
hadoop-2.2.0偽分散式與(全分佈叢集安裝於配置續,很詳細的哦~)
hadoop-2.2.0偽分散式與(全分佈叢集安裝於配置續)
hadoop-2.2.0全分佈叢集安裝於配置點選開啟連結
一、偽分佈模式
1、前提說明
我這裡配置hadoop叢集均是在虛擬機器上配置的,使用的安裝環境說明如下:
(1) 宿主機win7x64
(2) Vmware-workstation10.0.4
(3) 虛擬機器Ubuntu12.0.4(較穩定版本):使用的是32位,沒有使用64的原因是為了方便配置hbase,hbase目前
不直接提供64位版本的,需要自己編譯原始碼,為了方便選擇32位的。
(4) JDK1.8.0(Apache版本)
(5) Hadoop-2.2.0
2、虛擬環境配置
(1) VMwareWorkstation安裝,下載連結:http://bfile.xp510.com:801/bigfile/VMware-workstation_xp510.com.zip
(2) Ubuntu12.0.4安裝,映象檔案官網下載地址:
http://mirrors.hustunique.com/ubuntu-releases//precise/ubuntu-12.04.4-desktop-i386.iso
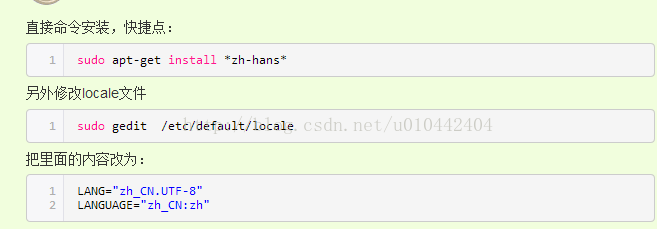
(3) 虛擬機器安裝好以後是英文版本的,漢化步驟如下:
首先進入虛擬機器系統設定
更新語言包(或者直接使用下面的命令安裝),將語言選擇成簡體中文
編輯locale如下配置檔案,修改好後重啟虛擬機器即可
(4) 虛擬機器安裝好了,可以進行接下里的工作了
3、升級軟體、安裝ssh
執行以下命令將部分軟體升級,以及將ssh安裝好
sudo apt-get update;
sudo apt-get upgrade;
sudo apt-get install openssh-server;
4、JDK安裝
(1) 建立使用者以及使用者組,命令如下:
建立使用者:sudo addgroup hadoop
建立使用者,並新增到hadoop使用者組中: sudo
adduser --ingroup hadoop hduser
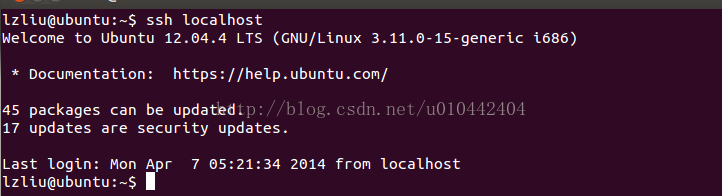
(2) 建立ssh信任關係,在啟動hadoop時要頻繁輸入密碼,建立這個關係後可省去輸入密碼麻煩
cd /home/hduser
ssh-keygen -t rsa -P ""
cat .ssh/id_rsa.pub >>.ssh/authorized_keys
成功執行三條命令後,通過ssh localhost驗證,如下圖不需要輸入密碼就表示成功了
(3) 將下載後的jdk解壓到某個路徑下,我這裡是解壓到/opt
解壓命令如下:
sudo tar zxf /home/lzliu/software/jdk-8-linux-i586.gz /opt
(4) 配置java環境變數
編輯profile檔案:sudo gedit /etc/profile
在檔案後面加入jdk路徑

一般系統裡面都預先安裝了openjdk,我們可以通過以下方法將預設jdk更改過來


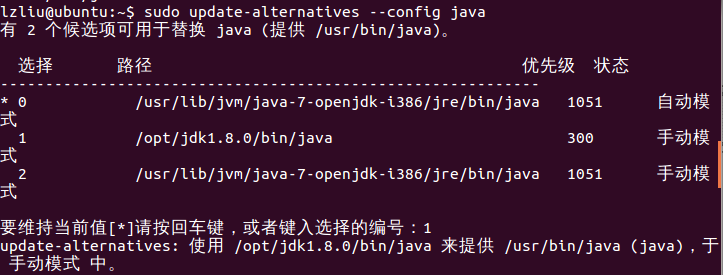
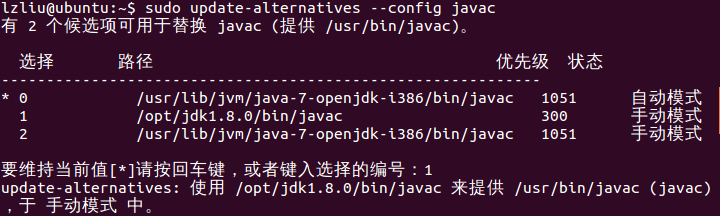
如果輸入命令java -version顯示的是你安裝的java版本就對了。
5、hadoop-2.2.0配置(偽分佈模式)
(1) 到Apache官網下載hadoop-2.2.0版本,網址:http://mirrors.cnnic.cn/apache/hadoop/common/hadoop- 2.2.0/hadoop-2.2.0.tar.gz
(2) 將hadoop解壓到/home/hduser目錄下,命令如下
tar -zxf /home/lzliu/software/hadoop-2.2.0.tar.gz /home/hduser/
(3) 配置hadoop-env.sh(JAVA路徑安裝)
編輯檔案:sudo /home/hduser/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0
(4) 接下來編輯如下三個檔案:
sudo gedit /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xml
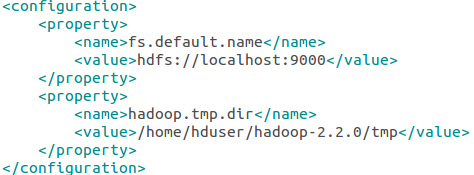
sudo gedit /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
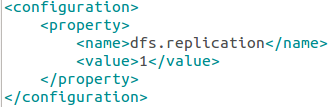
sudo gedit /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-queues.xml(如果沒有這個檔案,可通過mapred- queues.xml.template這個模板檔案複製一個)

6、hadoop-2.2.0偽分佈模式測試
(1) 啟動hadoop
cd ~/sbin
./start-all.sh
輸入jps檢視程序,如果有以下幾個程序證明啟動成功:

(2) 執行hadoop自帶的詞頻統計的例子
(執行以下步驟的前提是先啟動hadoop,namenode和datanode程序必須啟動)
首先在hdfs虛擬檔案上建立資料夾input 命令:hdfsdfs -mkdir /input
上傳檔案到hdfs上命令:hdfs dfs -put /home/hduser/hadoop-2.2.0/etc/hadoop/ /input
執行例子,命令
hadoop jar/home/hduser/hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples- 2.2.0.jarwordcount /input/hadoop /output
結果:

自此,hadoop-2.2.0偽分佈模式就配置成功了,接下來的一片部落格裡我將介紹,hadoop-2.2.0全分佈叢集配置,將的也很詳細哦~
(我是劉立洲,我為自己帶鹽,IT屌絲~)