
Bag-of-words模型入門介紹文章
- 引言
上述這4篇文章對SIFT演算法的原理和C語言實現都做了詳細介紹,用SIFT做影象匹配效果不錯。現在考慮更為高層的應用,將SIFT演算法應用於目標識別:發現影象中包含的物體類別,這是計算機視覺領域最基本也是最重要的任務之一。
且原經典演算法研究系列可能將改名為演算法珠璣--經典演算法的通俗演義。改名考慮到三點:1、不求面面俱到所有演算法,所以掏煉,謂之“珠璣”;2、突出本部落格內演算法內容的特色-通俗易懂、簡明直白,謂之“通俗”;3、側重經典演算法的研究與實現,以及實際應用,謂之“演義”。
OK,閒話少說,上一篇我們介紹了六(續)、從KMP演算法一步一步談到BM演算法。下面我們來介紹有關SIFT演算法的目標識別的應用--Bag-of-words模型。
- Bag-of-words模型簡介
Bag-of-words模型是資訊檢索領域常用的文件表示方法。在資訊檢索中,BOW模型假定對於一個文件,忽略它的單詞順序和語法、句法等要素,將其僅僅看作是若干個詞彙的集合,文件中每個單詞的出現都是獨立的,不依賴於其它單詞是否出現。也就是說,文件中任意一個位置出現的任何單詞,都不受該文件語意影響而獨立選擇的。例如有如下兩個文件:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基於這兩個文字文件,構造一個詞典:
這個詞典一共包含10個不同的單詞,利用詞典的索引號,上面兩個文件每一個都可以用一個10維向量表示(用整數數字0~n(n為正整數)表示某個單詞在文件中出現的次數):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每個元素表示詞典中相關元素在文件中出現的次數(下文中,將用單詞的直方圖表示)。不過,在構造文件向量的過程中可以看到,我們並沒有表達單詞在原來句子中出現的次序(這是本Bag-of-words模型的缺點之一,不過瑕不掩瑜甚至在此處無關緊要)。
- Bag-of-words模型的應用
Bag-of-words模型的適用場合
現在想象在一個巨大的文件集合D,裡面一共有M個文件,而文件裡面的所有單詞提取出來後,一起構成一個包含N個單詞的詞典,利用Bag-of-words模型,每個文件都可以被表示成為一個N維向量,計算機非常擅長於處理數值向量。這樣,就可以利用計算機來完成海量文件的分類過程。
考慮將Bag-of-words模型應用於影象表示。為了表示一幅影象,我們可以將影象看作文件,即若干個“視覺詞彙”的集合,同樣的,視覺詞彙相互之間沒有順序。
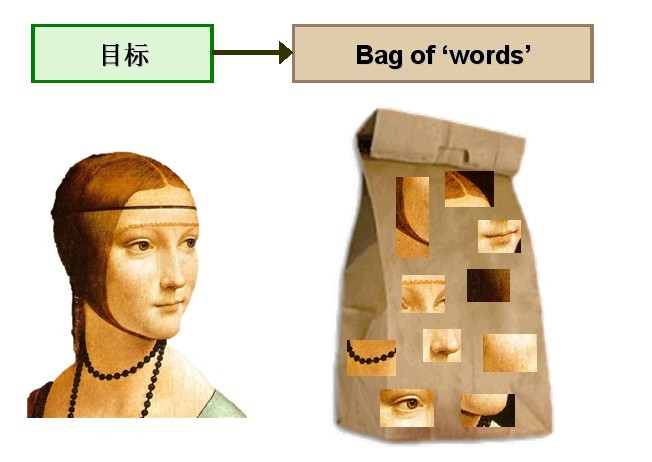
由於影象中的詞彙不像文字文件中的那樣是現成的,我們需要首先從影象中提取出相互獨立的視覺詞彙,這通常需要經過三個步驟:(1)特徵檢測,(2)特徵表示,(3)單詞本的生成,請看下圖2:
圖2 從影象中提取出相互獨立的視覺詞彙
通過觀察會發現,同一類目標的不同例項之間雖然存在差異,但我們仍然可以找到它們之間的一些共同的地方,比如說人臉,雖然說不同人的臉差別比較大,但眼睛,嘴,鼻子等一些比較細小的部位,卻觀察不到太大差別,我們可以把這些不同例項之間共同的部位提取出來,作為識別這一類目標的視覺詞彙。
而SIFT演算法是提取影象中區域性不變特徵的應用最廣泛的演算法,因此我們可以用SIFT演算法從影象中提取不變特徵點,作為視覺詞彙,並構造單詞表,用單詞表中的單詞表示一幅影象。
Bag-of-words模型應用三步
接下來,我們通過上述影象展示如何通過Bag-of-words模型,將影象表示成數值向量。現在有三個目標類,分別是人臉、自行車和吉他。
Bag-of-words模型的第一步是利用SIFT演算法,從每類影象中提取視覺詞彙,將所有的視覺詞彙集合在一起,如下圖3所示:

圖3 從每類影象中提取視覺詞彙
第二步是利用K-Means演算法構造單詞表。K-Means演算法是一種基於樣本間相似性度量的間接聚類方法,此演算法以K為引數,把N個物件分為K個簇,以使簇內具有較高的相似度,而簇間相似度較低。SIFT提取的視覺詞彙向量之間根據距離的遠近,可以利用K-Means演算法將詞義相近的詞彙合併,作為單詞表中的基礎詞彙,假定我們將K設為4,那麼單詞表的構造過程如下圖4所示:
圖4 利用K-Means演算法構造單詞表
第三步是利用單詞表的中詞彙表示影象。利用SIFT演算法,可以從每幅影象中提取很多個特徵點,這些特徵點都可以用單詞表中的單詞近似代替,通過統計單詞表中每個單詞在影象中出現的次數,可以將影象表示成為一個K=4維數值向量。請看下圖5: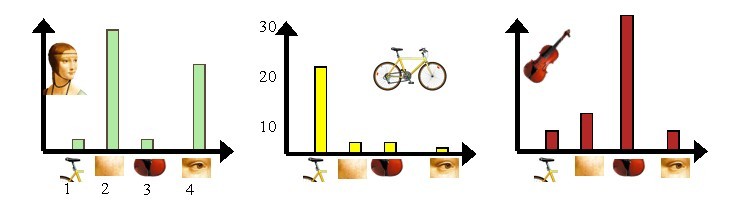
圖5 每幅影象的直方圖表示
上圖5中,我們從人臉、自行車和吉他三個目標類影象中提取出的不同視覺詞彙,而構造的詞彙表中,會把詞義相近的視覺詞彙合併為同一類,經過合併,詞彙表中只包含了四個視覺單詞,分別按索引值標記為1,2,3,4。通過觀察可以看到,它們分別屬於自行車、人臉、吉他、人臉類。統計這些詞彙在不同目標類中出現的次數可以得到每幅影象的直方圖表示(我們假定存在誤差,實際情況亦不外如此):
人臉:[3,30,3,20]
自行車:[20,3,3,2]
吉他: [8,12,32,7]
其實這個過程非常簡單,就是針對人臉、自行車和吉他這三個文件,抽取出相似的部分(或者詞義相近的視覺詞彙合併為同一類),構造一個詞典,詞典中包含4個視覺單詞,即Dictionary = {1:”自行車”, 2. “人臉”, 3. “吉他”, 4. “人臉類”},最終人臉、自行車和吉他這三個文件皆可以用一個4維向量表示,最後根據三個文件相應部分出現的次數畫成了上面對應的直方圖。
需要說明的是,以上過程只是針對三個目標類非常簡單的一個示例,實際應用中,為了達到較好的效果,單詞表中的詞彙數量K往往非常龐大,並且目標類數目越多,對應的K值也越大,一般情況下,K的取值在幾百到上千,在這裡取K=4僅僅是為了方便說明。
下面,我們再來總結一下如何利用Bag-of-words模型將一幅影象表示成為數值向量:
- 第一步:利用SIFT演算法從不同類別的影象中提取視覺詞彙向量,這些向量代表的是影象中區域性不變的特徵點;
- 第二步:將所有特徵點向量集合到一塊,利用K-Means演算法合併詞義相近的視覺詞彙,構造一個包含K個詞彙的單詞表;
- 第三步:統計單詞表中每個單詞在影象中出現的次數,從而將影象表示成為一個K維數值向量。
下面我們按照以上步驟,用C++一步步實現上述過程。
- C++逐步實現:Bag-of-words模型表示一幅影象
在具體編碼之前,我們需要事先搭配開發環境。
一. 搭建開發環境
使用的開發平臺是windows xp sp3 + vs2010(windows xp sp3 + vc6.0的情況,請參考此文:九(續)、sift演算法的編譯與實現)
2. 由於sift-latest_win.zip 要求的OpenCV版本是2.0以上,也下載最新版本 OpenCV-2.2.0-win32-vs2010.exe,執行安裝程式將opencv安裝在本地某路徑下。例如,我安裝在D盤根目錄下。
3. 執行vs2010,建立一個空的控制檯應用程式,取名bow。
4. 配置opencv環境。在vs2010下選擇project選單下的bow property子選單,調出bow property pages對話方塊,需要配置的地方有三處:在vc++ Directory選項裡需要配置Include Directories和Library Directories,在Linker選項卡的Input選項裡需要配置Additional Dependencies。

二.建立c++類CSIFTDiscriptor
為了方便使用,我們將SIFT庫用C++類CSIFTDiscriptor封裝,該類可以計算並獲取指定影象的特徵點向量集合。類的聲名在SIFTDiscriptor.h檔案中,內容如下:
#ifndef _SIFT_DISCRIPTOR_H_
#define _SIFT_DISCRIPTOR_H_
#include <string>
#include <highgui.h>
#include <cv.h>
extern "C"
{
#include "../sift/sift.h"
#include "../sift/imgfeatures.h"
#include "../sift/utils.h"
};
class CSIFTDiscriptor
{
public:
int GetInterestPointNumber()
{
return m_nInterestPointNumber;
}
struct feature *GetFeatureArray()
{
return m_pFeatureArray;
}
public :
void SetImgName(const std::string &strImgName)
{
m_strInputImgName = strImgName;
}
int CalculateSIFT();
public:
CSIFTDiscriptor(const std::string &strImgName);
CSIFTDiscriptor()
{
m_nInterestPointNumber = 0;
m_pFeatureArray = NULL;
}
~CSIFTDiscriptor();
private:
std::string m_strInputImgName;
int m_nInterestPointNumber;
feature *m_pFeatureArray;
};
#endif 成員函式實現在SIFTDiscriptor.cpp檔案中,其中,CalculateSIFT函式完成特徵點的提取和計算,其主要內部流程如下:
1) 呼叫OpenCV函式cvLoadImage載入輸入影象;
2) 為了統一輸入影象的尺寸,CalculateSIFT函式的第二步是調整輸入影象的尺寸,這通過呼叫cvResize函式實現;
3) 如果輸入影象是彩色影象,我們需要首先將其轉化成灰度圖,這通過呼叫cvCvtColor函式實現;
4) 呼叫SIFT庫函式sift_feature獲取輸入影象的特徵點向量集合和特徵點個數。
#include "SIFTDiscriptor.h"
int CSIFTDiscriptor::CalculateSIFT()
{
IplImage *pInputImg = cvLoadImage(m_strInputImgName.c_str());
if (!pInputImg)
{
return -1;
}
int nImgWidth = 320; //訓練用標準影象大小
double dbScaleFactor = pInputImg->width / 300.0; //縮放因子
IplImage *pTmpImg = cvCreateImage(cvSize(pInputImg->width / dbScaleFactor, pInputImg->height / dbScaleFactor),
pInputImg->depth, pInputImg->nChannels);
cvResize(pInputImg, pTmpImg); //縮放
cvReleaseImage(&pInputImg);
if (pTmpImg->nChannels != 1) //非灰度圖
{
IplImage *pGrayImg = cvCreateImage(cvSize(pTmpImg->width, pTmpImg->height),
pTmpImg->depth, 1);
cvCvtColor(pTmpImg, pGrayImg, CV_RGB2GRAY);
m_nInterestPointNumber = sift_features(pGrayImg, &m_pFeatureArray);
cvReleaseImage(&pGrayImg);
}
else
{
m_nInterestPointNumber = sift_features(pTmpImg, &m_pFeatureArray);
}
cvReleaseImage(&pTmpImg);
return m_nInterestPointNumber;
}
CSIFTDiscriptor::CSIFTDiscriptor(const std::string &strImgName)
{
m_strInputImgName = strImgName;
m_nInterestPointNumber = 0;
m_pFeatureArray = NULL;
CalculateSIFT();
}
CSIFTDiscriptor::~CSIFTDiscriptor()
{
if (m_pFeatureArray)
{
free(m_pFeatureArray);
}
} 三.建立c++類CImgSet,管理實驗影象集合
Bag-of-words模型需要從多個目標類影象中提取視覺詞彙,不同目標類的影象儲存在不同子資料夾中,為了方便操作,我們設計了一個專門的類CImgSet用來管理影象集合,宣告在檔案ImgSet.h中:
#ifndef _IMG_SET_H_
#define _IMG_SET_H_
#include <vector>
#include <string>
#pragma comment(lib, "shlwapi.lib")
class CImgSet
{
public:
CImgSet (const std::string &strImgDirName) : m_strImgDirName(strImgDirName+"//"), m_nImgNumber(0){}
int GetTotalImageNumber()
{
return m_nImgNumber;
}
std::string GetImgName(int nIndex)
{
return m_szImgs.at(nIndex);
}
int LoadImgsFromDir()
{
return LoadImgsFromDir("");
}
private:
int LoadImgsFromDir(const std::string &strDirName);
private:
typedef std::vector <std::string> IMG_SET;
IMG_SET m_szImgs;
int m_nImgNumber;
const std::string m_strImgDirName;
};
#endif
//成員函式實現在檔案ImgSet.cpp中:
#include "ImgSet.h"
#include <windows.h>
#include <Shlwapi.h>
/**
strSubDirName:子資料夾名
*/
int CImgSet::LoadImgsFromDir(const std::string &strSubDirName)
{
WIN32_FIND_DATAA stFD = {0};
std::string strDirName;
if ("" == strSubDirName)
{
strDirName = m_strImgDirName;
}
else
{
strDirName = strSubDirName;
}
std::string strFindName = strDirName + "//*";
HANDLE hFile = FindFirstFileA(strFindName.c_str(), &stFD);
BOOL bExist = FindNextFileA(hFile, &stFD);
for (;bExist;)
{
std::string strTmpName = strDirName + stFD.cFileName;
if (strDirName + "." == strTmpName || strDirName + ".." == strTmpName)
{
bExist = FindNextFileA(hFile, &stFD);
continue;
}
if (PathIsDirectoryA(strTmpName.c_str()))
{
strTmpName += "//";
LoadImgsFromDir(strTmpName);
bExist = FindNextFileA(hFile, &stFD);
continue;
}
std::string strSubImg = strDirName + stFD.cFileName;
m_szImgs.push_back(strSubImg);
bExist = FindNextFileA(hFile, &stFD);
}
m_nImgNumber = m_szImgs.size();
return m_nImgNumber;
}
四.建立CHistogram,生成影象的直方圖表示
//ImgHistogram.h
#ifndef _IMG_HISTOGRAM_H_
#define _IMG_HISTOGRAM_H_
#include <string>
#include "SIFTDiscriptor.h"
#include "ImgSet.h"
const int cnClusterNumber = 1500;
const int ciMax_D = FEATURE_MAX_D;
class CHistogram
{
public:
void SetTrainingImgSetName(const std::string strTrainingImgSet)
{
m_strTrainingImgSetName = strTrainingImgSet;
}
int FormHistogram();
CvMat CalculateImgHistogram(const string strImgName, int pszImgHistogram[]);
CvMat *GetObservedData();
CvMat *GetCodebook()
{
return m_pCodebook;
}
void SetCodebook(CvMat *pCodebook)
{
m_pCodebook = pCodebook;
m_bSet = true;
}
public:
CHistogram():m_pszHistogram(0), m_nImgNumber(0), m_pObservedData(0), m_pCodebook(0), m_bSet(false){}
~CHistogram()
{
if (m_pszHistogram)
{
delete m_pszHistogram;
m_pszHistogram = 0;
}
if (m_pObservedData)
{
cvReleaseMat(&m_pObservedData);
m_pObservedData = 0;
}
if (m_pCodebook && !m_bSet)
{
cvReleaseMat(&m_pCodebook);
m_pCodebook = 0;
}
}
private :
bool m_bSet;
CvMat *m_pCodebook;
CvMat *m_pObservedData;
std::string m_strTrainingImgSetName;
int (*m_pszHistogram)[cnClusterNumber];
int m_nImgNumber;
};
#endif
#include "ImgHistogram.h"
int CHistogram::FormHistogram()
{
int nRet = 0;
CImgSet iImgSet(m_strTrainingImgSetName);
nRet = iImgSet.LoadImgsFromDir();
const int cnTrainingImgNumber = iImgSet.GetTotalImageNumber();
m_nImgNumber = cnTrainingImgNumber;
CSIFTDiscriptor *pDiscriptor = new CSIFTDiscriptor[cnTrainingImgNumber];
int nIPNumber(0) ;
for (int i = 0; i < cnTrainingImgNumber; ++i) //計算每一幅訓練影象的SIFT描述符
{
const string strImgName = iImgSet.GetImgName(i);
pDiscriptor[i].SetImgName(strImgName);
pDiscriptor[i].CalculateSIFT();
nIPNumber += pDiscriptor[i].GetInterestPointNumber();
}
double (*pszDiscriptor)[FEATURE_MAX_D] = new double[nIPNumber][FEATURE_MAX_D]; //儲存所有描述符的陣列。每一行代表一個IP的描述符
ZeroMemory(pszDiscriptor, sizeof(int) * nIPNumber * FEATURE_MAX_D);
int nIndex = 0;
for (int i = 0; i < cnTrainingImgNumber; ++i) //遍歷所有影象
{
struct feature *pFeatureArray = pDiscriptor[i].GetFeatureArray();
int nFeatureNumber = pDiscriptor[i].GetInterestPointNumber();
for (int j = 0; j < nFeatureNumber; ++j) //遍歷一幅影象中所有的IP(Interesting Point興趣點
{
for (int k = 0; k < FEATURE_MAX_D; k++)//初始化一個IP描述符
{
pszDiscriptor[nIndex][k] = pFeatureArray[j].descr[k];
}
++nIndex;
}
}
CvMat *pszLabels = cvCreateMat(nIPNumber, 1, CV_32SC1);
//對所有IP的描述符,執行KMeans演算法,找到cnClusterNumber個聚類中心,儲存在pszClusterCenters中
if (!m_pCodebook) //構造碼元表
{
CvMat szSamples,
*pszClusterCenters = cvCreateMat(cnClusterNumber, FEATURE_MAX_D, CV_32FC1);
cvInitMatHeader(&szSamples, nIPNumber, FEATURE_MAX_D, CV_32FC1, pszDiscriptor);
cvKMeans2(&szSamples, cnClusterNumber, pszLabels,
cvTermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, 10, 1.0 ),
1, (CvRNG *)0, 0, pszClusterCenters); //
m_pCodebook = pszClusterCenters;
}
m_pszHistogram = new int[cnTrainingImgNumber][cnClusterNumber]; //儲存每幅影象的直方圖表示,每一行對應一幅影象
ZeroMemory(m_pszHistogram, sizeof(int) * cnTrainingImgNumber * cnClusterNumber);
//計算每幅影象的直方圖
nIndex = 0;
for (int i = 0; i < cnTrainingImgNumber; ++i)
{
struct feature *pFeatureArray = pDiscriptor[i].GetFeatureArray();
int nFeatureNumber = pDiscriptor[i].GetInterestPointNumber();
// int nIndex = 0;
for (int j = 0; j < nFeatureNumber; ++j)
{
// CvMat szFeature;
// cvInitMatHeader(&szFeature, 1, FEATURE_MAX_D, CV_32FC1, pszDiscriptor[nIndex++]);
// double dbMinimum = 1.79769e308;
// int nCodebookIndex = 0;
// for (int k = 0; k < m_pCodebook->rows; ++k)//找到距離最小的碼元,用最小碼元代替原//來的詞彙
// {
// CvMat szCode = cvMat(1, m_pCodebook->cols, m_pCodebook->type);
// cvGetRow(m_pCodebook, &szCode, k);
// double dbDistance = cvNorm(&szFeature, &szCode, CV_L2);
// if (dbDistance < dbMinimum)
// {
// dbMinimum = dbDistance;
// nCodebookIndex = k;
// }
// }
int nCodebookIndex = pszLabels->data.i[nIndex++]; //找到第i幅影象中第j個IP在Codebook中的索引值nCodebookIndex
++m_pszHistogram[i][nCodebookIndex]; //0<nCodebookIndex<cnClusterNumber;
}
}
//資源清理,函式返回
// delete []m_pszHistogram;
// m_pszHistogram = 0;
cvReleaseMat(&pszLabels);
// cvReleaseMat(&pszClusterCenters);
delete []pszDiscriptor;
delete []pDiscriptor;
return nRet;
}
//double descr_dist_sq( struct feature* f1, struct feature* f2 );
CvMat CHistogram::CalculateImgHistogram(const string strImgName, int pszImgHistogram[])
{
if ("" == strImgName || !m_pCodebook || !pszImgHistogram)
{
return CvMat();
}
CSIFTDiscriptor iImgDisp;
iImgDisp.SetImgName(strImgName);
iImgDisp.CalculateSIFT();
struct feature *pImgFeature = iImgDisp.GetFeatureArray();
int cnIPNumber = iImgDisp.GetInterestPointNumber();
// int *pszImgHistogram = new int[cnClusterNumber];
// ZeroMemory(pszImgHistogram, sizeof(int)*cnClusterNumber);
for (int i = 0; i < cnIPNumber; ++i)
{
double *pszDistance = new double[cnClusterNumber];
CvMat iIP = cvMat(FEATURE_MAX_D, 1, CV_32FC1, pImgFeature[i].descr);
for (int j = 0; j < cnClusterNumber; ++j)
{
CvMat iCode = cvMat(1, FEATURE_MAX_D, CV_32FC1);
cvGetRow(m_pCodebook, &iCode, j);
CvMat *pTmpMat = cvCreateMat(FEATURE_MAX_D, 1, CV_32FC1);
cvTranspose(&iCode, pTmpMat);
double dbDistance = cvNorm(&iIP, pTmpMat); //計算第i個IP與第j個code之間的距離
pszDistance[j] = dbDistance;
cvReleaseMat(&pTmpMat);
}
double dbMinDistance = pszDistance[0];
int nCodebookIndex = 0; //第i個IP在codebook中距離最小的code的索引值
for (int j = 1; j < cnClusterNumber; ++j)
{
if (dbMinDistance > pszDistance[j])
{
dbMinDistance = pszDistance[j];
nCodebookIndex = j;
}
}
++pszImgHistogram[nCodebookIndex];
delete []pszDistance;
}
CvMat iImgHistogram = cvMat(cnClusterNumber, 1, CV_32SC1, pszImgHistogram);
return iImgHistogram;
}
CvMat *CHistogram::GetObservedData()
{
CvMat iHistogram;
cvInitMatHeader(&iHistogram, m_nImgNumber, cnClusterNumber, CV_32SC1, m_pszHistogram);
CvMat *m_pObservedData = cvCreateMat(iHistogram.cols, iHistogram.rows, CV_32SC1);
cvTranspose(&iHistogram, m_pObservedData);
return m_pObservedData;
}