
玩轉flume+Kafka配置
一、FLUME介紹
Flume是一個分散式、可靠、和 高可用 的海量日誌聚合的系統,支援在系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(可定製)的能力。
設計目標:
(1) 可靠性
當節點出現故障時,日誌能夠被傳送到其他節點上而不會丟失。Flume提供了三種級別的可靠性保障,從強到弱依次分別為:end-to-end(收到資料agent首先將event寫到磁碟上,當資料傳送成功後,再刪除;如果資料傳送失敗,可以重新發送。),Store on failure(這也是scribe採用的策略,當資料接收方crash時,將資料寫到本地,待恢復後,繼續傳送),Best effort(資料傳送到接收方後,不會進行確認)。
(2) 可擴充套件性
Flume採用了三層架構,分別為agent,collector和storage,每一層均可以水平擴充套件。其中,所有agent和collector由master統一管理,這使得系統容易監控和維護,且master允許有多個(使用ZooKeeper進行管理和負載均衡),這就避免了單點故障問題。
(3) 可管理性
所有agent和colletor由master統一管理,這使得系統便於維護。多master情況,Flume利用ZooKeeper和gossip,保證動態配置資料的一致性。使用者可以在master上檢視各個資料來源或者資料流執行情況,且可以對各個資料來源配置和動態載入。Flume提供了web 和shell script command兩種形式對資料流進行管理。
(4) 功能可擴充套件性
使用者可以根據需要新增自己的agent,collector或者storage。此外,Flume自帶了很多元件,包括各種agent(file, syslog等),collector和storage(file,HDFS等)。
二、Flume 的 一些核心概念:
元件名稱 功能介紹| Agent代理 | 使用JVM 執行Flume。每臺機器執行一個agent,但是可以在一個agent中包含多個sources和sinks。 |
| Client客戶端 | 生產資料,執行在一個獨立的執行緒。 |
| Source源 | 從Client收集資料,傳遞給Channel。 |
| Sink接收器 | 從Channel收集資料,進行相關操作,執行在一個獨立執行緒。 |
| Channel通道 | 連線 sources 和 sinks ,這個有點像一個佇列。 |
| Events事件 | 傳輸的基本資料負載。 |
三、Flume的整體構成圖

Paste_Image.png
注意
源將事件寫到一個多或者多個通道中。
接收器只從一個通道接收事件。
代理可能會有多個源、通道與接收器。
四、Flume環境配置

Paste_Image.png
- 安裝包內容如下

Paste_Image.png
- 配置檔案
常用配置模式一
掃描指定檔案
agent.sources = s1
agent.channels = c1
agent.sinks = sk1 agent.sources.s1.type=exec
agent.sources.s1.command=tail -F /Users/it-od-m/Downloads/abc.log
agent.sources.s1.channels=c1
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSinkagent.sinks.k1.brokerList=127.0.0.1:9092agent.sinks.k1.topic=testKJ1agent.sinks.k1.serializer.class=kafka.serializer.StringEncoderagent.sinks.k1.channel=c1
常用配置模式二
Agent名稱定義為agent.
Source:可以理解為輸入端,定義名稱為s1
channel:傳輸頻道,定義為c1,設定為記憶體模式
sinks:可以理解為輸出端,定義為sk1,
agent.sources = s1
agent.channels = c1
agent.sinks = sk1
#設定Source的內省為netcat 埠為5678,使用的channel為c1
agent.sources.s1.type = netcat
agent.sources.s1.bind = localhost
agent.sources.s1.port = 3456
agent.sources.s1.channels = c1
#設定Sink為logger模式,使用的channel為c1
agent.sinks.sk1.type = logger
agent.sinks.sk1.channel = c1
#設定channel資訊
agent.channels.c1.type = memory #記憶體模式
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100 #傳輸引數設定。常用配置模式三
掃描目錄新增檔案
agent.sources = s1
agent.channels = c1
agent.sinks = sk1
#設定spooldir
agent.sources.s1.type = spooldir
agent.sources.s1.spoolDir = /Users/it-od-m/logs
agent.sources.s1.fileHeader = true
agent.sources.s1.channels = c1
agent.sinks.sk1.type = logger
agent.sinks.sk1.channel = c1
#In Memory !!!
agent.channels.c1.type = memory
agent.channels.c1.capacity = 10004
agent.channels.c1.transactionCapacity = 100我們今天重點使用第一種模式,因為要與Kafka相結合。
配置好引數以後,回到如下目錄:

Paste_Image.png
使用如下命令啟動Flume:
./bin/flume-ng agent -n agent -c conf -f conf/hw.conf -Dflume.root.logger=INFO,console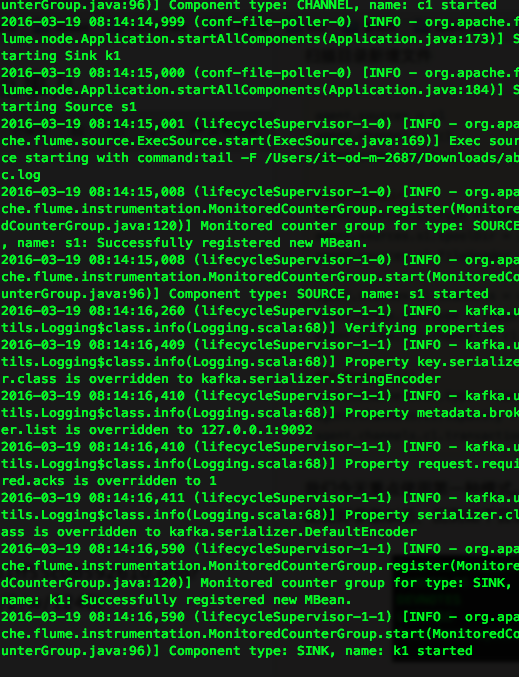
Paste_Image.png
最後一行顯示Component type:SINK,name:k1 started表示啟動成功。
在啟動Flume之前,Zookeeper和Kafka要先啟動成功,不然啟動Flume會報連不上Kafka的錯誤。
1、使用 ./zkServer.sh start 啟動zookeeper。
./kafka-server-start.sh -daemon ../config/server.properties3、使用Kafka預設提供的Consumer來接收訊息
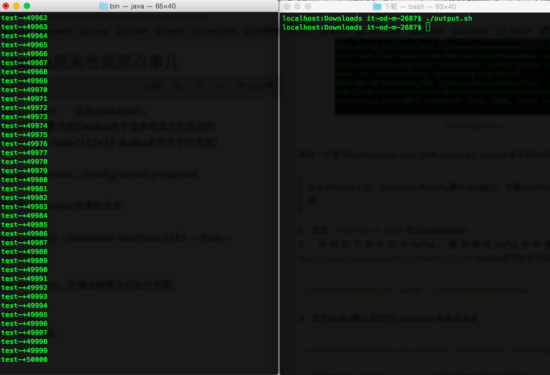
./kafka-console-consumer.sh -zookeeper localhost:2181 --from-beginning --topic testKJ14、編寫簡單Shell指令碼output.sh,並修改許可權為可執行許可權
for((i=0;i<=50000;i++));
do echo "test-"+$i>>abc.log;
done迴圈向abc.log檔案插入test文字訊息。5、執行output.sh。
Paste_Image.png
整個過程流程如下:

Paste_Image.png
至此簡單的使用介紹已經講完,關於Flume還有非常多的屬性和配置技巧需要我們去挖掘,我們以此文章作為開篇為的是為以後原始碼分析作為鋪墊。