
大資料經典演算法——bit-map與bloom filter
明白了雜湊的原理,bit-map就好說了。
bit-map的核心思想是:所謂的Bit-map就是用一個bit位來標記某個元素對應的Value, 而Key即是該元素。每一個bit空間都是儲存單元,而不像整型資料,即便是int a =1,仍要佔用32個位元組的空間,當資料量很大時,就會造成嚴重的空間浪費。由此可見,bit-map可以極大的節省空間,但bit-map只能用來進行一些簡單的操作,比如,查詢元素是否存在於資料中,資料去重,資料排序等。值得注意的是,數字型資料更適合bit-map,如果是文字記錄或者字串,很難都被雜湊函式對映為整型數字。
排序
首先bit-map初始化為全零,通過一個雜湊函式,分別將資料對映到bit-map的某一位置,將該位置處資料置1。看一個《程式設計珠璣》上的例子,元素為{4,7,2,5,3}用bit-map來儲存,元素4儲存的位置如下:
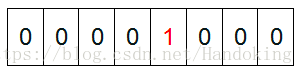
依次儲存:

可以看到這裡對映選取的比較簡單,同時依次遍歷bit-map還完成了排序。
查詢元素是否在資料集合中的問題
首先同樣雜湊函式依次將資料對映標記到bit-map中,查詢元素對映到某一位置已經標記為1,判定為存在。當然bit-map這樣會出現誤判,錯誤率也很高,效果並不理想,這就是bit-map擴充套件為bloom filter的原因。因此查詢元素是否在資料集合中的問題,應該用布隆過濾器來解決(見下文)。
資料去重問題
例1:)已知某個檔案內包含一些電話號碼,每個號碼為8位數字,統計不同號碼的個數。
可以理解為從0-99999999的數字,每個數字對應一個Bit位,所以只需要99M個Bit==12MBytes,這樣,就用了小小的12M左右的記憶體表示了所有的8位數的電話。
同樣儲存大資料的方法用於以下例子:
2.5億個整數中找出不重複的整數的個數,記憶體空間不足以容納這2.5億個整數。大約需要300M左右。這裡為了查重,使用兩個bit值來表示三種狀態,不存在,存在,重複分別標記為00,01,11。將資料依次對映到此bit-map中,最後遍歷輸出bit-map的key值即可。
Bloom Filter
布隆過濾器可以看成是對bit-map的擴充套件,它採用K個雜湊函式進行對映,這樣減少誤判,因為每一個元素需要對映K個位置均已標記為1,才說明了這個元素存在於資料集合中。減少誤判,並不能做到完全沒有。在我們的資料結構或者演算法中,往往是犧牲空間得到效率的提升,或者降低效率提高空間的利用率。而布隆過濾器給出了一個新的方法,就是引入了誤判率,節省空間,並不降低效率。當資料量很大時,布隆過濾器的效率並不會因此降低,但誤判率會提高。因此選取雜湊函式的個數k,位陣列的大小m以及字串的量n很重要。
官方文件中給出一個計算公式:K=ln2*(m/n)=0.7(m/n),此時的誤判率最低。
以下是使用三個雜湊函式的布隆濾波器示意圖
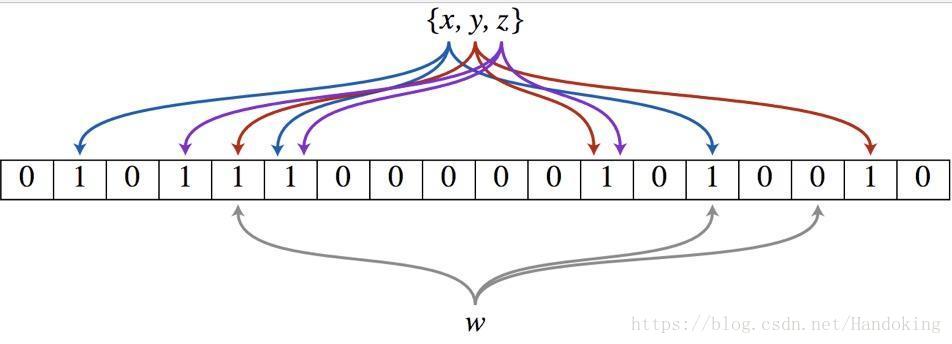
判重問題: 將查詢的元素經過三個雜湊函式對映後,如果三個標記位均為1,說明此元素在資料集合中存在(上面提到,是存在誤判的)。