
HshMap 資料結構以及原始碼分析
最近整理資料結構方面的知識點,HashMap是很重要的一部分,今天來聯合原始碼分析他的資料結構以及儲存方式!
接下來將從以下幾個方面來分析(根據JDK1.8)
1. 構造方法
2. 重要的幾個資料解釋
3. put
4. get
HashMap 的幾個重要資料解釋
- HashMap 使用陣列+連結串列進行儲存,基本節點形式如下:
// 儲存資料的陣列 table
transient Node<K,V>[] table;
// 儲存資料的基本型別
static class Node<K,V> implements Map.Entry<K,V> { - final float loadFactor; 載入因子
- int threshold; // 臨界值,當大於臨界值就擴容
- transient int modCount; // 當前map物件的修改次數
HshMap的構造方法:
總共有四個構造方法
// initialCapacity:指定Map的容量大小
// loadFactor: 指定載入因子, 預設是DEFAULT_LOAD_FACTOR 0.75
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw put
首先來說明下HashMap的資料結構 (圖是從別的地方借用的)
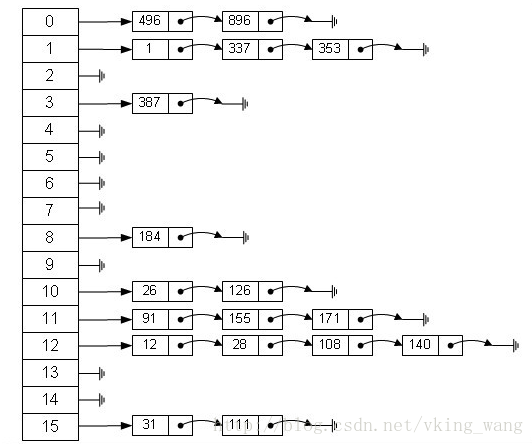
在HashMap 進行儲存資料時,我覺得可以從三點來判斷 :
1 . 如何判定key的唯一性
2. 如何通過key計算hash值,並且可以通過hash值計算得到應該放置的陣列的位置
3. 什麼時候擴容
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K, V>[] tab;
Node<K, V> p;
int n, i;
// 首先判斷table是否有資料,如果沒有就呼叫resize方法給map分配空間
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 通過 i = (n - 1) & hash 計算得到 陣列的位置,如果這個位置沒有值,就直接儲存;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 說明計算得到的陣列的位置有值
Node<K, V> e;
K k;
// 首先判斷陣列上的儲存的key和要儲存的key是否相同,如果相同就覆蓋
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 紅黑樹儲存
else if **(p instanceof TreeNode)**
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
else {
// 接下來,就通過遍歷連結串列,判斷key值是否一致
for (int binCount = 0; ; ++binCount) {
// 走到連結串列末尾
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 對於找到的相同的key的Node,進行value覆蓋
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// map 被修改的次數+1
++modCount;
// 如果長度達到臨界值,進行擴容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}通過上面的程式碼註釋,應該對HashMap的儲存方式有更進一步的認識。整個過程就是我們拿到Node的hash值,來計算應該放置的位置,不管value值是Null或者和已經存在的值是否重複,只要找到位置後,放置進去,就OK。
final Node<K, V>[] resize() {
Node<K, V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
} else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float) newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ?
(int) ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes", "unchecked"})
Node<K, V>[] newTab = (Node<K, V>[]) new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K, V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if **(e instanceof TreeNode)**
((TreeNode<K, V>) e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K, V> loHead = null, loTail = null;
Node<K, V> hiHead = null, hiTail = null;
Node<K, V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
} else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
resize方法:無非就是重新申請空間,如果一開始是0,就採用和構造方法一樣的設定,預設初始大小16;如果之前有資料就成倍增加,並計算新的臨界值,重新通過hash值計算在陣列中的位置,把之前的資料拷貝到新申請的陣列上;陣列的擴容是非常耗費效能的,如果我們能提前預算出陣列的大小,我們在初始化時可以直接進行指定;
get
首先我們來看原始碼,讀取資料相對儲存資料簡單寫,我們只需要通過key,判斷key的合法性以及通過計算hash 定為元素在陣列的位置即可。
public V get(Object key) {
Node<K, V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K, V> getNode(int hash, Object key) {
Node<K, V>[] tab;
Node<K, V> first, e;
int n;
K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
**if (first instanceof TreeNode)**
return ((TreeNode<K, V>) first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}經過上面的分析,我們知道HashMap主要通過陣列+連結串列的形式儲存資料,當儲存的資料過多的時候,連結串列越來越重,之後我們查詢起來時間也越來越長,效率越來越低,
JDK 1.8 之後的改進
我們可以看到其中(e instanceof TreeNode) 判斷節點是否是TreeNode,JDK1.8中,HashMap採用陣列+連結串列+紅黑樹來實現,當連結串列長度超過閾值(8)時,將連結串列轉換為紅黑樹,這樣大大減少了查詢時間。
static final class TreeNode<K, V> extends LinkedHashMap.LinkedHashMapEntry<K, V> {
TreeNode<K, V> parent; // red-black tree links
TreeNode<K, V> left;
TreeNode<K, V> right;
TreeNode<K, V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K, V> next) {
super(hash, key, val, next);
}
...
}
和HashMap相似的HashSet其實就是變形的HashMap,我們可參考這篇文章HashSet簡單看下 他們的區別。