
行為識別Action Detection概述及資源合集(持續更新...)
隨著深度學習技術的發展,以及計算能力的進步(GPU等),現在基於視訊的研究領域越來越受到重視。視訊與圖片最大的不同在於視訊還包含了時序上的資訊,此外需要的計算量通常也大很多。
這篇主要介紹Action Recognition(行為識別)這個方向。這個方向的主要目標是判斷一段視訊中人的行為的類別,所以也可以叫做Human Action Recognition。雖然這個問題是針對視訊中人的動作,但基於這個問題發展出來的演算法,大都不特定針對人,也可以用於其他型別視訊的分類。
背景介紹
什麼是動作識別?
動作識別的主要目標是判斷一段視訊中人的行為的類別,所以也可以叫做 Human Action Recognition。
動作識別的難點在哪裡?
(1)類內和類間差異, 同樣一個動作,不同人的表現可能有極大的差異。
(2)環境差異, 遮擋、多視角、光照、低解析度、動態背景.
(3)時間變化, 人在執行動作時的速度變化很大,很難確定動作的起始點,從而在對視訊提取特徵表示動作時影響最大。
(4)缺乏標註良好的大的資料集
有那些解決方法?
最好的傳統的方法? iDT
當前的深度學習的方法?
- RGB + 光流
- 3D卷積
- lstm + 單幀
- skeleton(資料集缺乏)
視訊中的人體行為識別主要包括兩個方向:Action Recognition 以及 Temporal Action Localization:
- Action Recognition的目的是給定一個視訊片段進行分類,類別通常是人的各類動作。特點是簡化了問題,一般使用的資料庫都先將動作分割好了,一個視訊片斷中包含一段明確的動作,時間較短(幾秒鐘)且有唯一確定的label。所以也可以看作是輸入為視訊,輸出為動作標籤的多分類問題。常用資料庫包括UCF101,HMDB51等。相當於對視訊進行分類。
- Temporal Action Localization 則不僅要知道一個動作在視訊中是否發生,還需要知道動作發生在視訊的哪段時間(包括開始和結束時間)。特點是需要處理較長的,未分割的視訊。且視訊通常有較多幹擾,目標動作一般只佔視訊的一小部分。常用資料庫包括HUMOS2014/2015, ActivityNet等。相當於對視訊進行指定行為的檢測。
- action recognition與temporal action detection之間的關係,同 image classfication與 object detection之間的關係非常像。基於image classification問題,發展出了許多強大的網路模型(比如ResNet,VGGNet等),這些模型在object detection的方法中起到了很大的作用。同樣,action recognition的相關模型(如two stream,C3D, iDT等)也被廣泛的用在temporal action detection的方法中。
資料集
The HMDB-51 dataset(2011)
Brown university 大學釋出的 HMDB51, 視訊多數來源於電影,還有一部分來自公共資料庫以及YouTube等網路視訊庫.資料庫包含有6849段樣本,分為51類,每類至少包含有101段樣本。
UCF-101(2012)
來源為YouTube視訊,共計101類動作,13320段視訊。共有5個大類的動作:
1)人-物互動;2)肢體運動;3)人-人互動;4)彈奏樂器;5)運動.
Sports1M 包含487類各項運動, 約110萬個視訊. 此外,Sports1M 的視訊長度平均超過 5 分鐘,而標籤預測的動作可能僅在整個視訊的很小一部分時間中發生。 Sports1M 的標註通過分析和 youtube視訊相關的文字元資料自動地生成,因此是不準確的。
Kinetics-600是一個大規模,高質量的YouTube視訊網址資料集,其中包括各種人的行動。
該資料集由大約50萬個視訊剪輯組成,涵蓋600個人類行為類,每個行為類至少有600個視訊剪輯。每個剪輯持續約10秒鐘,並標記一個類。所有剪輯都經過了多輪人工註釋,每個剪輯都來自單獨的YouTube視訊。這些行為涵蓋了廣泛的類別,包括人與物體的互動,如演奏樂器,以及人與人之間的互動,如握手和擁抱。
演算法
光流
光流是視覺領域的一個獨立分支
光流通常被表述為估計世界真實三維運動的二維投影的問題。
In spite of the fast computation time (0.06s for a pair of frames),
 

(a)(b) 視訊中的連續的兩幀, (c) 藍綠色框中的光流資訊, (d) 位移向量的水平資訊, (e) 位移向量的垂直資訊;
iDT
iDT(13年)(improved dense trajectories(軌跡))
iDT 方法(是深度學習進入該領域前效果最好,穩定性最好,可靠性最高的方法,不過演算法速度很慢(在於計算光流速度很慢)。
基本思路為利用光流場來獲得視訊序列中的一些軌跡,再沿著軌跡提取HOF,HOG,MBH,trajectory4種特徵,其中HOF基於灰度圖計算,另外幾個均基於dense optical flow(密集光流)計算。最後利用FV(Fisher Vector)方法對特徵進行編碼,再基於編碼結果訓練SVM分類器。
早期研究
2DCNN, 能不能自動的捕捉運動資訊?
- single frame
- stacked frames
雙流法
遷移學習
- 最後一層(或者最後L層)
- fine-tune 所有層(小學習率)
雙流架構:
- 空域網路(spatial networks)
- 時域網路(temporal networks)
理論支撐: 雙流體系結構與雙流假設相關,即人類視覺皮層包含兩條路徑, 如下
- 腹側流(ventral stream, 執行物體識別)
- 背側流(dorsal stream, 識別運動資訊)
將空時網路解耦的好處:
時域網路可以使用預訓練的 ImageNet 上預訓練的模型.

TSN: Temporal Segment Networks: Towards Good Practices for Deep Action Recognition(2016)
光流的作用
大多數表現優秀的動作識別演算法使用光流作為“黑匣子”輸入。 在這裡,我們更深入地考察光流與動作識別的結合,並研究為什麼光流有幫助, 光流演算法對動作識別有什麼好處,以及如何使其更好。
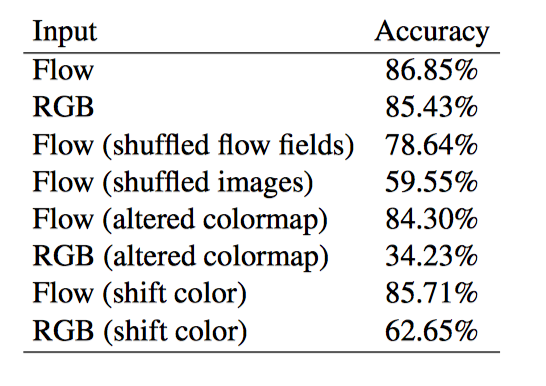
實驗結果表明: 當前體系結構中光流的大部分價值在於它對場景表示的表觀不變(invariant to appearance), 也表明運動軌跡不是光流成功的根源,並且建立有用的運動表示仍然是光流自身無法解決的一個懸而未決的問題。
由於光流是從影象序列計算出來的,所以有人可能會爭辯說,訓練有素的網路可以學習如何計算光流,如果光流是有用的,則不需要明確計算光流。
儘管使用顯式運動估計作為涉及視訊任務的輸入可能看起來很直觀,但人們可能會爭辯說使用運動並不是必需的。 一些可能的論點是,當前資料集中的類別可以從單幀中識別出來,並且可以從單幀中識別視覺世界中更廣泛的許多物件和動作.
C3D
3D 卷積
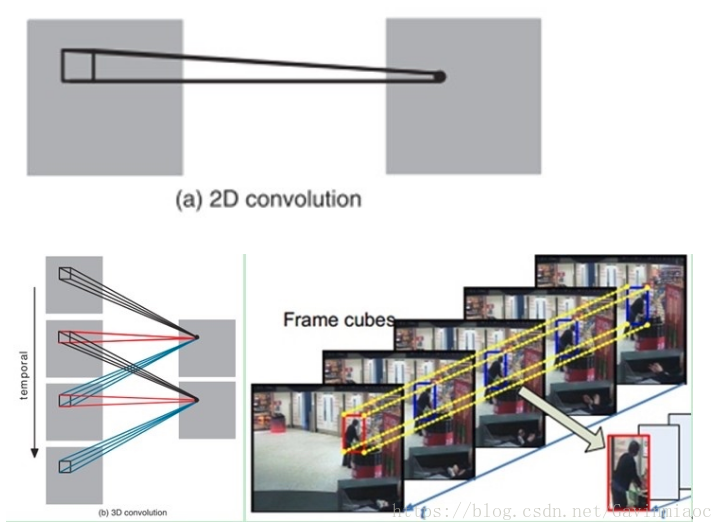
C3D能把 ImageNet 的成功(遷移學習)複製到視訊領域嗎?
 

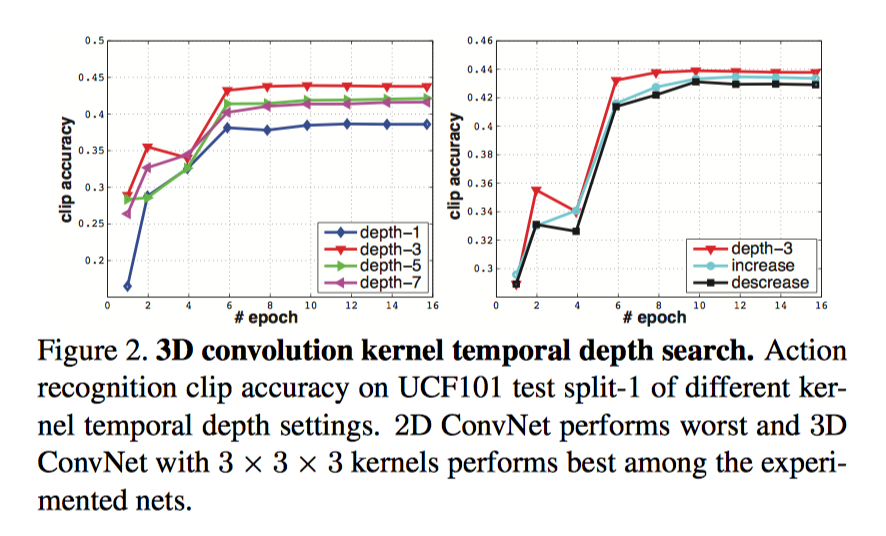 

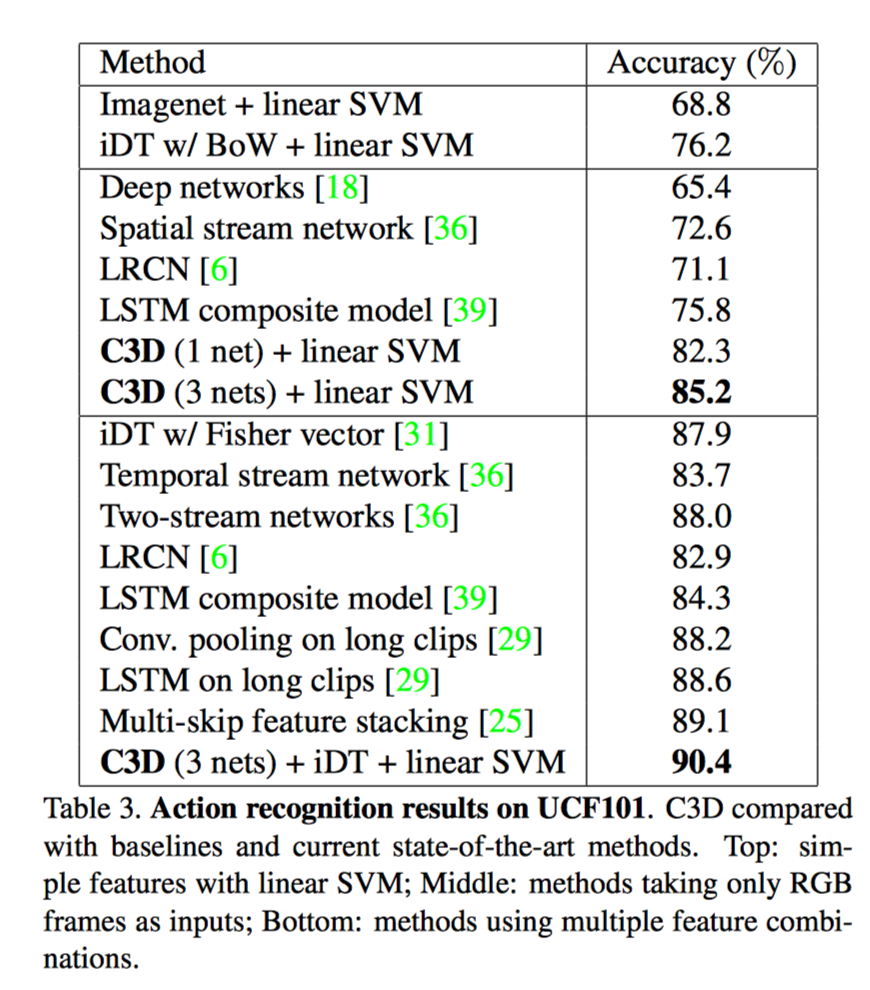 

速度
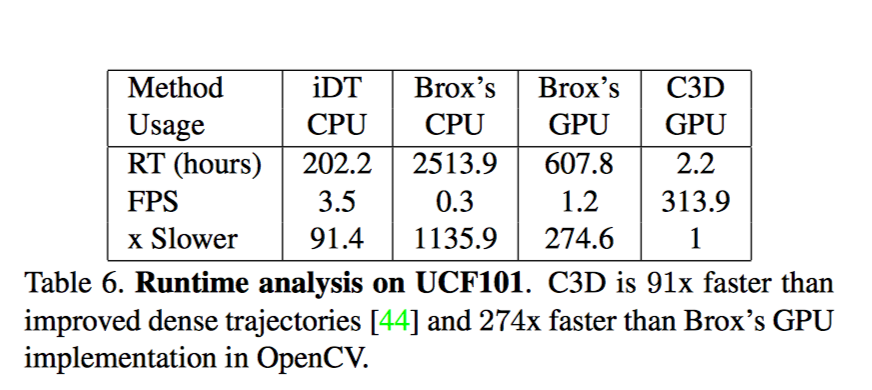 

iDT官方提供的計演算法方法沒有 GPU 版本
Brox一種計算光流的方法; 包括 I/O 時間, 平均一組圖片的光流計算時間為0.85-0.9s
---------------------------------------------我-----------是------------分------------割--------------線--------------------------------------------------------
==============================================================================================
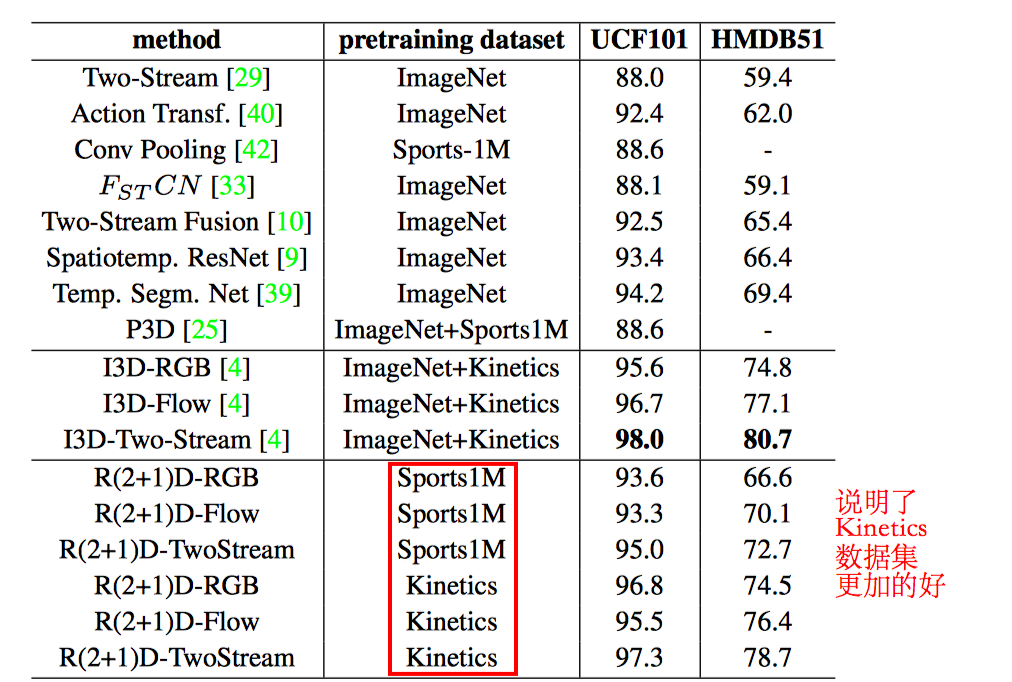
下圖為目前主流模型的比較。其中T3D標稱效果好於I3D,但由於結果是作者復現得來,故在這裡不做比較。順序自上向下按UCF101的準確率排列。
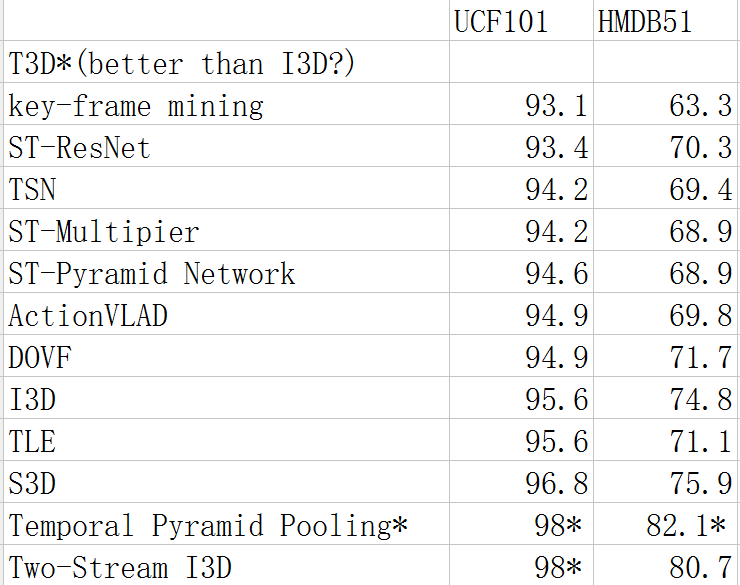
表中最後兩個見下面4,7
目前Action Recognition的研究方向(發論文的方向)分為三大類。
- Structure
- Inputs
- Connection
Structure
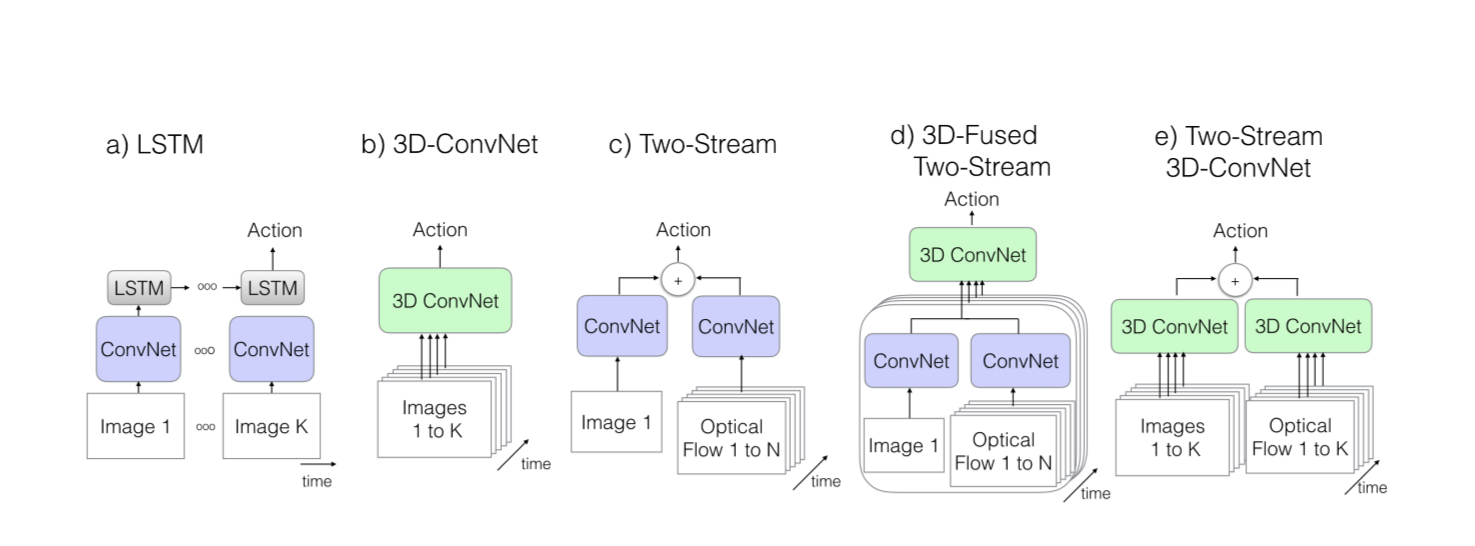
這裡的結構主要指網路結構。目前,主流的結構都是基於 Two-Stream Convolutional Networks和 C3D 發展而來,所以這一塊內容也主要討論這兩種結構的各種演化中作為benchmark的一些結構。
1.
首先討論TSN模型,這是港中文湯曉鷗組的論文,也是目前的benchmark之一,許多模型也是在TSN的基礎上進行了後續的探索。
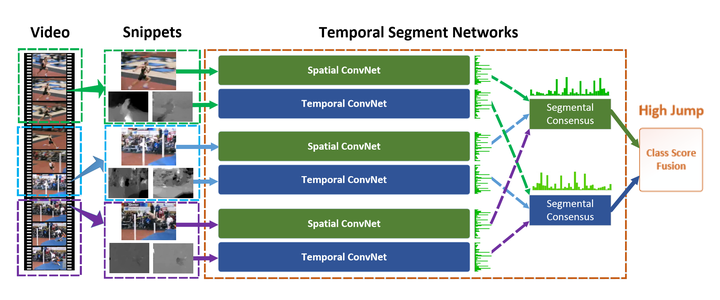
該論文繼承了雙流網路的結構,但為了解決long-term的問題,作者提出使用多個雙流網路,分別捕捉不同時序位置的short-term資訊,然後進行融合,得到最後結果。
2.
TSN改進版本之一。
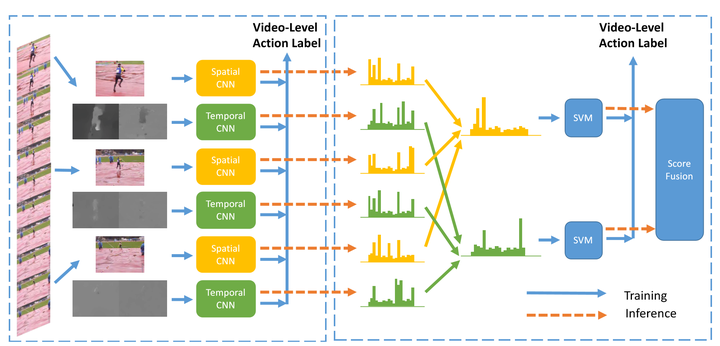
改進的地方主要在於fusion部分,不同的片段的應該有不同的權重,而這部分由網路學習而得,最後由SVM分類得到結果。
3.
TSN改進版本二。
這篇是MIT周博磊大神的論文,作者是也是最近提出的資料集 Moments in time 的作者之一。
該論文關注時序關係推理。對於哪些僅靠關鍵幀(單幀RGB影象)無法辨別的動作,如摔倒,其實可以通過時序推理進行分類。如下圖。

除了兩幀之間時序推理,還可以拓展到更多幀之間的時序推理
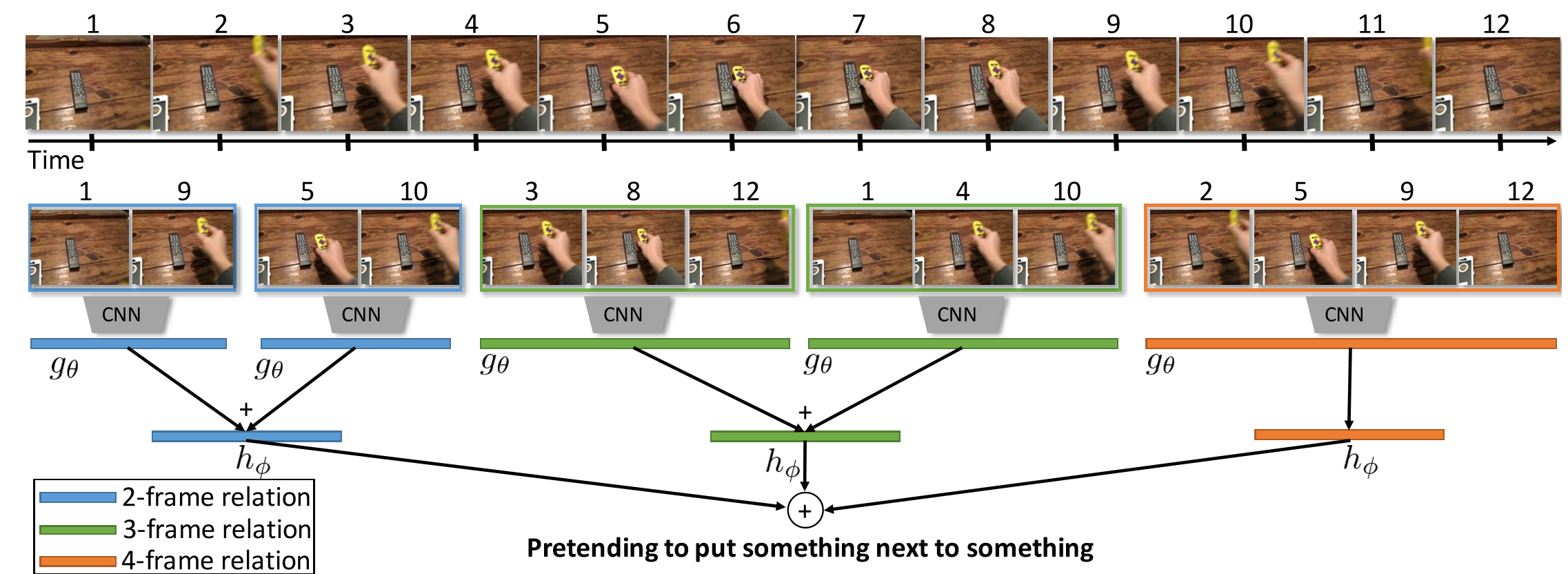
通過對不同長度視訊幀的時序推理,最後進行融合得到結果。
該模型建立TSN基礎上,在輸入的特徵圖上進行時序推理。增加三層全連線層學習不同長度視訊幀的權重,及上圖中的函式g和h。
除了上述模型外,還有更多關於時空資訊融合的結構。這部分與connection部分有重疊,所以僅在這一部分提及。這些模型結構相似,區別主要在於融合module的差異
4.Two-Stream I3D
動作在單個幀中可能不明確,然而, 現有動作識別資料集的侷限性意味著效能最佳的視訊架構不會明顯偏離單圖分析,因為他們依賴在ImageNet上訓練的強大影象分類器。
資料集: Kinetics
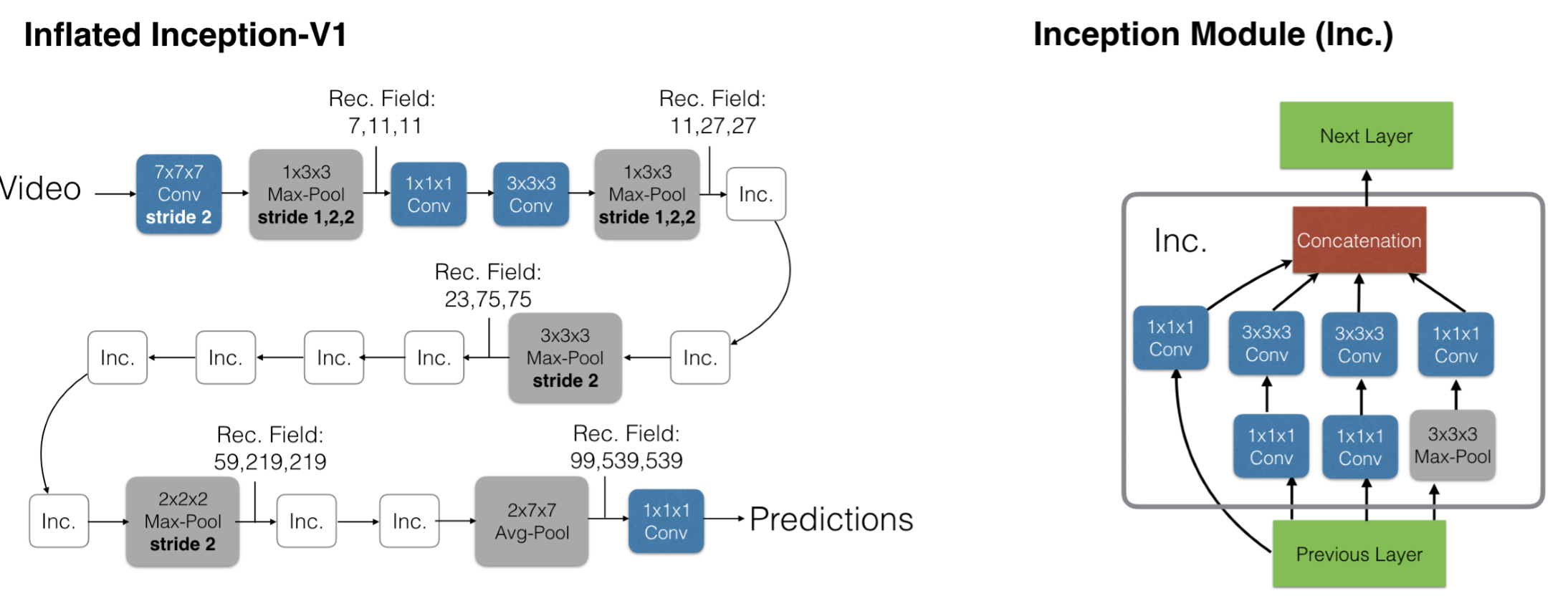
即基於inception-V1模型,將2D卷積擴充套件到3D卷積。
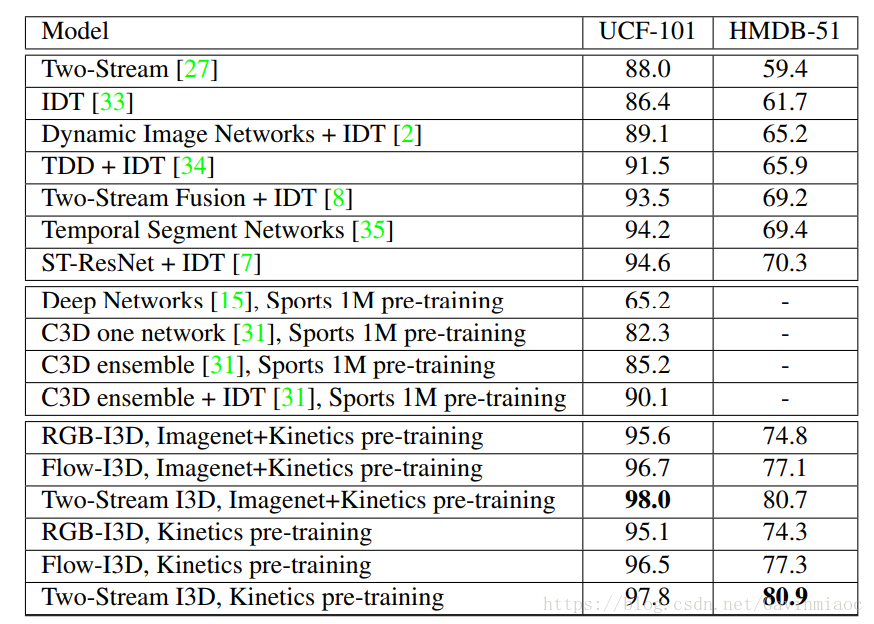
I3D 效能更好的原因:
一是 I3D的架構更好,
二是 Kinetic 資料集更具有普適性
5.
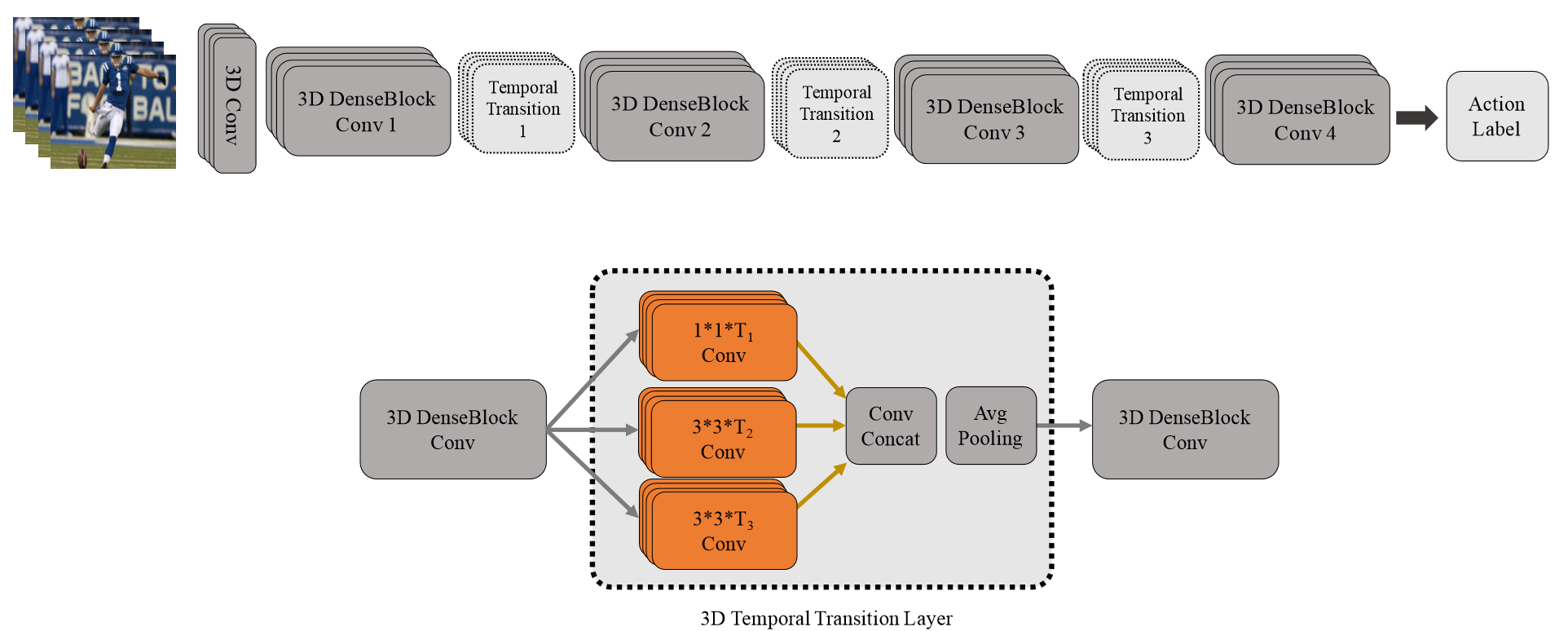
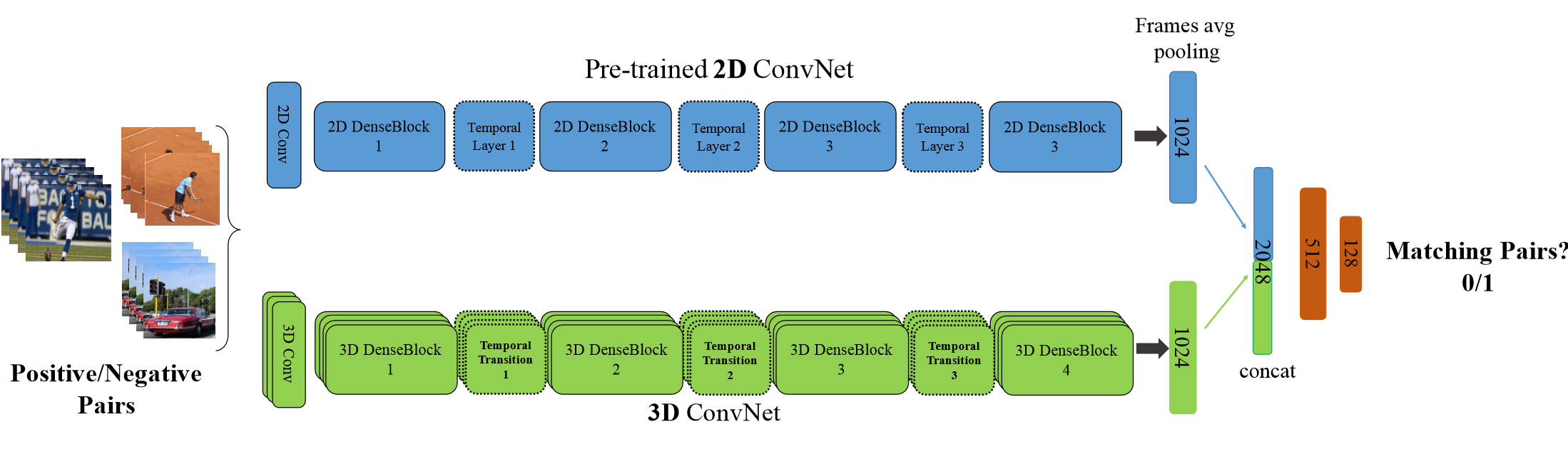
該論文值得注意的,一方面是採用了3D densenet,區別於之前的inception和Resnet結構;另一方面,TTL層,即使用不同尺度的卷積(inception思想)來捕捉訊息。
6.
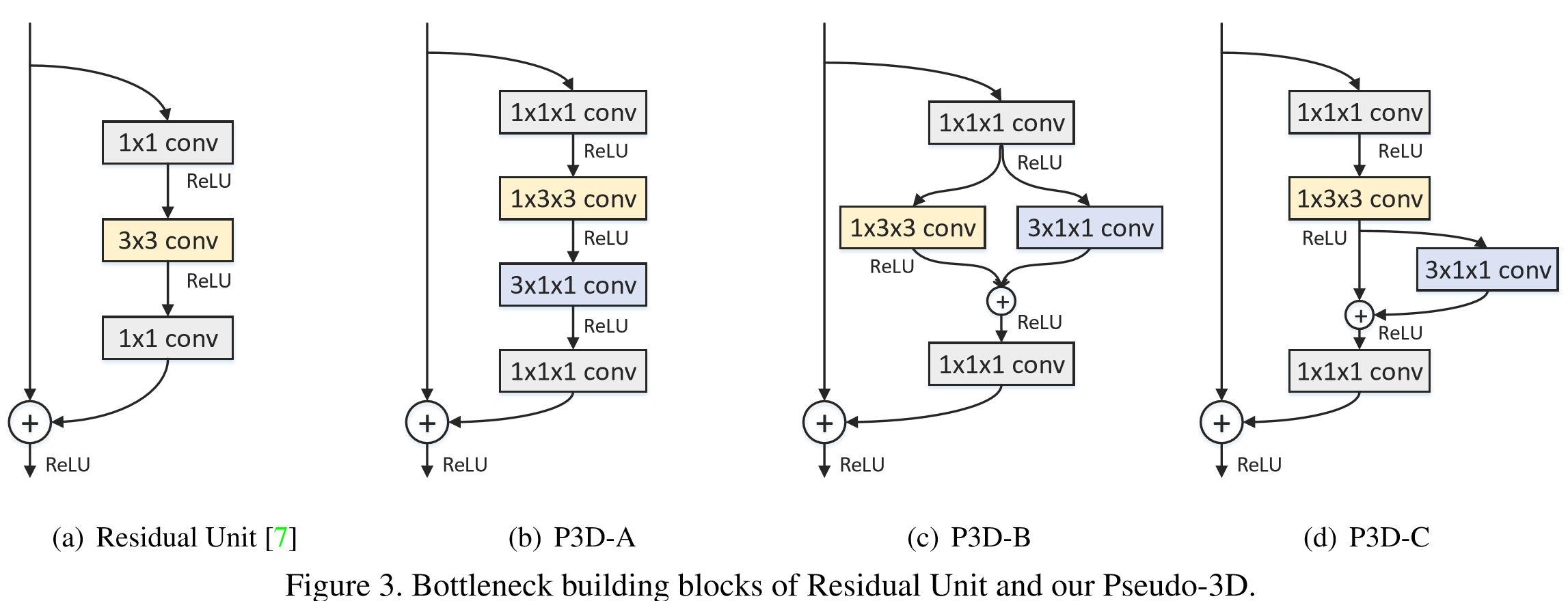
改進ResNet內部連線中的卷積形式。然後,超深網路,一般人顯然只能空有想法,望而卻步
7.
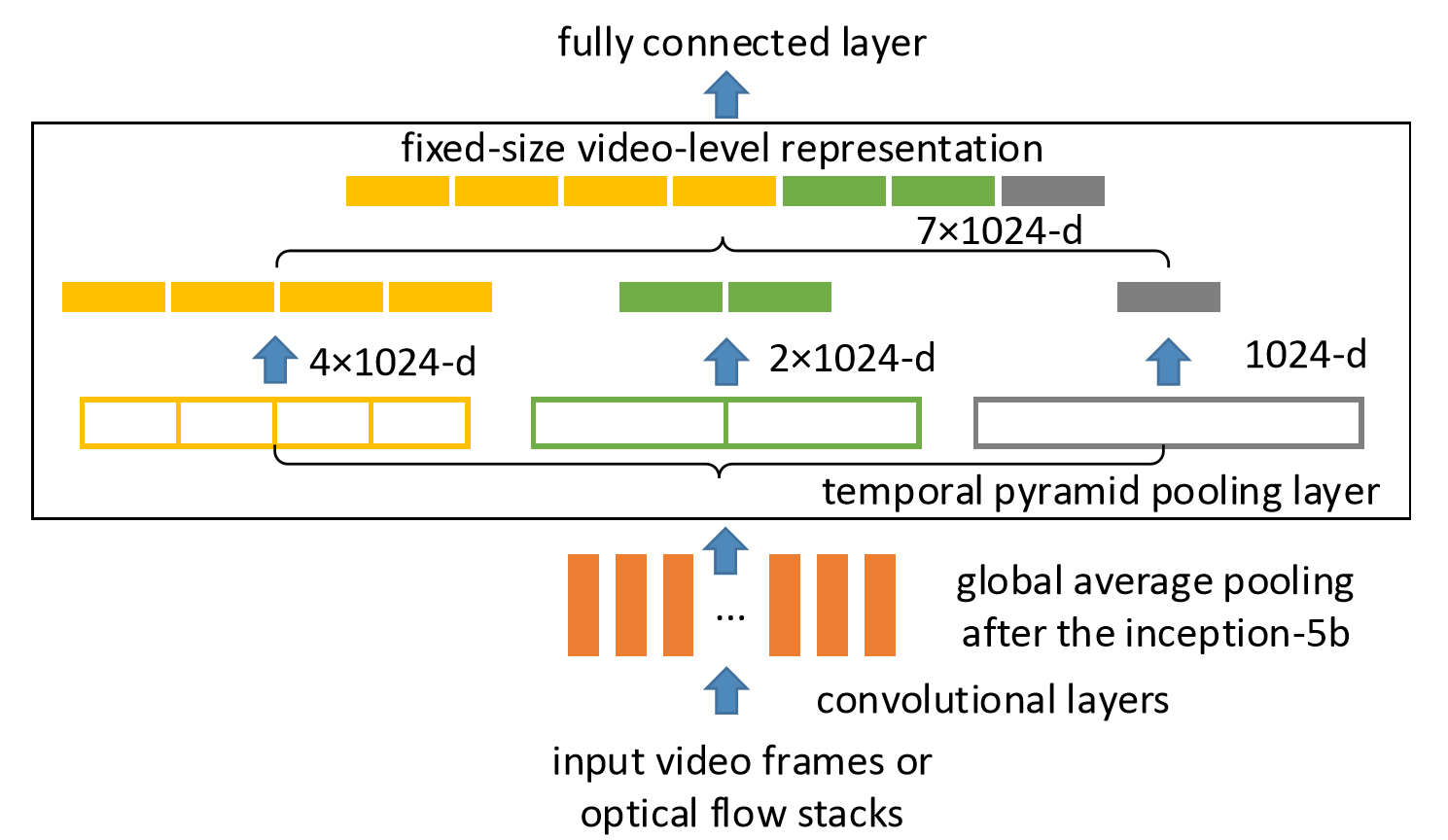
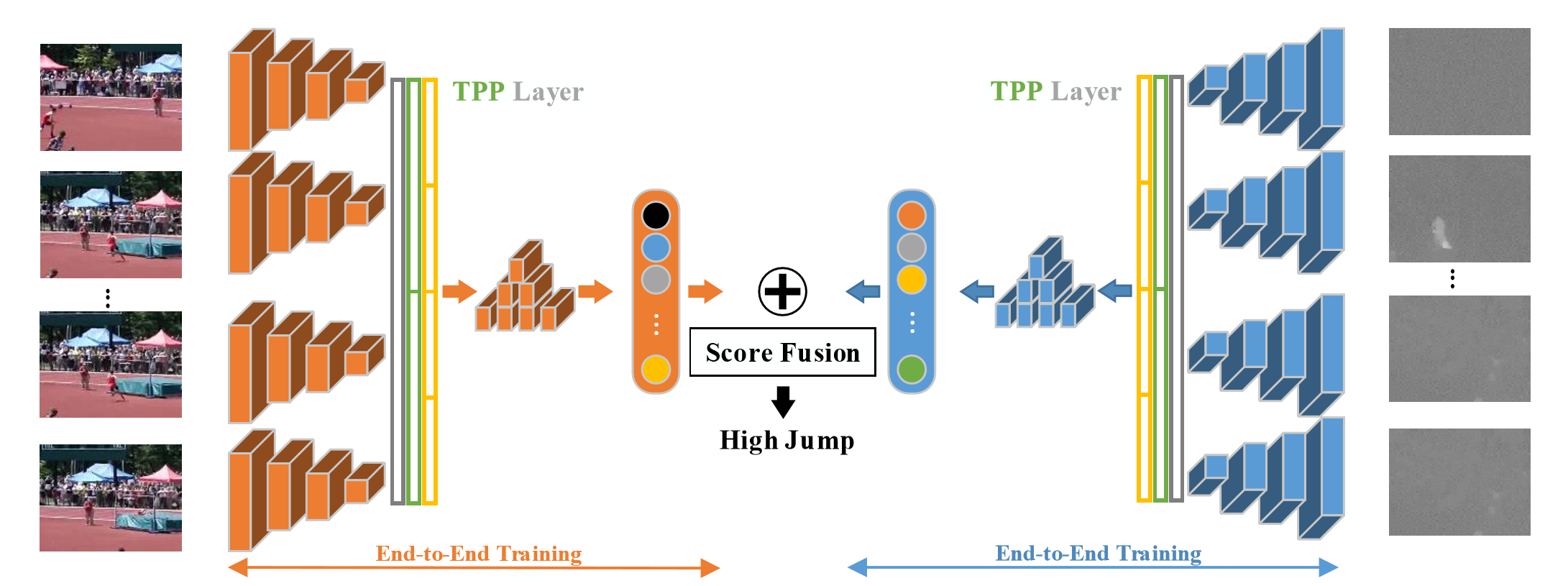
Pooling。時空上都進行這種pooling操作,旨在捕捉不同長度的訊息。
In this paper, we propose Deep networks with Temporal Pyramid Pooling (DTPP), an end-to-end video-level representation learning approach.
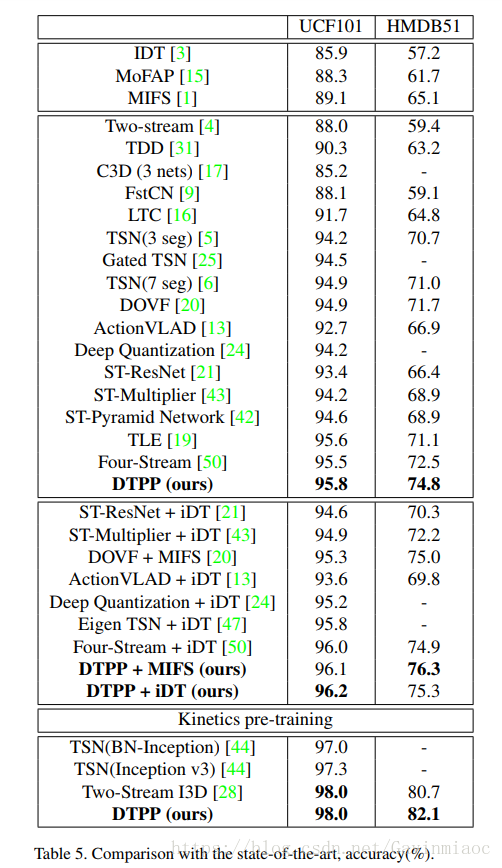
Finally, DTPP achieves the state-of-the-art performance on UCF101 and HMDB51, either by ImageNet pre-training or Kinetics pre-training.
8.TLE

TLE層的核心.
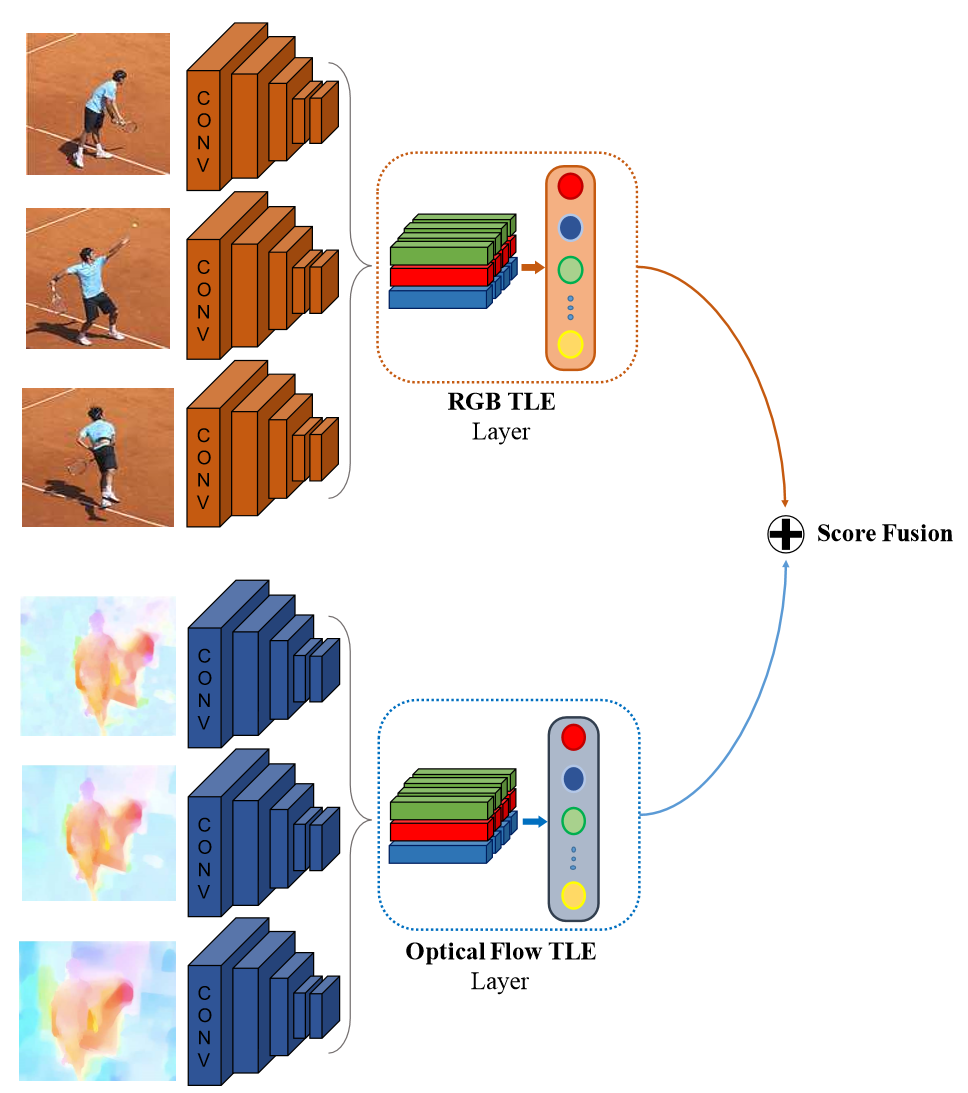
TLE層在雙流網路中的使用。
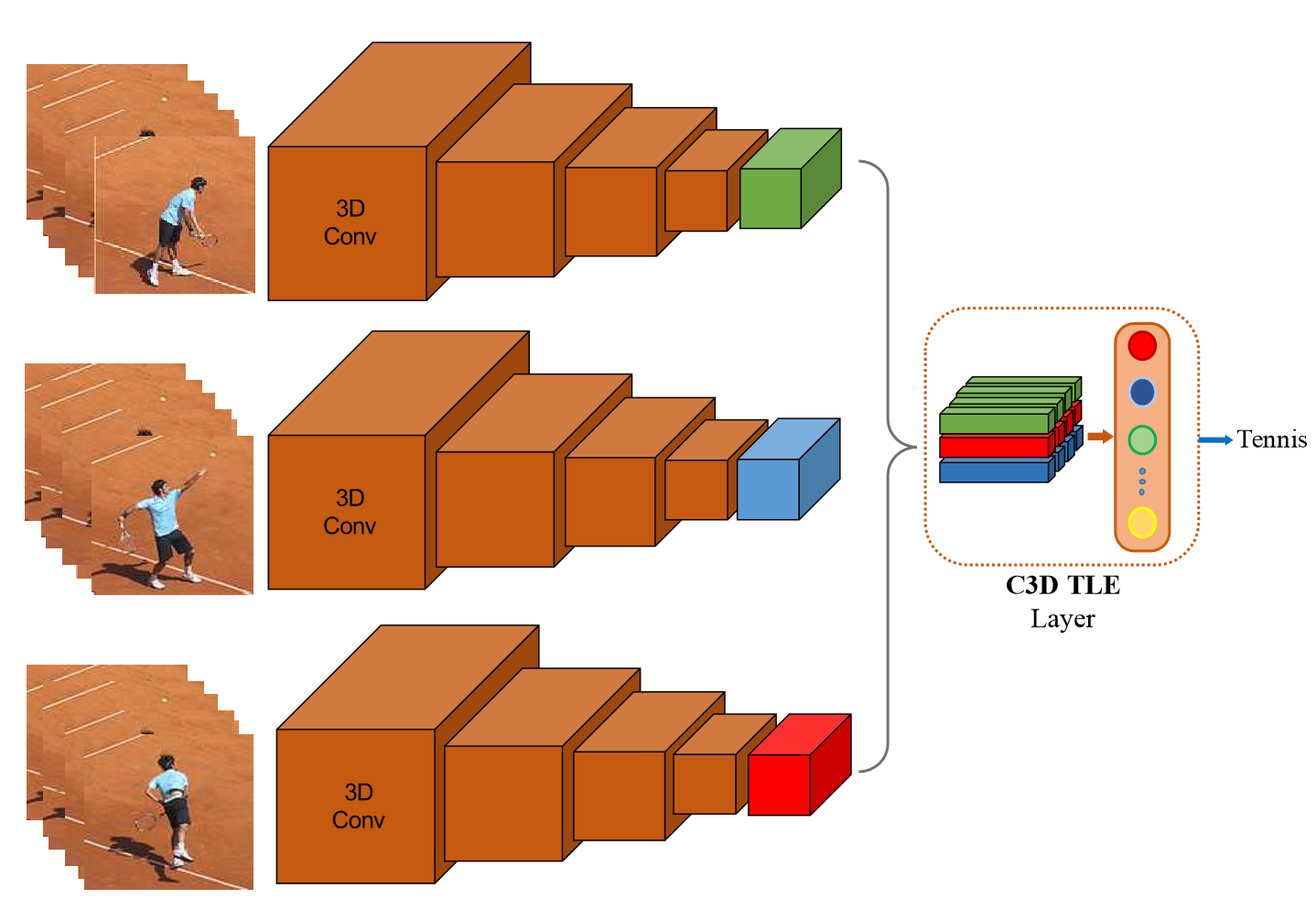
TLE層在C3D結構網路中的使用。
Connection
這裡連線主要是指雙流網路中時空資訊的互動。一種是單個網路內部各層之間的互動,如ResNet/Inception;一種是雙流網路之間的互動,包括不同fusion方式的探索,目前值得考慮的是參照ResNet的結構,連線雙流網路。
這裡主要討論雙流的互動。不同論文之間的互動方式各有不同。
9.
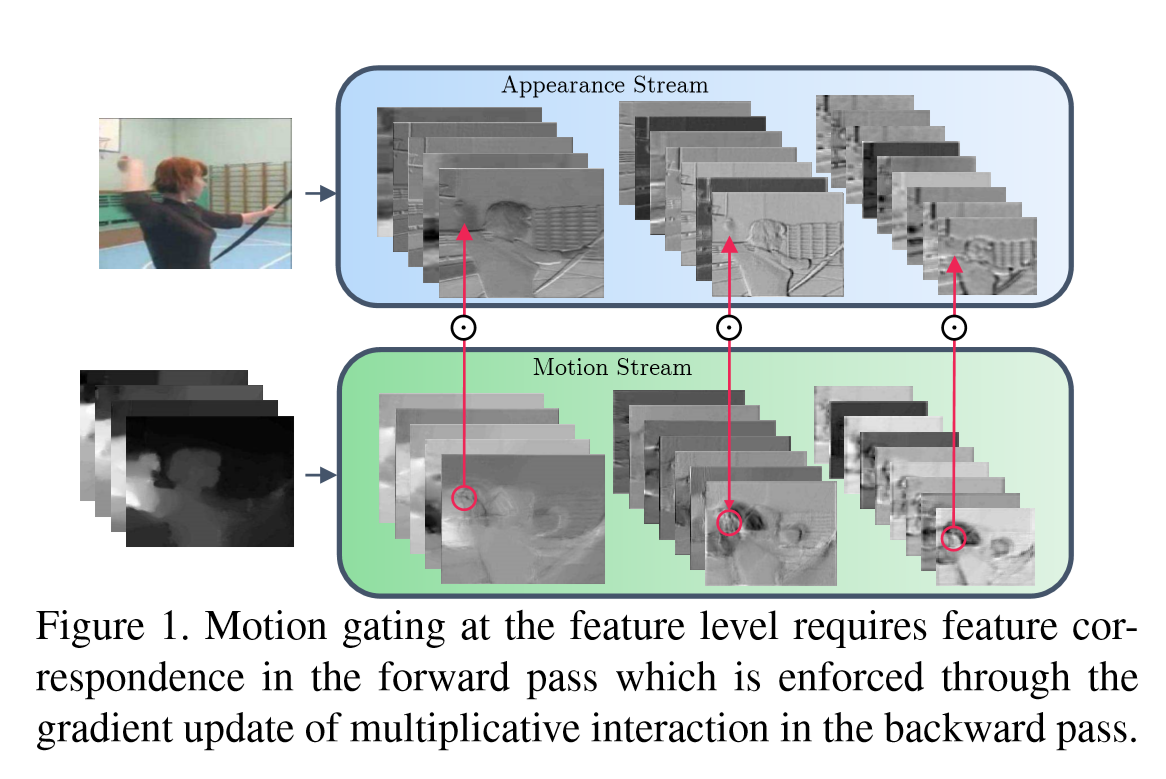
網路的結構如上圖。空間和時序網路的主體都是ResNet,增加了從Motion Stream到Spatial Stream的互動。論文還探索多種方式。
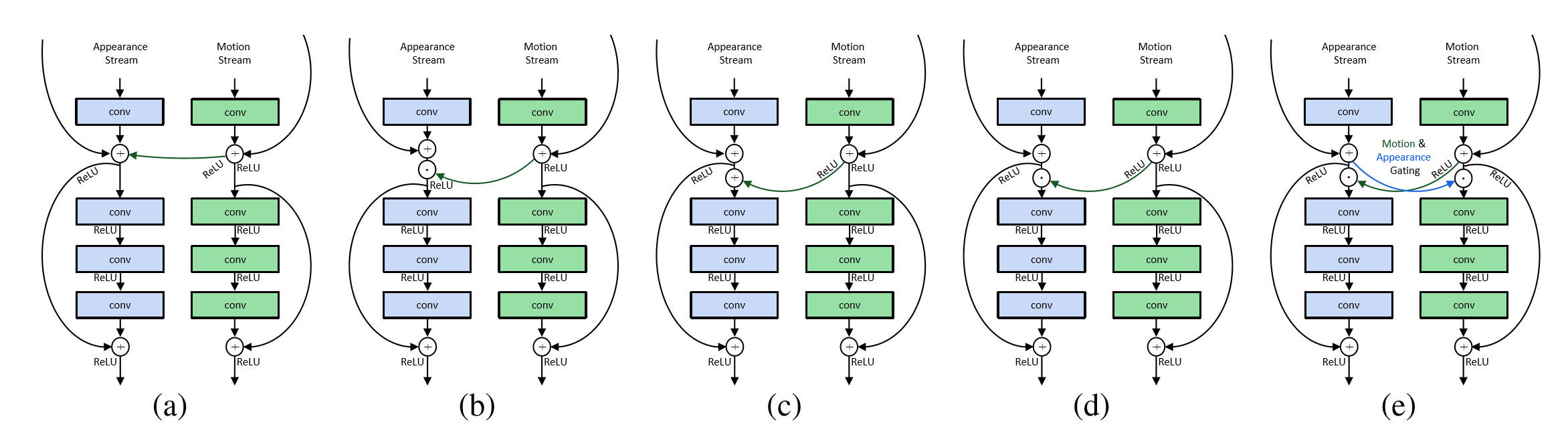
10.
論文作者認為,行為識別的關鍵就在於如何很好的融合空間和時序上的特徵。作者發現,傳統雙流網路雖然在最後有fusion的過程,但訓練中確實單獨訓練的,最終結果的失誤預測往往僅來源於某一網路,並且空間/時序網路各有所長。論文分析了錯誤分類的原因:空間網路在視訊背景相似度高的時候容易失誤,時序網路在long-term行為中因為snippets length的長度限制容易失誤。那麼能否通過互動,實現兩個網路的互補呢
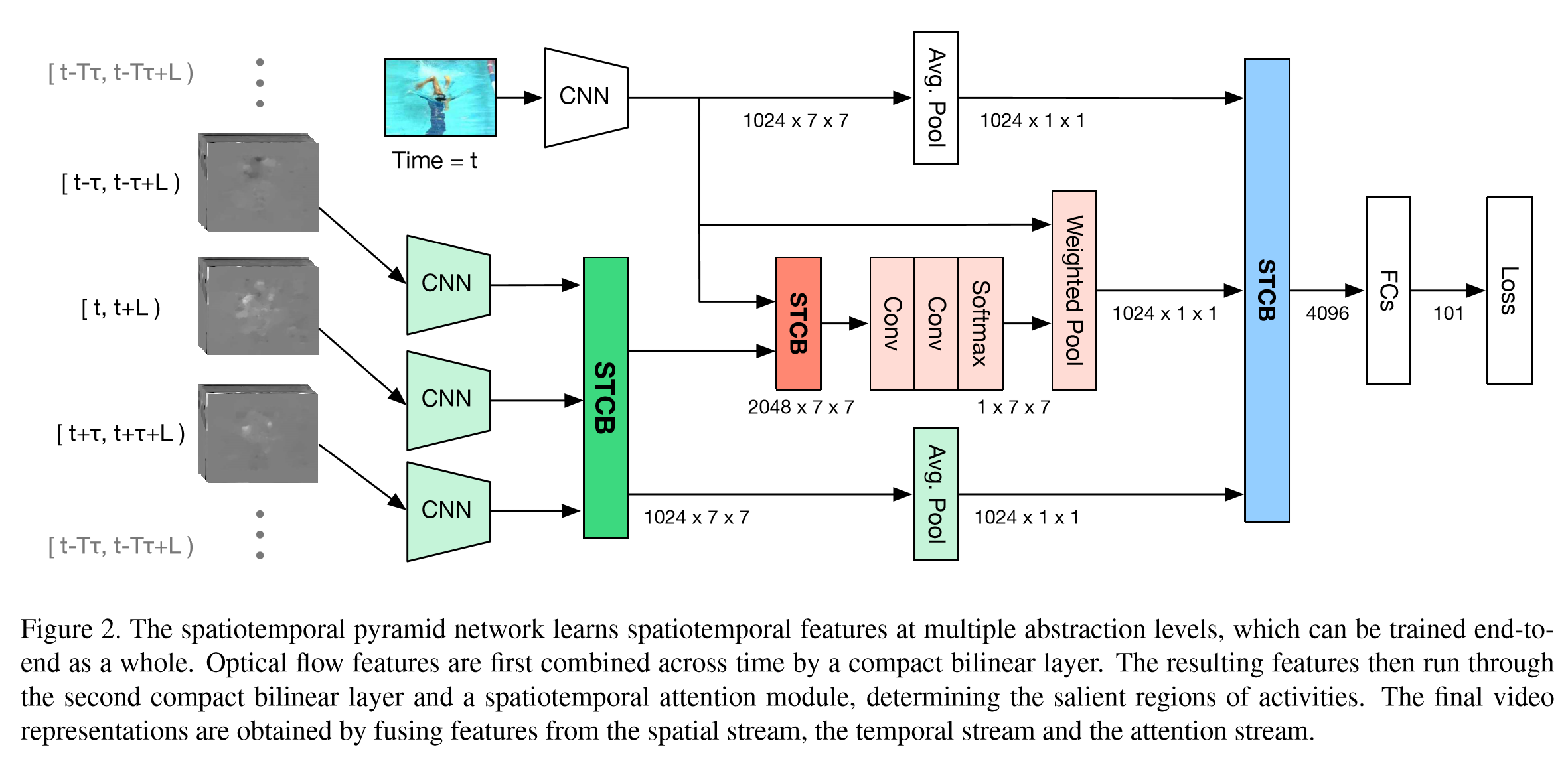
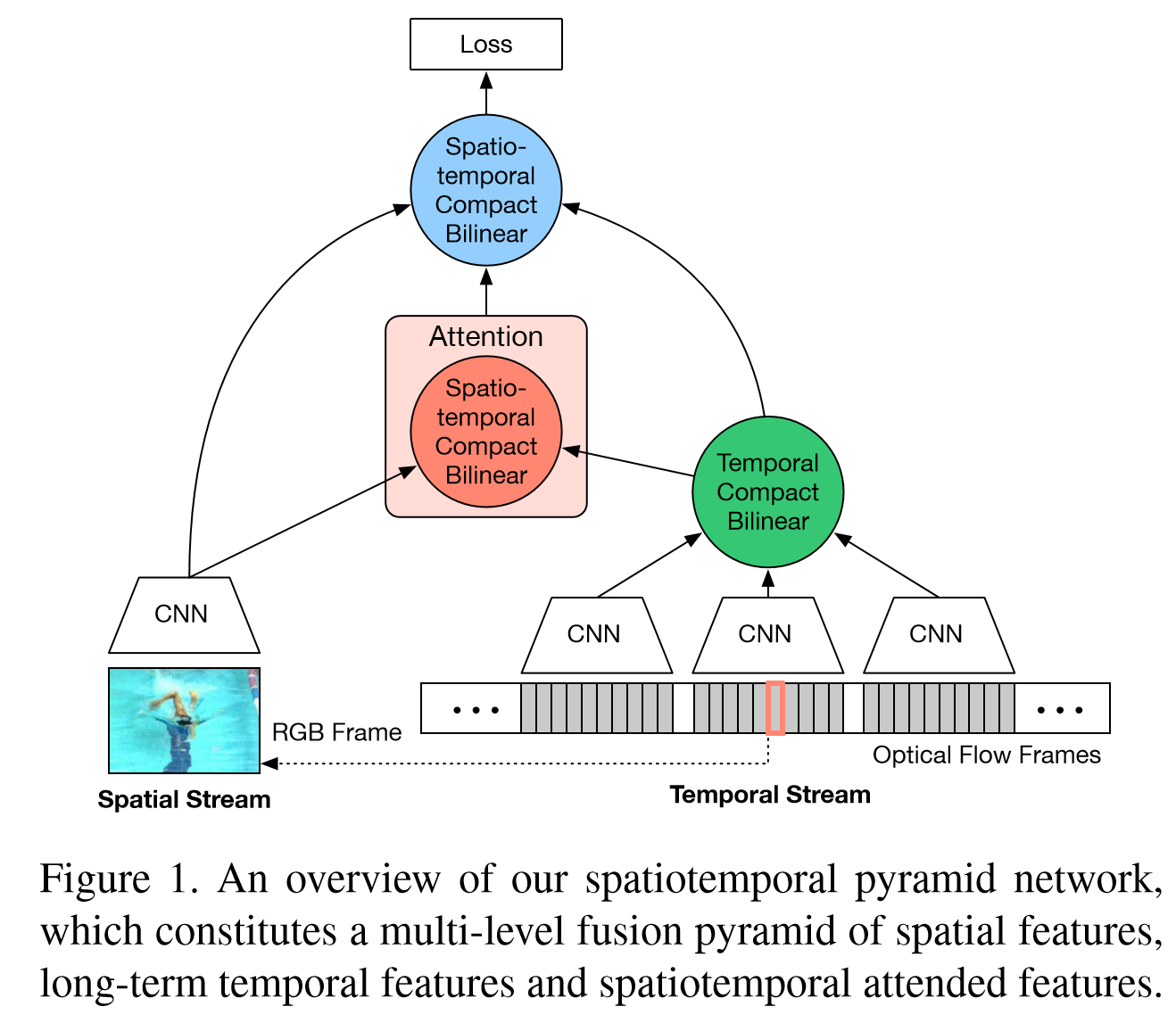
該論文重點在於STCB模組,詳情請參閱論文。互動方面,在保留空間、時序流的同時,對時空資訊進行了一次融合,最後三路融合,得出最後結果。
11.
12.
這兩篇論文從pooling的層面提高了雙流的互動能力,這兩篇筆者還在看,有興趣的讀者請自行參閱論文。後期會附上論文的解讀。
13.
這篇論文也是基於ResNet的結構探索新的雙流連線方式。
14.
通過特徵學習到特徵與特徵之間的關係,這樣類似於對全域性特徵做了attention,對於多幀的輸入,不管是2D還是3D卷積,都提供了更多幫助學習action的資訊。作者開源了程式碼,應該是目前的stateoftheart。
總結:
- 在motion特徵被理解之前,雙流網路可能仍然是主流。
- 時空資訊互動仍然有探索的餘地,個人看來也是最有可能發論文的重點領域。
- 輸入方面,替代光流的特徵值得期待。
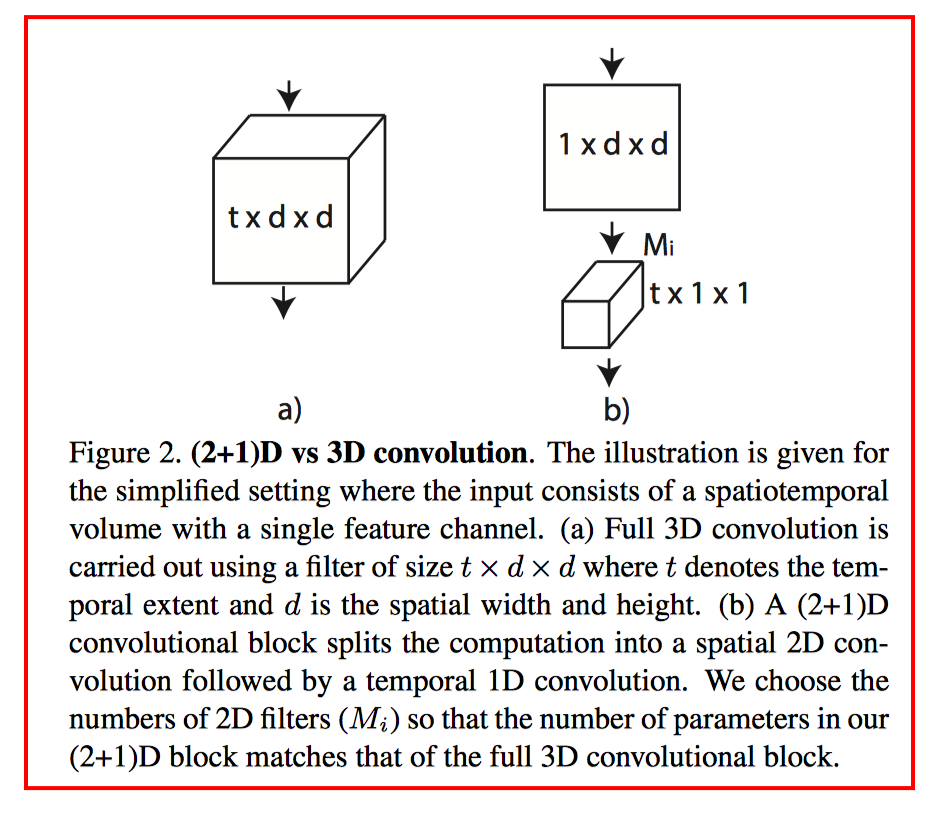
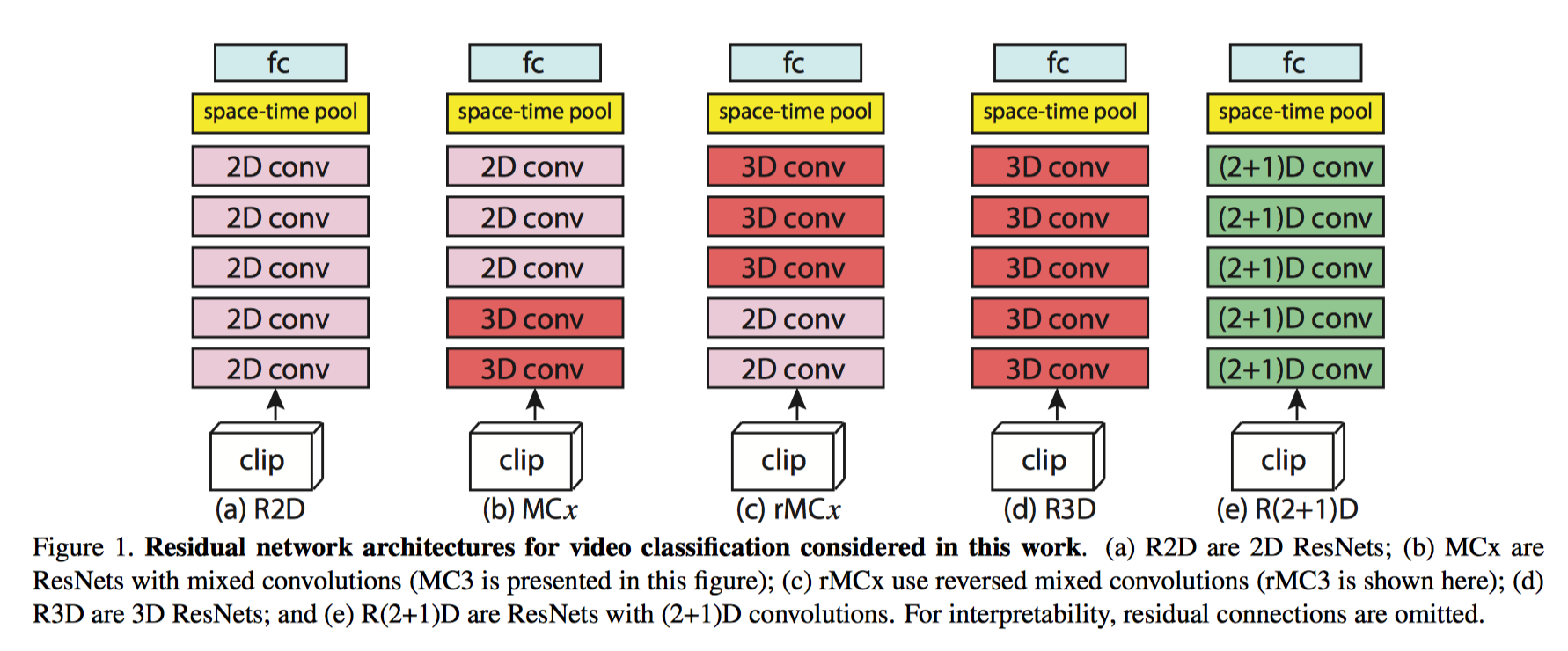
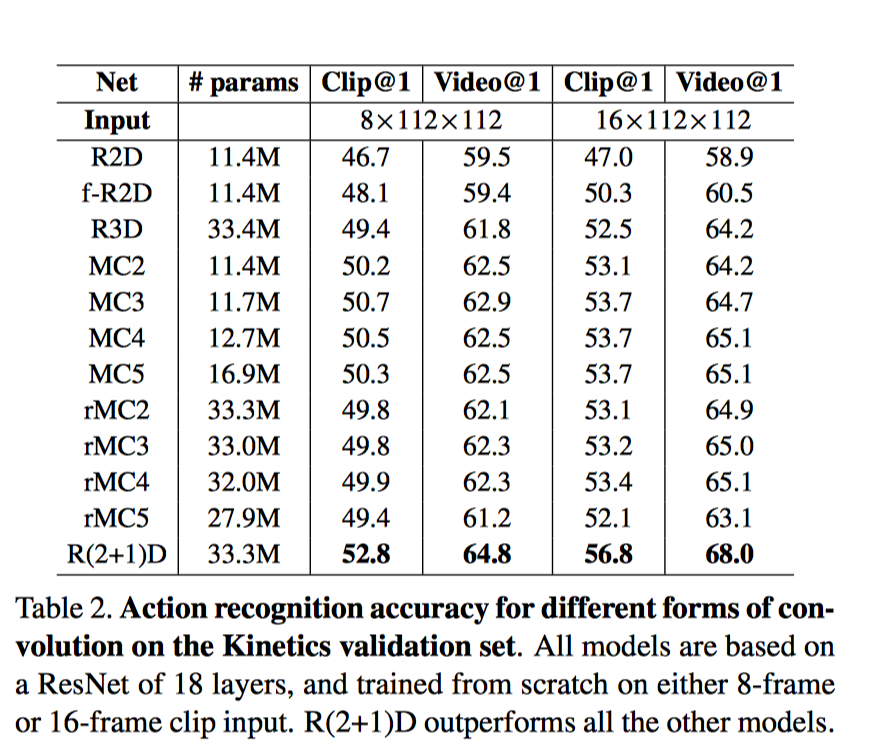
15.R(2+1)D
S3D?
P3D?
我們的研究動機源於觀察到這樣一個現象, 在動作識別中, 基於視訊的單幀的2D CNN在仍然是不錯的表現。
基於視訊單幀的 2D CNN(RESNET-152[1])的效能非常接近的Sport-1M基準上當前最好的演算法。這個結果是既令人驚訝和沮喪,因為2D CNN 無法建模時間和運動資訊。基於這樣的結果,我們可以假設,時間結構對的識別作用並不是至關重要,因為已經包含一個序列中的靜態畫面已經能夠包含強有力的行動資訊了。
研究目標: 我們表明,3D ResNets顯著優於為相同的深度2D ResNets, 從而說明時域資訊對於動作識別來說很重要.
[1]Learning spatio-temporal representation with pseudo-3d residual networks



下面列表為行為識別及相關領域(如目標識別,手勢估計)的資源
Action Recognition
Spatio-Temporal Action Detection
Temporal Action Detection
Spatio-Temporal ConvNets
Action Classification
在行為識別領域,比較主流的演算法有two-streams,3D convolutions 和RNN,尤其以two-streams演算法
效能良好。Action Recognition Datasets
附錄:
論文列表(順序不分先後):
Structure:
Inputs:
Connection:
當前這個領域需要考慮的問題?
專注於動作, 還是場景理解
一個視訊中多個動作同時進行
嚴重依賴物體和場景首先無論是雙流法還是3D卷積核,網路到底學到了什麼?
會不會只是物體或場景的特徵呢?而動作識別,重點在於action。MIT最近公佈了新的資料集 Moments in time,Moments in Time,在這個資料集裡,action成為關鍵。例如,opening這個動作,可以是小孩雙眼open,也可以是門open,還可以是鳥的翅膀open。這樣的資料集對當前主流的演算法提出了挑戰,把video這塊的注意力聚焦在action,而不是物體和場景。
一些演算法實現
參考連結:
在此鳴謝!!如有商業侵權,請聯絡我刪除,謝謝!