:
https://software.intel.com/zh-cn/mkl
Neon
Neon是個大路貨的名字,在數值計算領域ARM和Intel都有叫Neon的硬體或技術。
ARM的Neon是適用於ARM Cortex-A系列處理器的一種128位SIMD擴充套件結構。它主要聚焦於矩陣運算,當然也可用於DL領域。
官網:
https://developer.arm.com/technologies/neon
Intel的Neon專為DL設計。
官網:
OpenACC
官網:
PGI
PGI是由The Portland Group開發的平行計算庫,但後者已於2013年被NVIDIA收購。
官網:
HSA
HSA (Heterogeneous System Architecture)是AMD推出的異構系統架構。
官網:
http://www.amd.com/zh-cn/innovations/software-technologies/hsa
NetLib
NetLib是一個數學方面的網站,收集了大量的數學軟體和論文。官網:
知名軟體LAPACK(Linear Algebra PACKage)和BLAS (Basic Linear Algebra Subprograms)的官網就在NetLib:
http://www.netlib.org/lapack/index.html
http://www.netlib.org/blas/index.html
LAPACK和BLAS的歷史非常悠久,是用Fortran語言編寫的。
常用線性代數庫
ATLAS(Automatically Tuned Linear Algebra Soft)
程式碼:
https://sourceforge.net/projects/math-atlas/
安裝:
sudo apt-get install libatlas-base-dev
OpenBLAS
官網:
程式碼:
https://github.com/xianyi/OpenBLAS
作者:張先軼,北京理工大學本碩(2005年、2007年)+中科院博士(2014年)。PerfXLab(澎峰科技)創始人。
個人主頁:
http://xianyi.github.io/index_cn.htm
OpenBLAS需要gfortran參與編譯:
sudo apt install gfortran
需要注意gcc的版本和gfortran的版本必須一致。例如,某臺機器為了專案需要,沒有使用ubuntu預設的gcc版本,這樣即使安裝了gfortran,也還是不行。最後,安裝匹配的gfortran才解決了該問題。
NVIDIA
NVIDIA作為行業龍頭,其影響力甚至在Khronos Group之上,它提出的標準很多成為了行業的事實標準。
最近(2018.2),公司副總M給我們講座的時候,回顧他早年在NVIDIA的經歷,當時他曾擁有數萬股NV的股票,可惜早都賣了。這十幾年來,NV股票經過5次分拆,當初的一股現在要值6500美元。他要不賣,現在可能已經是億萬富翁了。。。
術語
iGPU:Integrated Graphics Processing Unit。
dGPU:Discrete Graphics Processing Unit。
CUDA
CUDA是NVIDIA最早推出的通用數學運算庫。除了基本的數學運算之外,還提供了一些工具包:
cuBLAS:線性計算庫。
NVBLAS:多GPU版的cuBLAS。
cuFFT:FFT計算庫。
nvGRAPH:圖計算庫。(這裡的圖是數學圖論中的圖,和DL框架中的計算圖是兩回事。)
cuRAND:隨機數生成庫。
cuSPARSE;稀疏矩陣計算庫。
cuSOLVER:解線性方程的計算庫。包括解稠密方程的cuSolverDN、解稀疏方程的cuSolverSP和矩陣分解的cuSolverRF。
Deep Learning SDK
cuDNN:DL計算庫。
NCCL:多結點、多GPU的通訊庫。
TensorRT:嵌入式裝置上專用於DL inference的計算庫。
NVIDIA DIGITS:一款web應用工具,可在網頁上對Caffe進行圖形化操作和視覺化。
參考:
https://mp.weixin.qq.com/s/v8-JHd5tWm41WLqR-h6eKA
使用TensorRT整合加速TensorFlow推理
NVDLA
NVIDIA Deep Learning Accelerator是一個開源的用於inference的晶片方案。官網:
NVIDIA DALI
NVIDIA DALI是一個GPU加速的資料增強和影象載入庫,為優化深度學習框架資料pipeline而設計,而其中的NVIDIA nvJPEG是用於JPEG解碼的高效能GPU加速庫。
程式碼:
https://github.com/NVIDIA/dali
Tensor Core
https://mp.weixin.qq.com/s/pPjPLqgXZ8iCPS42vXJpuQ
NVIDIA Tensor Core深度學習核心解析
CUDA實戰
安裝:
http://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
參考:
http://ishare.iask.sina.com.cn/f/17211495.html
深入淺出談CUDA技術
http://peghoty.blog.163.com/blog/static/493464092013016113254852/
CUDA程式設計入門
http://blog.csdn.net/xsc_c/article/category/2186063
某人的平行計算專欄
http://tieba.baidu.com/p/2155772860
GPU和Shader技術的基礎知識
http://www.cnblogs.com/geniusalex/archive/2008/12/26/1941766.html
CPU GPU設計工作原理
http://www.jianshu.com/p/8687a040eb48
GPU處理影象Shader的入門
https://mp.weixin.qq.com/s/bvNnzkOzGYYYewc3G9DOIw
GPU是如何優化執行機器學習演算法的?
https://mp.weixin.qq.com/s/nAwxtOUi6HpIjVOREgEfaA
CUDA程式設計入門極簡教程
https://mp.weixin.qq.com/s/-zdIWkuRZXhsLJmOZljOBw
CUDA程式設計精品教材分享《基於GPU-多核-叢集等並行化程式設計》
CATIA
CATIA是法國達索公司的產品開發旗艦解決方案。作為PLM協同解決方案的一個重要組成部分,它可以通過建模幫助製造廠商設計他們未來的產品,並支援從專案前階段、具體的設計、分析、模擬、組裝到維護在內的全部工業設計流程。CATIA是GPU在工業上的一個重要的應用案例。
官網:
https://www.3ds.com/products-services/catia/
MLPerf
MLPerf是谷歌、百度、斯坦福等聯手打造的基準測量工具,用於測量機器學習軟體與硬體的執行速度。
它的到來代表著原本市場規模較為有限的AI效能比較方案正式踏上發展正軌。簡而言之就是:以後各大公司釋出的AI效能對比不能再王婆賣瓜自賣自誇了。
官網:
RDMA
RDMA網絡卡(Remote Direct Memory Access,這是一種硬體的網路技術,它使得計算機訪問遠端的記憶體時無需遠端機器上CPU的干預)已經可以提供50~100Gbps的網路頻寬和微秒級的傳輸延遲。
目前許多以深度學習為目標應用的GPU機群都部署了這樣的網路。
參考:
https://mp.weixin.qq.com/s/_xcE8RUs0m4gwk3kxpe9jA
基於HTM/RDMA的可擴充套件記憶體事務處理系統