
利用python、tensorflow、opencv實現人臉識別(包會)!
一,前言
本人是機械專業在讀碩士,在完成暑假實踐的時候接觸到了人臉識別,對這一實現很感興趣,所以花了大概十天時間做出了自己的人臉識別。這篇文章應該是很詳細的了所以幫你實現人臉識別應該沒什麼問題。
先說本博文的最終要達到的效果:通過一系列操作,在攝像頭的視訊流中識別特定人的人臉,並且予以標記。
本人通過網上資料的查詢發現這類人臉識別,大多參考了一位日本程式設計師小哥的文章。
關於這個思路的人臉識別網上資料很多,但是有很多細節沒有提到,我在實踐的過程中菜過了無數的坑,希望我這篇文章能夠對你提供更加清晰的思路和操作。先看結果(人醜勿怪)!這個是識別我的臉,別人的臉不會識別到

其實,這已經涉及到了一些機器學習的內容,對於像入門機器學習的同學來說是一個不錯的練手的專案。
二、前期準備工作
首先說,我在剛開始接觸的時候,主要是在各種資料包的安裝上以及環境的配置上花費了巨大的時間,有些資料包升級版本之後與一些功能不相容,出了很多問題,所以。我在這裡說一下我的資料包的版本和python版本。現在可以用anaconda來下載python和各種資料包,但是最新的版本是用python3.6.X,在後面的實踐中可能會出現不同的問題,所以為了安全起見python最好選擇3.5.X的,不要安裝2.X的,與3.X的版本不相容,會出現很多問題。另外再安裝一個tensorflow,pip,keras,sklearn,PIL,numpy,opencv等。其中keras要安裝2.0版本的,opencv安裝3.3.1版本的。tensorflow有CPU版本的和GPU版本的,你可以看一下你適合哪一種,這裡貼出來一些供你參考:
您必須從以下 TensorFlow 型別中選擇其一來進行安裝:
僅支援 CPU 的 TensorFlow。如果您的系統沒有 NVIDIA® GPU,則必須安裝此版本。請注意,此版本的 TensorFlow 通常更容易安裝(用時通常在 5 或 10 分鐘內),所以即使您擁有 NVIDIA GPU,我們也建議先安 裝此版本。預編譯的二進位制檔案將使用 AVX 指令。
支援 GPU 的 TensorFlow。TensorFlow 程式在 GPU 上的執行速度通常要比在 CPU 上快得多。因此,如果您 的系統配有滿足以下所示先決條件的 NVIDIA® GPU,並且您需要執行效能至關重要的應用,則最終應安裝此 版本。
另外我在安裝的過程中發現了幾篇比較不錯的博文供你參考:
在幾篇博文裡你也會看到驗證安裝正確的方法,如果可以的話,說明你安裝成功了,這裡我就不多說了。後面的話你可能還會遇到別的什麼問題,如果還需要安裝什麼模組的話,在安裝也可以。
在硬體方面,你還需要一個USB攝像頭。
總結:
-
USB攝像頭一個;
-
python -- 3.5.X
-
tensorflow
-
opencv -- 3.3.1
-
keras -- 3.0.X
-
sklearn -- 0.19.0
三、正式開始
1,識別人臉
實現人臉識別簡單程式沒幾行,但是我們要實現的是識別這個是誰的臉。首先我們讓系統識別人臉,這是opencv的工作,我們只需要呼叫其中的API函式就可以了。下面是呼叫opencv實現對於人臉的識別。咱們在程式下面對程式進行一些解釋:
import cv2
import sys
from PIL import Image
def CatchUsbVideo(window_name, camera_idx):
cv2.namedWindow(window_name)
#視訊來源,可以來自一段已存好的視訊,也可以直接來自USB攝像頭
cap = cv2.VideoCapture(camera_idx)
#告訴OpenCV使用人臉識別分類器
classfier = cv2.CascadeClassifier("H:\\OpenCV\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml")
#識別出人臉後要畫的邊框的顏色,RGB格式
color = (0, 255, 0)
while cap.isOpened():
ok, frame = cap.read() #讀取一幀資料
if not ok:
break
#將當前幀轉換成灰度影象
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#人臉檢測,1.2和2分別為圖片縮放比例和需要檢測的有效點數
faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
if len(faceRects) > 0: #大於0則檢測到人臉
for faceRect in faceRects: #單獨框出每一張人臉
x, y, w, h = faceRect
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
#顯示影象
cv2.imshow(window_name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
#釋放攝像頭並銷燬所有視窗
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id\r\n" % (sys.argv[0]))
else:
CatchUsbVideo("識別人臉區域", 0)
首先,第一行import cv2,實際上,”cv2”中的”2”並不表示OpenCV的版本號。我們知道,OpenCV是基於C/C++的,”cv”和”cv2”表示的是底層CAPI和C++API的區別,”cv2”表示使用的是C++API。這主要是一個歷史遺留問題,是為了保持向後相容性。PIL是一個模組,如果執行的過程中提示你缺少模組的時候你就要安裝一個模組了,其餘同理,就不再說了。另外在函式Catchusbvideo中,第二個引數指的是你電腦的攝像頭的編號,例如是0,1,2等,如果0不行的話,試一下1。在下邊的人臉識別分類器中是我自己下載的opencv,下載網站是:https://opencv.org/releases.html,如果你是windows選擇對應版本就好,還有就是“H:\\OpenCV\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml”這是我安裝的一個路徑,你也要找到這個路徑並且複製到程式中,這個東西的作用主要是實現對人臉識別的功能,在安裝中還有其他的功能,我也一併列在下面:
人臉檢測器(預設):haarcascade_frontalface_default.xml
人臉檢測器(快速Harr):haarcascade_frontalface_alt2.xml
人臉檢測器(側視):haarcascade_profileface.xml
眼部檢測器(左眼):haarcascade_lefteye_2splits.xml
眼部檢測器(右眼):haarcascade_righteye_2splits.xml
嘴部檢測器:haarcascade_mcs_mouth.xml
鼻子檢測器:haarcascade_mcs_nose.xml
身體檢測器:haarcascade_fullbody.xml
人臉檢測器(快速LBP):lbpcascade_frontalface.xml
另外,如果我們想構建自己的分類器,比如識別火焰、汽車,數,花等,我們依然可以使用OpenCV訓練構建。

對同一個畫面有可能出現多張人臉,因此,我們需要用一個for迴圈將所有檢測到的人臉都讀取出來,然後逐個用矩形框框出來,這就是接下來的for語句的作用。Opencv會給出每張人臉在影象中的起始座標(左上角,x、y)以及長、寬(h、w),我們據此就可以截取出人臉。其中,cv2.rectangle()完成畫框的工作,在這裡外擴了10個畫素以框出比人臉稍大一點的區域。cv2.rectangle()函式的最後兩個引數一個用於指定矩形邊框的顏色,一個用於指定矩形邊框線條的粗細程度。
執行結果:
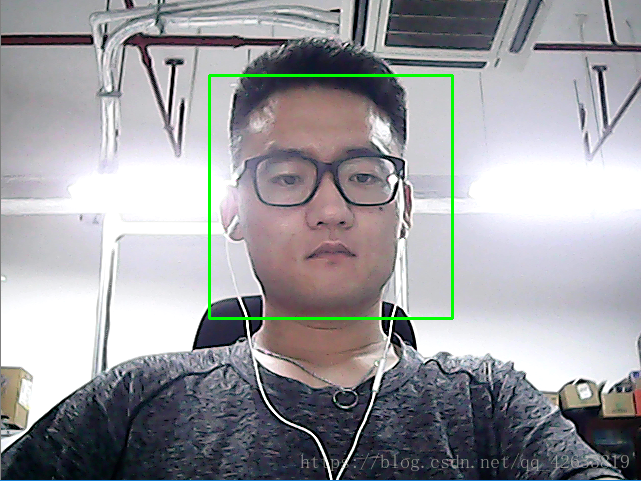
好,看來可以順利的識別出視訊中的臉,搞定!但是我們想做的是識別這個人臉是誰的,這僅僅能識別這是誰的臉,完全不能滿足我們的渴望,接下來我們進行下一步!
2.模型訓練
模型訓練的目的是讓電腦知道,這個臉的特徵是什麼,從而可以在視訊流中識別。在訓練之前必須先準備足夠的臉部照片作為機器學習的資料。
2.1準備機器學習的資料
所謂機器學習就是給程式投喂足夠多的資料,資料越多,準確度和效率也會越高。要想識別出這張人臉屬於誰,我們肯定需要大量的自己的臉和別人的臉,這樣才能區別開。然後將這些資料輸入到Tensorflow中建立我們自己臉的模型。
1.keras簡介
上面提到的日本小哥利用深度學習庫keras來訓練自己的人臉識別模型。 我這裡找到一篇keras的中文文件可能對你有些幫助。另外關於Keras, Keras是由純python編寫的基於theano/tensorflow的深度學習框架。Keras是一個高層神經網路API,支援快速實驗,能夠把你的idea迅速轉換為結果,如果有如下需求,可以優先選擇Keras:
a)簡易和快速的原型設計(keras具有高度模組化,極簡,和可擴充特性)
b)支援CNN和RNN,或二者的結合
c)無縫CPU和GPU切換
Keras的模組結構:
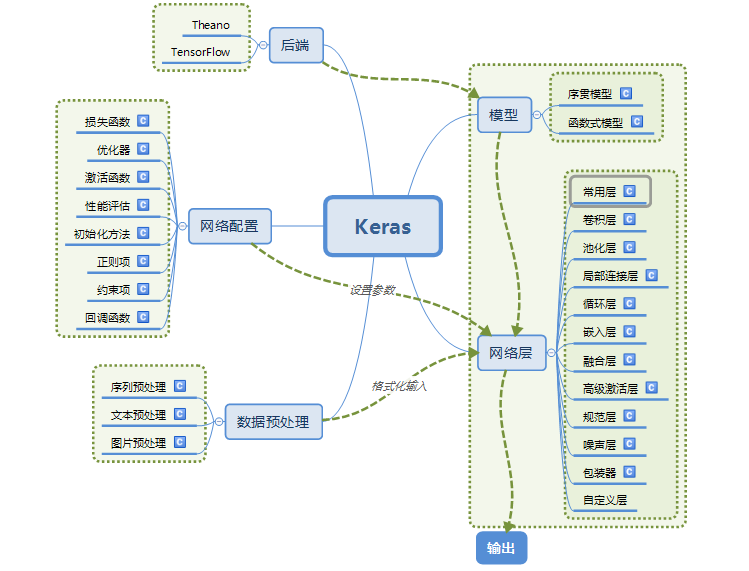
使用Keras搭建一個神經網路:
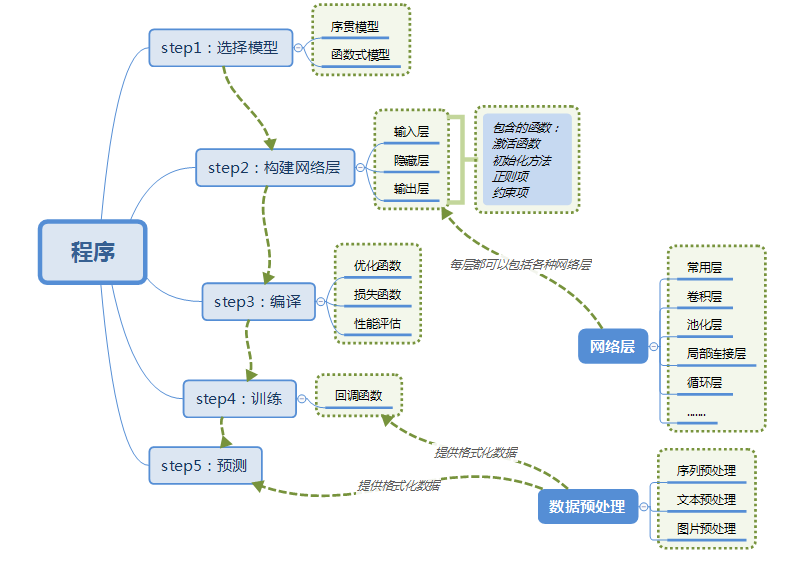
資料格式(data_format):
目前主要有兩種方式來表示張量:
a) th模式或channels_first模式,Theano和caffe使用此模式。
b)tf模式或channels_last模式,TensorFlow使用此模式。
因為我裝的是tensorflow因此我直接使用了keras的Tensorflow版,同時,為了驗證其它深度學習庫的效率和準確率,我還使用了Theano,利用CNN——卷積神經網路來訓練我的人臉識別模型。本節專注把訓練資料準備好。
完整程式碼如下:
import cv2
import sys
from PIL import Image
def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):
cv2.namedWindow(window_name)
#視訊來源,可以來自一段已存好的視訊,也可以直接來自USB攝像頭
cap = cv2.VideoCapture(camera_idx)
#告訴OpenCV使用人臉識別分類器
classfier = cv2.CascadeClassifier("H:\\OpenCV\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml")
#識別出人臉後要畫的邊框的顏色,RGB格式
color = (0, 255, 0)
num = 0
while cap.isOpened():
ok, frame = cap.read() #讀取一幀資料
if not ok:
break
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #將當前楨影象轉換成灰度影象
#人臉檢測,1.2和2分別為圖片縮放比例和需要檢測的有效點數
faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
if len(faceRects) > 0: #大於0則檢測到人臉
for faceRect in faceRects: #單獨框出每一張人臉
x, y, w, h = faceRect
#將當前幀儲存為圖片
img_name = '%s/%d.jpg'%(path_name, num)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image)
num += 1
if num > (catch_pic_num): #如果超過指定最大儲存數量退出迴圈
break
#畫出矩形框
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
#顯示當前捕捉到了多少人臉圖片了,這樣站在那裡被拍攝時心裡有個數,不用兩眼一抹黑傻等著
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame,'num:%d' % (num),(x + 30, y + 30), font, 1, (255,0,255),4)
#超過指定最大儲存數量結束程式
if num > (catch_pic_num): break
#顯示影象
cv2.imshow(window_name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
#釋放攝像頭並銷燬所有視窗
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id face_num_max path_name\r\n" % (sys.argv[0]))
else:
CatchPICFromVideo("擷取人臉", 0, 1000, 'C:\\Users\\Administrator\\Desktop\\Python\\data\\liziqiang')
這段程式碼我們只是在前面程式碼的基礎上增加臉部影象儲存功能,比較簡單。
def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):在函式定義中,幾個引數,反別是視窗名字,攝像頭系列號,捕捉照片數量,以及儲存路徑。根據自己需要進行修改,咱們這裡為了精度高一點,選擇捕捉1000張臉部照片。在你捕捉的時候由於精度的問題,會捕捉許多非臉部的照片,這時候需要你將不是臉部的照片清洗掉,使資料更加準確。另外,我們還需要捕捉另一個人的圖片來提高模型的準確度。然後儲存到另一個資料夾下,注意,一個人的照片儲存到一個資料夾下,不可弄混。截圖完成,就像下圖這樣。
好了,經過前面的資料蒐集,咱們已經差不多準備了2000張照片,準備工作已經做好,下面我們將進行資料模型的訓練!
2.模型訓練
訓練程式建立了一個包含4個卷積層的神經網路(CNN),程式利用這個網路訓練我的人臉識別模型,並將最終訓練結果儲存到硬碟上。在我們實際動手操練之前我們必須先弄明白一個問題——什麼是卷積神經網路(CNN)?
想知道你可以谷歌,另外有關神經網路我會另外寫一篇部落格。這裡就不多做介紹了。
首先建立一個python檔案,命名load_dataset。程式碼如下:
import os
import sys
import numpy as np
import cv2
IMAGE_SIZE = 64
#按照指定影象大小調整尺寸
def resize_image(image, height = IMAGE_SIZE, width = IMAGE_SIZE):
top, bottom, left, right = (0, 0, 0, 0)
#獲取影象尺寸
h, w, _ = image.shape
#對於長寬不相等的圖片,找到最長的一邊
longest_edge = max(h, w)
#計算短邊需要增加多上畫素寬度使其與長邊等長
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
right = dw - left
else:
pass
#RGB顏色
BLACK = [0, 0, 0]
#給影象增加邊界,是圖片長、寬等長,cv2.BORDER_CONSTANT指定邊界顏色由value指定
constant = cv2.copyMakeBorder(image, top , bottom, left, right, cv2.BORDER_CONSTANT, value = BLACK)
#調整影象大小並返回
return cv2.resize(constant, (height, width))
#讀取訓練資料
images = []
labels = []
def read_path(path_name):
for dir_item in os.listdir(path_name):
#從初始路徑開始疊加,合併成可識別的操作路徑
full_path = os.path.abspath(os.path.join(path_name, dir_item))
if os.path.isdir(full_path): #如果是資料夾,繼續遞迴呼叫
read_path(full_path)
else: #檔案
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE)
#放開這個程式碼,可以看到resize_image()函式的實際呼叫效果
#cv2.imwrite('1.jpg', image)
images.append(image)
labels.append(path_name)
return images,labels
#從指定路徑讀取訓練資料
def load_dataset(path_name):
images,labels = read_path(path_name)
#將輸入的所有圖片轉成四維陣列,尺寸為(圖片數量*IMAGE_SIZE*IMAGE_SIZE*3)
#我和閨女兩個人共1200張圖片,IMAGE_SIZE為64,故對我來說尺寸為1200 * 64 * 64 * 3
#圖片為64 * 64畫素,一個畫素3個顏色值(RGB)
images = np.array(images)
print(images.shape)
#標註資料,'liziqiang'資料夾下都是我的臉部影象,全部指定為0,另外一個資料夾下是同學的,全部指定為1
labels = np.array([0 if label.endswith('liziqiang') else 1 for label in labels])
return images, labels
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s path_name\r\n" % (sys.argv[0]))
else:
images, labels = load_dataset("C:\\Users\\Administrator\\Desktop\\Python\\data")
稍微解釋一下resize_image()函式。這個函式的功能是判斷圖片是不是正方形,如果不是則增加短邊的長度使之變成正方形。這樣再呼叫cv2.resize()函式就可以實現等比例縮放了。因為我們指定縮放的比例就是64 x 64,只有縮放之前影象為正方形才能確保影象不失真。例如:

這樣明顯不是正方形。經過程式執行之後要達到這樣的目的。

大概是這麼個意思。
將你捕捉到的照片放在倆個不同的資料夾裡,我在這裡一塊放在了data資料夾裡。

然後再新建一個python檔案,命名為:face_train。新增如下程式碼。
import random
import numpy as np
from sklearn.cross_validation import train_test_split
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.models import load_model
from keras import backend as K
from load_data import load_dataset, resize_image, IMAGE_SIZE
class Dataset:
def __init__(self, path_name):
#訓練集
self.train_images = None
self.train_labels = None
#驗證集
self.valid_images = None
self.valid_labels = None
#測試集
self.test_images = None
self.test_labels = None
#資料集載入路徑
self.path_name = path_name
#當前庫採用的維度順序
self.input_shape = None
#載入資料集並按照交叉驗證的原則劃分資料集並進行相關預處理工作
def load(self, img_rows = IMAGE_SIZE, img_cols = IMAGE_SIZE,
img_channels = 3, nb_classes = 2):
#載入資料集到記憶體
images, labels = load_dataset(self.path_name)
train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size = 0.3, random_state = random.randint(0, 100))
_, test_images, _, test_labels = train_test_split(images, labels, test_size = 0.5, random_state = random.randint(0, 100))
#當前的維度順序如果為'th',則輸入圖片資料時的順序為:channels,rows,cols,否則:rows,cols,channels
#這部分程式碼就是根據keras庫要求的維度順序重組訓練資料集
if K.image_dim_ordering() == 'th':
train_images = train_images.reshape(train_images.shape[0], img_channels, img_rows, img_cols)
valid_images = valid_images.reshape(valid_images.shape[0], img_channels, img_rows, img_cols)
test_images = test_images.reshape(test_images.shape[0], img_channels, img_rows, img_cols)
self.input_shape = (img_channels, img_rows, img_cols)
else:
train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels)
valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels)
test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels)
self.input_shape = (img_rows, img_cols, img_channels)
#輸出訓練集、驗證集、測試集的數量
print(train_images.shape[0], 'train samples')
print(valid_images.shape[0], 'valid samples')
print(test_images.shape[0], 'test samples')
#我們的模型使用categorical_crossentropy作為損失函式,因此需要根據類別數量nb_classes將
#類別標籤進行one-hot編碼使其向量化,在這裡我們的類別只有兩種,經過轉化後標籤資料變為二維
train_labels = np_utils.to_categorical(train_labels, nb_classes)
valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
test_labels = np_utils.to_categorical(test_labels, nb_classes)
#畫素資料浮點化以便歸一化
train_images = train_images.astype('float32')
valid_images = valid_images.astype('float32')
test_images = test_images.astype('float32')
#將其歸一化,影象的各畫素值歸一化到0~1區間
train_images /= 255
valid_images /= 255
test_images /= 255
self.train_images = train_images
self.valid_images = valid_images
self.test_images = test_images
self.train_labels = train_labels
self.valid_labels = valid_labels
self.test_labels = test_labels
#CNN網路模型類
class Model:
def __init__(self):
self.model = None
#建立模型
def build_model(self, dataset, nb_classes = 2):
#構建一個空的網路模型,它是一個線性堆疊模型,各神經網路層會被順序新增,專業名稱為序貫模型或線性堆疊模型
self.model = Sequential()
#以下程式碼將順序新增CNN網路需要的各層,一個add就是一個網路層
self.model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape = dataset.input_shape)) #1 2維卷積層
self.model.add(Activation('relu')) #2 啟用函式層
self.model.add(Convolution2D(32, 3, 3)) #3 2維卷積層
self.model.add(Activation('relu')) #4 啟用函式層
self.model.add(MaxPooling2D(pool_size=(2, 2))) #5 池化層
self.model.add(Dropout(0.25)) #6 Dropout層
self.model.add(Convolution2D(64, 3, 3, border_mode='same')) #7 2維卷積層
self.model.add(Activation('relu')) #8 啟用函式層
self.model.add(Convolution2D(64, 3, 3)) #9 2維卷積層
self.model.add(Activation('relu')) #10 啟用函式層
self.model.add(MaxPooling2D(pool_size=(2, 2))) #11 池化層
self.model.add(Dropout(0.25)) #12 Dropout層
self.model.add(Flatten()) #13 Flatten層
self.model.add(Dense(512)) #14 Dense層,又被稱作全連線層
self.model.add(Activation('relu')) #15 啟用函式層
self.model.add(Dropout(0.5)) #16 Dropout層
self.model.add(Dense(nb_classes)) #17 Dense層
self.model.add(Activation('softmax')) #18 分類層,輸出最終結果
#輸出模型概況
self.model.summary()
#訓練模型
def train(self, dataset, batch_size = 20, nb_epoch = 10, data_augmentation = True):
sgd = SGD(lr = 0.01, decay = 1e-6,
momentum = 0.9, nesterov = True) #採用SGD+momentum的優化器進行訓練,首先生成一個優化器物件
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy']) #完成實際的模型配置工作
#不使用資料提升,所謂的提升就是從我們提供的訓練資料中利用旋轉、翻轉、加噪聲等方法創造新的
#訓練資料,有意識的提升訓練資料規模,增加模型訓練量
if not data_augmentation:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size = batch_size,
nb_epoch = nb_epoch,
validation_data = (dataset.valid_images, dataset.valid_labels),
shuffle = True)
#使用實時資料提升
else:
#定義資料生成器用於資料提升,其返回一個生成器物件datagen,datagen每被呼叫一
#次其生成一組資料(順序生成),節省記憶體,其實就是python的資料生成器
datagen = ImageDataGenerator(
featurewise_center = False, #是否使輸入資料去中心化(均值為0),
samplewise_center = False, #是否使輸入資料的每個樣本均值為0
featurewise_std_normalization = False, #是否資料標準化(輸入資料除以資料集的標準差)
samplewise_std_normalization = False, #是否將每個樣本資料除以自身的標準差
zca_whitening = False, #是否對輸入資料施以ZCA白化
rotation_range = 20, #資料提升時圖片隨機轉動的角度(範圍為0~180)
width_shift_range = 0.2, #資料提升時圖片水平偏移的幅度(單位為圖片寬度的佔比,0~1之間的浮點數)
height_shift_range = 0.2, #同上,只不過這裡是垂直
horizontal_flip = True, #是否進行隨機水平翻轉
vertical_flip = False) #是否進行隨機垂直翻轉
#計算整個訓練樣本集的數量以用於特徵值歸一化、ZCA白化等處理
datagen.fit(dataset.train_images)
#利用生成器開始訓練模型
self.model.fit_generator(datagen.flow(dataset.train_images, dataset.train_labels,
batch_size = batch_size),
samples_per_epoch = dataset.train_images.shape[0],
nb_epoch = nb_epoch,
validation_data = (dataset.valid_images, dataset.valid_labels))
MODEL_PATH = './liziqiang.face.model.h5'
def save_model(self, file_path = MODEL_PATH):
self.model.save(file_path)
def load_model(self, file_path = MODEL_PATH):
self.model = load_model(file_path)
def evaluate(self, dataset):
score = self.model.evaluate(dataset.test_images, dataset.test_labels, verbose = 1)
print("%s: %.2f%%" % (self.model.metrics_names[1], score[1] * 100))
#識別人臉
def face_predict(self, image):
#依然是根據後端系統確定維度順序
if K.image_dim_ordering() == 'th' and image.shape != (1, 3, IMAGE_SIZE, IMAGE_SIZE):
image = resize_image(image) #尺寸必須與訓練集一致都應該是IMAGE_SIZE x IMAGE_SIZE
image = image.reshape((1, 3, IMAGE_SIZE, IMAGE_SIZE)) #與模型訓練不同,這次只是針對1張圖片進行預測
elif K.image_dim_ordering() == 'tf' and image.shape != (1, IMAGE_SIZE, IMAGE_SIZE, 3):
image = resize_image(image)
image = image.reshape((1, IMAGE_SIZE, IMAGE_SIZE, 3))
#浮點並歸一化
image = image.astype('float32')
image /= 255
#給出輸入屬於各個類別的概率,我們是二值類別,則該函式會給出輸入影象屬於0和1的概率各為多少
result = self.model.predict_proba(image)
print('result:', result)
#給出類別預測:0或者1
result = self.model.predict_classes(image)
#返回類別預測結果
return result[0]
if __name__ == '__main__':
dataset = Dataset('./data/')
dataset.load()
model = Model()
model.build_model(dataset)
#先前新增的測試build_model()函式的程式碼
model.build_model(dataset)
#測試訓練函式的程式碼
model.train(dataset)
if __name__ == '__main__':
dataset = Dataset('./data/')
dataset.load()
model = Model()
model.build_model(dataset)
model.train(dataset)
model.save_model(file_path = './model/liziqiang.face.model.h5')
if __name__ == '__main__':
dataset = Dataset('./data/')
dataset.load()
#評估模型
model = Model()
model.load_model(file_path = './model/liziqiang.face.model.h5')
model.evaluate(dataset)
執行程式結果:
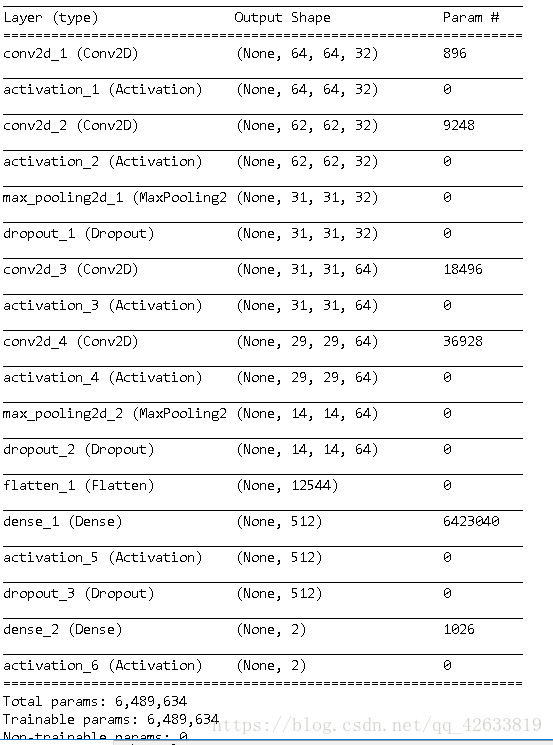
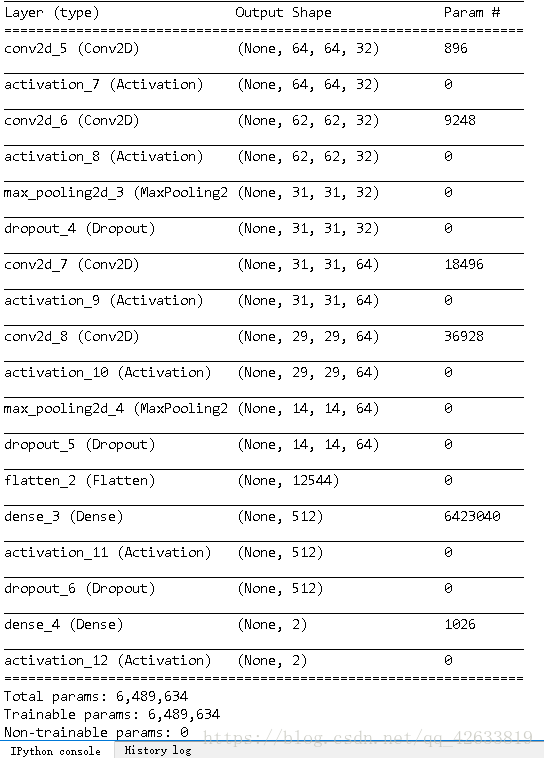

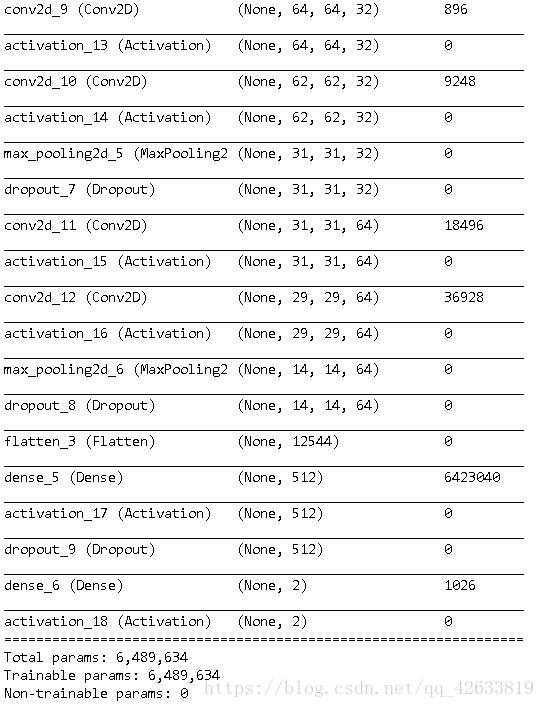

可以看到,最後我們對資料進行了驗證,準確率達到了99.83%。結果較為理想,並且在model下面也得到了我i們的訓練資料。

由此,我們最重要的訓練資料也完成了,加下來就是驗證我們訓練資料的效果的時候了。
3、識別人臉
新建python檔案,命名:Face_recognition。程式碼如下:
#-*- coding: utf-8 -*-
import cv2
import sys
import gc
from face_train import Model
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id\r\n" % (sys.argv[0]))
sys.exit(0)
#載入模型
model = Model()
model.load_model(file_path = './model/liziqiang.face.model.h5')
#框住人臉的矩形邊框顏色
color = (0, 255, 0)
#捕獲指定攝像頭的實時視訊流
cap = cv2.VideoCapture(0)
#人臉識別分類器本地儲存路徑
cascade_path = "H:\\opencv\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml"
#迴圈檢測識別人臉
while True:
ret, frame = cap.read() #讀取一幀視訊
if ret is True:
#影象灰化,降低計算複雜度
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
else:
continue
#使用人臉識別分類器,讀入分類器
cascade = cv2.CascadeClassifier(cascade_path)
#利用分類器識別出哪個區域為人臉
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
#擷取臉部影象提交給模型識別這是誰
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
faceID = model.face_predict(image)
#如果是“我”
if faceID == 0:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 2)
#文字提示是誰
cv2.putText(frame,'liziqiang',
(x + 30, y + 30), #座標
cv2.FONT_HERSHEY_SIMPLEX, #字型
1, #字號
(255,0,255), #顏色
2) #字的線寬
else:
pass
cv2.imshow("識別朕", frame)
#等待10毫秒看是否有按鍵輸入
k = cv2.waitKey(10)
#如果輸入q則退出迴圈
if k & 0xFF == ord('q'):
break
#釋放攝像頭並銷燬所有視窗
cap.release()
cv2.destroyAllWindows()好,最終實現的結果就是文章開頭的時候的效果。希望能幫到你!
有什麼問題我會盡量回答!