
Python 爬蟲4——使用正則表示式篩選內容
之前說過,使用urllib和urllib2,只是為了獲取指定URL的html內容,而對內容進行解析和篩選,則需要藉助python中的正則表示式來完成。
一、預備知識:
1.正則表示式簡述:
什麼是正則表示式?正則表示式就是可以匹配文字片段的模式,最簡單的正則表示式就是一個字串,用於在文字中匹配到此字串自身。
2.常用正則表示式:
設計正則表示式的時候有幾個注意點如下:
a.特殊符號需要加轉移符:如要匹配'china.com',則正則表示式格式應為'china\\.com';
b.字符集(使用中括號[]來包含字串組成字符集):如[a-z]表示匹配從a到z之間的字元;此外,還有一個反轉字符集,使用^符號開頭
c.選擇符:如要匹配'python'和'page',寫出來的模式為'python|page',其中‘|’是管道符號;
d.子模式:如‘p(ython|age)’;
e.可選項:在模式後面加上問好(?),那該模式就變成了可選項,即其可能出現在匹配到的字串中,但是並非必須的,如r'(http://)?(www.)?shuhe.com'可匹配的結果有:
http://www.shuhe.com、http://shuhe.com、www.shuhe.com、shuhe.com
f.重複子模式:
(pattern)*:允許模式重複0次或多次
(pattern)+:允許模式重複1次或多次
(pattern){m,n}:允許模式重複m~n次
例如:
r'w*\.python\.org'匹配'www.python.org'、'.python.org'、'wwwwww.python.org'
r'w+\.python\.org'匹配'w.python.org';但不匹配'.python.org'
r'w{3,4}\.python\.org'只能匹配'www.python.org'和'wwww.python.org'
二、re模板的使用:
在python中封裝了一些常用的正則表示式在re模板
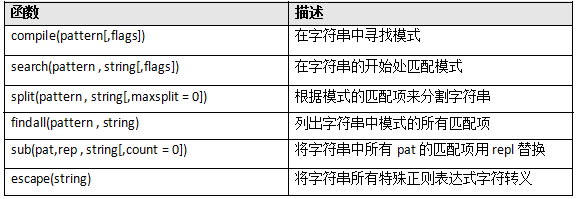
上述是re中常用的正則表示式,使用步驟為:
1.先將正則表示式的字串形式編譯為Pattern例項;
2.然後使用Pattern例項處理文字並獲得匹配結果(一個Match例項);
3.最後使用Match例項獲得資訊,進行其他的操作。
例如:
# encoding: UTF-8
import re
# 將正則表示式編譯成Pattern物件
pattern = re.compile(r'hello')
# 使用Pattern匹配文字,獲得匹配結果,無法匹配時將返回None
match = pattern.match('hello world!')
if match:
# 使用Match獲得分組資訊
print match.group()
### 輸出 ###
# hello