
在Ubuntu 上搭建hadoop-2.6.0-cdh分散式叢集
1 虛擬機器配置
| 序號 | 作業系統 | CPU/core | 記憶體/GB | 硬碟/GB | IP地址 | 主機名 |
|---|---|---|---|---|---|---|
| 1 | Ubuntu | 2 | 3 | 20 | 192.168.0.122 | master |
| 2 | Ubuntu | 1 | 2 | 20 | 192.168.0.123 | slave1 |
| 3 | Ubuntu | 1 | 2 | 20 | 192.168.0.124 | slave2 |
2 叢集網路配置
2.1 修改主機名
主節點名字為master,另外2個節點名字分別為slave1和slave2
[email protected]:~# vim /etc/hostname
master
2.2 新增對映
未了方便後續操作,3個節點都新增IP和主機名的對映
[email protected]:~# vim /etc/hosts
192.168.0.122 master
192.168.0.123 slave1
192.168.0.124 slave2
3 叢集ssh免密登入配置
3.1 生成公鑰和私鑰
在3個節點上都生成ssh key
[email protected]:ssh-keygen -t rsa
3.2 將公鑰複製到遠端機器中
在master上執行下面3行命令
[email protected]:~$ ssh-copy-id -i ~/.ssh/id_rsa.pub master
[email protected] 3.3免密ssh登陸測試
[email protected]:~$ ssh master
[email protected]:~$ ssh slave1
[email protected]:~$ ssh slave2
4 在主節點安裝JDK和Hadoop
4.1 安裝jdk
[email protected]: tar -zxvf java.tar.gz -C ~/app //解壓
//設定JVM環境變數
4.2 安裝hadoop
[email protected]:tar -zxvf hadoop-2.6.0-cdh5.9.3.tar.gz -C ~/app
[email protected]:mv app/hadoop-2.6.0-cdh5.9.3 ~/app/hadoop
#設定hadoop環境變數
[email protected]:echo 'export HADOOP_HOME=/home/hadoop/app/hadoop' >> ~/.bashrc
[email protected]:echo 'PATH=${HADOOP_HOME}/bin:$PATH' >> ~/.bashrc
[email protected]:source ~/.bashrc //重新整理
5 Hadoop叢集主節點配置
5.1 配置環境變數
[email protected]:~/app/hadoop/etc/hadoop$ vim hadoop-env.sh
將export JAVA_HOME=${JAVA_HOME}替換為
export JAVA_HOME= /home/hadoop/app/java
5.2 開放埠號和指定臨時資料夾
[email protected]:~/app/hadoop/etc/hadoop$ vim core-site.xml
新增:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:8020</value>
</property>
</configuration>
5.3 配置副本數和儲存位置
//預設副本系數為3
[email protected]:~/app/hadoop/etc/hadoop$ vim hdfs-site.xml
新增:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/tmp/dfs/data</value>
</property>
</configuration>
5.4 配置yarn
[email protected]:~/app/hadoop/etc/hadoop$ vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
5.5 設定提交的 Yarn job 只執行在分散式模式
[email protected]:~/app/hadoop/etc/hadoop$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.6 配置datanode執行位置
[email protected]:~/app/hadoop/etc/hadoop$ vim slaves
將localhost替換為:
master
slave1
slave2
6 Hadoop叢集從節點的配置
6.1 拷貝配置
將第4和5步配置拷貝到slave1和slave2上
[email protected]:~$ scp -r /home/hadoop/app/ [email protected]:~/
[email protected]:~$ scp -r /home/hadoop/app/ [email protected]:~/
[email protected]:~$ scp /home/hadoop/.bashrc [email protected]:~/.bashrc
[email protected]:~$ scp /home/hadoop/.bashrc [email protected]:~/.bashrc
6.2重新整理slave1和slave2配置檔案
[email protected]:~$ source .bashrc
[email protected]:~$ source .bashrc
6.4驗證3個節點JDK和Hadoop是否按裝成功
在3個節點分別檢視是否能輸出配置資訊
[email protected]: echo `java -version //輸出java版本資訊
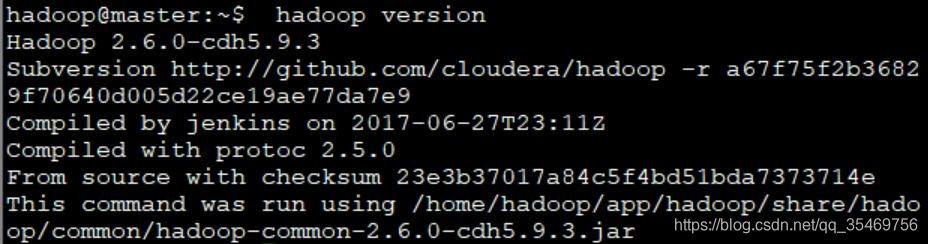
[email protected]:hadoop version //輸出hadoop版本資訊

7 Hadoop叢集的啟停
7.1 初始化
首次啟動時,只在master節點格式化檔案系統。執行完後可以看到在~/app/tmp/ dfs/下面會自動生成一個叫name的資料夾
[email protected]:~/app/hadoop/bin$ ./hdfs namenode -format
7.2 啟動hadoop叢集
[email protected]:~/app/hadoop/sbin$ ./start-all.sh
7.3 驗證叢集是否啟動成功
方法1:檢視程序數
[email protected]:~/app/hadoop/sbin$ jps:
在主節點上可以看到下面5個程序
2678 ResourceManager
2810 NodeManager
2350 DataNode
2191 NameNode
2543 SecondaryNameNode
從節點只有2個
1665 DataNode
1805 NodeManager
方法2:在瀏覽器訪問console頁面
訪問hadoop頁面:
http://192.168.0.122:50070
訪問yarn頁面:
http://192.168.0.122:8088/cluster
7.4停止hadoop叢集
[email protected]:~/app/hadoop/sbin$ ./stop-all.sh
8 提交MapeReduce Job
8.1 在HDFS上建立資料夾
[email protected]:~/app/data$ hadoop fs -mkdir /data
8.2 建立資料來源wordcont.txt
[email protected]:~ /app/data$ vim wordcont.txt
新增:
hello hadoop
hello spark
8.3 將wordcond.txt提交到HDFS
[email protected]:~/app/data$ hadoop fs -put wordcount.txt /data
8.4 檢視是否新增成功
[email protected]:~/app/data$ hadoop fs -ls -R /
8.5 執行MR程式
[email protected]:~/app/hadoop/share/hadoop/mapreduce$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.9.3.jar wordcount /data /result
其中 wordcount為程式的主類名, /data 輸入目錄, /result 輸出目錄,且輸出目錄不能存在,否則會報錯
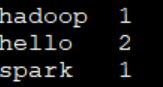
8.6 檢視統計結果
[email protected]:~/app/data$ hadoop fs -ls -R /result

[email protected]:~/app/data$ hadoop fs -cat /result/part-r-00000
9 Hadoop shell指令小結
[email protected]:~$ hadoop fs + 命令
常見命令:
-ls -R / 遞迴顯示/下所有資料夾
-get /hello.txt 將hdfs的檔案下載到本地
-put ~/data/hello.txt /input/wc 講本地檔案上傳到hdfs
-cat /hello.txt 檢視文字內容
-mkdir /text 建立資料夾
-rm /hello.txt 刪除檔案
-rm -R /text 刪除資料夾
相關推薦
在Ubuntu 上搭建hadoop-2.6.0-cdh分散式叢集
1 虛擬機器配置 序號 作業系統 CPU/core 記憶體/GB 硬碟/GB IP地址 主機名 1 Ubuntu 2 3 20 192.168.0.122 master 2 Ubuntu 1 2 20 192.168.0.123 slave
Windows環境下搭建Hadoop(2.6.0)+Hive(2.2.0)環境並連線Kettle(6.0)
前提:配置JDK1.8環境,並配置相應的環境變數,JAVA_HOME 一.Hadoop的安裝 1.1 下載Hadoop (2.6.0) http://hadoop.apache.org/releases.html 1.1.1 下載對應版本的winutils(https://gith
CentOS 6.5下搭建hadoop 2.6.0叢集(二):網路配置
以Master機器為例,即主機名為”Master.hadoop”,IP為”192.168.2.30”進行一些主機名配置的相關操作。其他的Slave機器以此為依據進行修改。 檢視當前機器名稱 用下面命令進行顯示機器名稱,如果跟規劃的不一致,要按照下面進行修
centos下hadoop-2.6.0完全分散式搭建
一、Hadoop執行模式: Hadoop有三種執行模式,分別如下: 單機(非分散式)模式 偽分散式(用不同程序模仿分散式執行中的各類節點)模式 完全分散式模式 注:前兩種可以在單機執行,最後一種用於真
CentOS 64位上編譯Hadoop 2.6.0原始碼包
Hadoop不提供64位編譯好的版本,只能用原始碼自行編譯64位版本。學習一項技術從安裝開始,學習hadoop要從編譯開始。 1.作業系統編譯環境 yum install cmake lzo-devel zlib-devel gcc gcc-c++ autocon
windows下搭建hadoop-2.6.0本地idea開發環境
概述 本文記錄windows下hadoop本地開發環境的搭建: OS:windows hadoop執行模式:獨立模式 安裝包結構: Hadoop-2.6.0-Windows.zip -
阿里雲虛擬機器搭建Hadoop-2.6.0-cdh5.7.1安裝詳解(偽分散式環境)
首先先搭配安全組 開啟映象後輸入以下內容: 重要: yum -y install lrzsz HOSTNAME=(自己的主機名字) hostname $HOSTNAME echo "$(grep -E '127|::1' /etc/host
Hadoop-2.8.0之分散式叢集(HA架構)搭建
1、安裝前準備 ①、叢集規劃: 主機名稱 使用者 主機IP 安裝軟體 執行程序 centos71 hzq 192.168.1.201 jdk、hadoop NameNode、DFSZKFailoverController(zkfc
hadoop-2.6.5偽分散式叢集搭建
本次搭建的偽分散式hadoop叢集所使用的作業系統是紅帽5,64位系統。 所以,需要注意以下幾點: 1、jdk和hadoop安裝包也應該是64位的 2、64位的jdk是從檔名可以直接看出,例如:jdk-8u172-linux-x64.tar.gz 3、而
hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3節點叢集搭建(含zookeeper叢集安裝)
前言 附連結如下: http://blog.csdn.net/u010270403/article/details/51446674 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:stat
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz的叢集搭建(單節點)(Ubuntu系統)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言的程式設計,如paython
hadoop-2.6.0-cdh5.7.0偽分散式搭建
1,這個我們是直接在linux中下載hadoop-2.6.0-cdh5.7.0,(當然你也可以在本地下載後再上傳,這步就可以忽略)首先確保你的虛擬機器有網路,可以先ping百度測試有網沒,如下程式碼就是有網路的情況。 [[email protected
VirtualBox+Centos7+(jdk1.7.0_71+Hadoop-2.6.0)/(jdk1.10+Hadoop-2.9.1)搭建完全分散式叢集平臺
VirtualBox+Centos7+(jdk1.7.0_71+Hadoop-2.6.0)/(jdk1.10+Hadoop-2.9.1)搭建完全分散式叢集平臺 本文有很多是自定義的,可以根據自己的實際情況和需求修改,儘量會用紅色標註出來,當然按照步驟,一步一步應該也能成功,不
hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz的叢集搭建(單節點)(CentOS系統)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言
hadoop-2.6.0.tar.gz的叢集搭建(3節點)(不含zookeeper叢集安裝)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言的程式設計,如paython或s
Hadoop-2.6.0+Zookeeper-3.4.6+Spark-1.5.0+Hbase-1.1.2+Hive-1.2.0叢集搭建
前言 本部落格目的在於跟大家分享大資料平臺搭建過程,是筆者半年的結晶。在大資料搭建過程中,希望能給大家提過一些幫助,這也是本部落格的
Ubuntu 14.04 (32位)上搭建Hadoop 2.5.1單機和偽分散式環境
引言 一直用的Ubuntu 32位系統(準備下次用Fedora,Ubuntu越來越不適合學習了),今天準備學習一下Hadoop,結果下載Apache官網上釋出的最新的封裝好的2.5.1版,配置完了根本啟動不起來,檢視錯誤日誌發現是native庫的版本和系統不一致,使用fil
我的Hadoop大資料叢集搭建經歷 (Hadoop 2.6.0 & VMWare WorkStation 11)
centos 6.6 i386 dvd ; basic server installation ; not enable static ip ; not disable ipv6 vmware net model is NAT , subNet Ip : 192.168.5
hadoop 2.6.0 LightWeightGSet源碼分析
lar therefore name ref implement urn round runtime info LightWeightGSet的作用用一個數組來存儲元素,而且用鏈表來解決沖突。不能rehash。所以內部數組永遠不用改變大小。此類不支持空元素。此類也不是線
搭建Ambari 2.6.0 tar 解壓縮報錯
pos span 使用 解決方案 centos7 .gz res val unzip 背景:我們使用的方式不是wget 去下載ambari的源碼包,而是在windows 的 firefox 下直接下載,將文件存儲到本地。 執行 tar -zxvf HDP-2.6.3.0-c