
資料探勘---關聯規則---ECLAT演算法
阿新 • • 發佈:2019-01-08
關聯規則用於發現交易資料中,不同商品之間的關係,這些規則反映了顧客的購買行為模式。如顧客經常在購買A商品的時候也會購買B商品,著名的“啤酒與尿布”的案例就是關聯規則的成功應用案例
導語
不同於Apriori和FP演算法所採用的按照交易事務來水平劃分項集的資料探勘方式,把資料集中的項劃歸到每個事務下,ECLAT演算法採用了另一種思路:把資料集中的事務劃歸到每個項下。本文采用如下資料:
A;B;E;
B;D;
B;C;
A;B;D
A;C;
B;C;
A;C;
A;B;C;E;
A;B;C;
下表左邊為Apriori、FP演算法所採用的資料結構,右邊是ECLAT演算法所採用的資料結構兩部分:
| 事務 | 項 | 項 | 事務 |
|---|---|---|---|
| T1 | A;B;E | A | T1;T4;T5:T7;T8;T9 |
| T2 | B;D | B | T1;T2;T3;T4;T6;T8;T9 |
| T3 | B;C | C | T3;T5;T6;T7;T8;T9 |
| T4 | A;B;D | D | T2;T4 |
| T5 | A;C | E | T1;T8 |
| T6 | B;C | ||
| T7 | A;C | ||
| T8 | A;B;C;E | ||
| T9 | A;B;C |
演算法介紹
ECLAT演算法把資料庫事務劃歸到每個項下,使得該演算法相較於Apriori和FP-Growth演算法可以基於集合運算更簡便的得到頻繁項集,該演算法得到頻繁項集的基本思路如下:
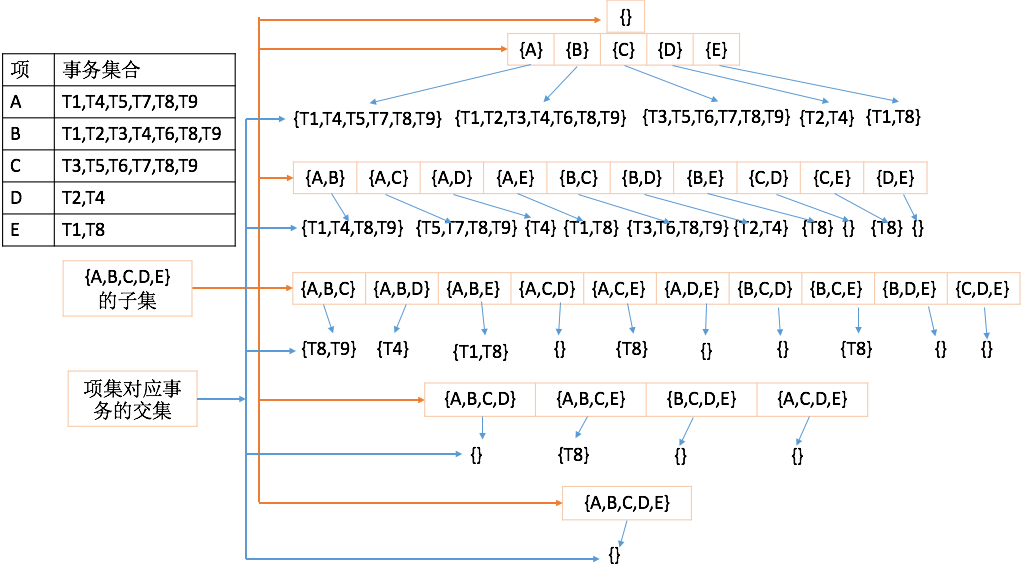
- 首先對資料庫進行一次遍歷,生成項對應的事務集,如上圖左上角表格T1。
- 然後把所有項作為一個集合I_all,求該集合的子集,設第i個子集為I_i,如上圖中橘黃色箭頭指示的集合列表。
- 對每個子集I_i中的項對應的事務集合求交集為T_i,如上圖藍色箭頭指示的集合列表
- T_i中元素個數大於閥值的集合,即為頻繁項集。
如果設定頻繁項的頻次閥值為2,則上圖中紅色的集合為頻繁項集。
簡單實現
ECLAT 演算法只需要一次資料庫的遍歷,生成以項(item)為key,以出現該item的交易事務Id所組成的集合為value的map。然後頻繁項集就可以基於該map獲取到。其獲取頻繁項集的實現程式碼如下:
package association;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import set.SetUtils;
public class ECLAT {
public static String SPLIT = ";";
public static int F = 2;
public static double C = 0.7;
public static List<String> transList = new ArrayList<String>();
static {
transList.add("T1;A;B;E;");
transList.add("T2;B;D;");
transList.add("T3;B;C;");
transList.add("T4;A;B;D;");
transList.add("T5;A;C;");
transList.add("T6;B;C;");
transList.add("T7;A;C;");
transList.add("T8;A;B;C;E;");
transList.add("T9;A;B;C;");
}
private Map<String,Set<String>> datas;
private void etl(){
datas = new HashMap<String, Set<String>>();
for (String string : transList) {
String[] records = string.split(SPLIT);
for(int i = 1;i<records.length;i++){
if(!datas.containsKey(records[i])){
datas.put(records[i],new HashSet<String>());
}
datas.get(records[i]).add(records[0]);
}
}
}
public List<String> getFItems(){
etl();
Set<String> keys = datas.keySet();
Set<String> items = new HashSet<String>();
items.addAll(keys);
ArrayList<Set<String>> subsets = SetUtils.getSubset(items);
Set<String> tmp = new HashSet<String>();
List<String> fItems = new ArrayList<String>();
for (Set<String> set : subsets) {
tmp.clear();
Iterator<String> it = set.iterator();
if(it.hasNext()){
tmp.addAll(datas.get(it.next()));
while(it.hasNext() && tmp.size()>=F){
tmp.retainAll(datas.get(it.next()));
}
}
if(tmp.size()>=F){
fItems.add(set.toString()+":"+tmp.size());
}
}
return fItems;
}
public static void main(String[] args) {
ECLAT eclat = new ECLAT();
List<String> fItems = eclat.getFItems();
for (String string : fItems) {
System.out.println(string);
}
}
} 說明:轉載自http://westerly-lzh.github.io/cn/2015/09/DM003-ECLAT/
上面的網址似乎需要翻牆,為了更加方便檢視,所以就複製了下內容。