
簡單理解Hadoop(Hadoop是什麼、如何工作)
一、Hadoop主要的任務部署分為3個部分,分別是:Client機器,主節點和從節點。主節點主要負責Hadoop兩個關鍵功能模組HDFS、Map Reduce的監督。當Job Tracker使用Map Reduce進行監控和排程資料的並行處理時,名稱節點則負責HDFS監視和排程。從節點負責了機器執行的絕大部分,擔當所有資料儲存和指令計算的苦差。每個從節點既扮演者資料節點的角色又衝當與他們主節點通訊的守護程序。守護程序隸屬於Job Tracker,資料節點在歸屬於名稱節點。
二、Hadoop核心和特點
Hadoop的核心就是HDFS和MapReduce,而兩者只是理論基礎,不是具體可使用的高階應用。
HDFS的設計特點是:
1、大資料檔案,非常適合上T級別的大檔案或者一堆大資料檔案的儲存,如果檔案只有幾個G甚至更小就沒啥意思了。
2、檔案分塊儲存,HDFS會將一個完整的大檔案平均分塊儲存到不同計算器上,它的意義在於讀取檔案時可以同時從多個主機取不同區塊的檔案,多主機讀取比單主機讀取效率要高得多得都。
3、流式資料訪問,一次寫入多次讀寫,這種模式跟傳統檔案不同,它不支援動態改變檔案內容,而是要求讓檔案一次寫入就不做變化,要變化也只能在檔案末新增內容。
4、廉價硬體,HDFS可以應用在普通PC機上,這種機制能夠讓給一些公司用幾十臺廉價的計算機就可以撐起一個大資料叢集。
5、硬體故障,HDFS認為所有計算機都可能會出問題,為了防止某個主機失效讀取不到該主機的塊檔案,它將同一個檔案塊副本分配到其它某幾個主機上,如果其中一臺主機失效,可以迅速找另一塊副本取檔案。
HDFS的關鍵元素:
1)Block:將一個檔案進行分塊,通常是64M。
2)NameNode:儲存整個檔案系統的目錄資訊、檔案資訊及分塊資訊,這是由唯一 一臺主機專門儲存,當然這臺主機如果出錯,NameNode就失效了。在 Hadoop2.* 開始支援 activity-standy 模式----如果主 NameNode 失效,啟動備用主機執行 NameNode。
3)DataNode:分佈在廉價的計算機上,用於儲存Block塊檔案。
MapReduce:
我們要數圖書館中的所有書。你數1號書架,我數2號書架。這就是“Map”。我們人越多,數書就更快。
現在我們到一起,把所有人的統計數加在一起。這就是“Reduce”。
通俗說MapReduce是一套從海量源資料提取分析元素最後返回結果集的程式設計模型,將檔案分散式儲存到硬碟是第一步,而從海量資料中提取分析我們需要的內容就是MapReduce做的事了。
MapReduce的基本原理就是:將大的資料分析分成小塊逐個分析,最後再將提取出來的資料彙總分析,最終獲得我們想要的內容。當然怎麼分塊分析,怎麼做Reduce操作非常複雜,Hadoop已經提供了資料分析的實現,我們只需要編寫簡單的需求命令即可達成我們想要的資料。
Hadoop典型應用有:搜尋、日誌處理、推薦系統、資料分析、視訊影象分析、資料儲存等。
三、Hadoop的叢集主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker組成。
如下圖所示:
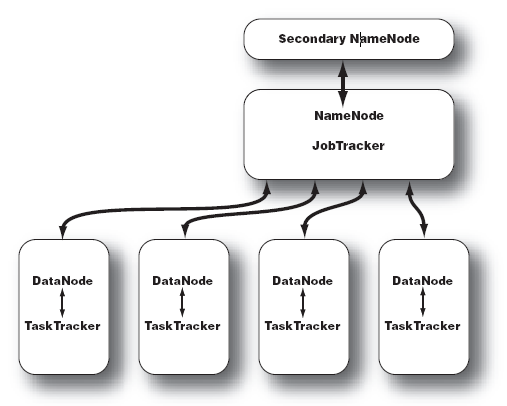
1)NameNode:記錄了檔案是如何被拆分成block以及這些block都儲存到了那些DateNode節點 .
2)NameNode:儲存了檔案系統執行的狀態資訊 .
3)DataNode:儲存被拆分的blocks .
4)Secondary NameNode:幫助 NameNode 收集檔案系統執行的狀態資訊 .
5)JobTracker:當有任務提交到 Hadoop 叢集的時候負責 Job 的執行,負責排程多個 TaskTracker .
6)TaskTracker:負責某一個 map 或者 reduce 任務 .
轉自:http://os.51cto.com/art/201211/364374.htm#topx
http://blessht.iteye.com/blog/2095675
http://os.51cto.com/art/201207/346023.htm