
泰坦尼克號預測學習總結
一 明確課題:
在泰坦尼克號之災事件中,建立乘客獲救情況(是/否)與其諸背景特徵之間的量化模型,並且依據此模型來預測有某些背景的人在該海難中能否獲救。
二 課題分析:
2.1 一個二分類問題。常用的分類演算法有邏輯迴歸、隨機森林、支援向量機(SVM)等等。
我們可以選擇其中的一種演算法進行模型建立,或是嘗試使用多種演算法建立模型並融合。
對於同一個問題,可以嘗試多種思路進行解決,尤其是演算法模型建立的過程,與問題的背景,
資料的型別,分析計算條件的限制都有關係。
2.2 模型的建立和優化是一個動態的過程,其中有許多嘗試和反覆,不必開始就要求過高,
先試圖建立一個基本的模型,然後再一步步不斷的優化。
2.3 優化過程包括:
A.分析現在模型的擬合狀態(欠/過擬合?)
B.分析模型中使用的特徵的貢獻大小,進行特徵選擇,這也是特徵工程的一部分。
C.預測失敗案例產生的原因。
D.。。。
三 收集資料:
資料可以從網頁中、感測器網路等等許多媒介中獲取,這個專案中的資料直接來源於Kaggle競賽平臺,
是現成的資料。
四 認識資料
拿到資料後的第一步不是立即將其投入模型建立,而是先初步的認識瞭解資料,對該資料集建立一
個基本的概念。這個過程主要用到python中的numpy、pandas和matplotlib包。
4.1 匯入資料
data_train = pd.read_csv('train.csv')對ipython notebook早有耳聞,第一次使用,與pycharm 相比,表格化的顯示更清晰!

4.2 瞭解資料集基本資訊
弄清楚每一項列名的實際含義和定義(refer to泰坦尼克號資料集):
passengerId:乘客ID
survived:是否被救獲
Pclass:乘客等級(艙位等級分為1/2/3等)
Name:乘客姓名
Sex:乘客性別
Age:乘客年齡
SibSp:siblings&spoused,該乘客在船上的堂兄弟妹/配偶人數
Ticket:船票資訊
Fare:票價
Cabin:客艙
Embarked:登船港口
弄清楚資料集的資料條數和各列資訊的完整性:

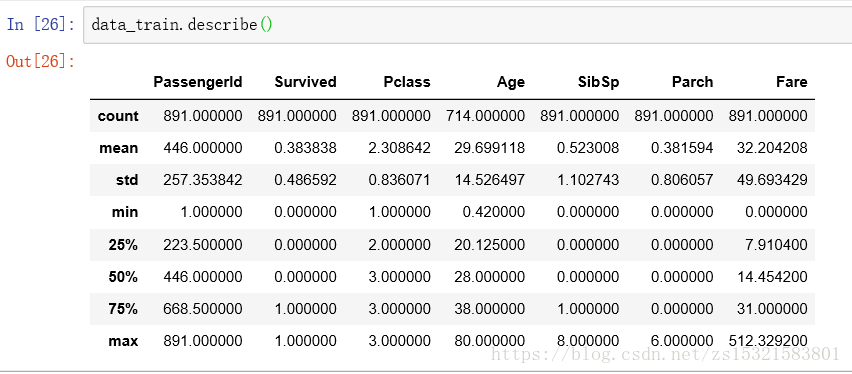
瞭解資料集各列的統計資訊(針對數值型資料):
4.3 各項特徵與結果的關聯統計
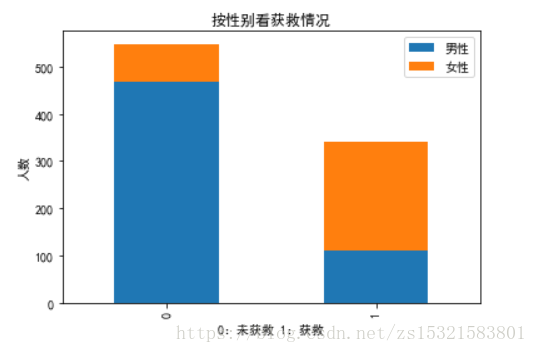
比如性別與是否獲救的關係(一對一的關係圖表展示):
# 看看各性別的獲救情況
# 建立一張空白圖表
plt.figure()
# 統計各性別乘客獲救情況
survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
# 將各性別獲救與未獲救的情況做成一個數據框
df = pd.DataFrame({u'男性':survived_m,u'女性':survived_f})
# 用資料框中的資料畫一個堆疊條形圖
df.plot(kind='bar',stacked=True,title=u'按性別看獲救情況')
plt.xlabel(u'0:未獲救 1:獲救')
plt.ylabel( u'人數')
plt.show()
再比如:
# 把資料框按照是否獲救和有幾個父母孩子分組,然後統計個數,結果是一個其餘各列分組統計個數的資料框
g = data_train.groupby(['Survived', 'Parch'])
g.count()['PassengerId']
父母子女的個數對是否獲救貌似沒有顯著的影響。
五 簡單資料預處理*
從上一步的資料概覽中初步瞭解到資料集中有缺失資料(如年齡和艙位),有字串資料(如名字和票價),
有型別資料(如性別和登船港口),這種資料多種分類演算法模型都無法使用,比如邏輯迴歸模型,只能使用
數值型資料(整型、浮點型、布林型)。
5.1 缺失值的處理
遇到缺失值的情況,幾種常見的處理方式如下:
- 如果缺值的樣本佔總數比例極高,我們可能就直接捨棄了,作為特徵加入的話,可能反倒帶入noise,影響最後的結果了
- 如果缺值的樣本適中,而該屬性非連續值特徵屬性(比如說類目屬性),那就把NaN作為一個新類別,加到類別特徵中
- 如果缺值的樣本適中,而該屬性為連續值特徵屬性,有時候我們會考慮給定一個step(比如這裡的age,我們可以考慮每隔2/3歲為一個步長),然後把它離散化,之後把NaN作為一個type加到屬性類目中。
- 有些情況下,缺失的值個數並不是特別多,那我們也可以試著根據已有的值,擬合一下資料,補充上。
Age特徵的缺失值比例為:(891-714)/891=0.2,不是特別多,而且Age是連續值特徵屬性,可以選擇
後兩種方法。一般來說,選擇缺失值擬合補全是在存在資料可以給缺失值提供一些影響的條件下才使用。
有多種方法可以給缺失值提供擬合值,比如迴歸、KNN、隨機森林等等。
此處採用隨機森林演算法擬合補全缺失值。
(sklearn和scipy的關係:前者依賴於後者)\
isnull()和notnull()用於資料框和Series,各項對應返回TRUE OR FALSE\
as_matrix 是將pd資料框或是系列轉化成np的矩陣,用於投入模型,現在這種方法
已經過時了,直接使用df.values就可以得到沒有標籤的矩陣了!\
df.loc[x_exp, y_exp]:用行和列的表示式給資料框中的元素定位\
用ipython還有一個好處,對錯誤的提示特別詳盡\
from sklearn.ensemble import RandomForestRegressor
### 使用 RandomForestClassifier 填補缺失的年齡屬性
def set_missing_ages(df):
# 把已有的數值型特徵取出來丟進Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年齡和未知年齡兩部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# y即目標年齡
y = known_age[:, 0]
# X即特徵屬性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型進行未知年齡結果預測
predictedAges = rfr.predict(unknown_age[:, 1:])
# 用得到的預測結果填補原缺失資料
df.loc[df.Age.isnull(), 'Age' ] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[df.Cabin.notnull(), 'Cabin' ] = "Yes"
df.loc[df.Cabin.isnull(), 'Cabin' ] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
5.2 類別型特徵因子化
所謂類別型變數因子化,就是將分類變數變成數值變數。
以Cabin為例,原本一個屬性維度,因為其取值可以使['yes','no],而將其平展開為Cabin-yes
Cabin_no兩個屬性:
- 原本Cabin取值為yes的,在此處的”Cabin_yes”下取值為1,在”Cabin_no”下取值為0
- 原本Cabin取值為no的,在此處的”Cabin_yes”下取值為0,在”Cabin_no”下取值為1
應用pandas的get_dummies()方法\
df 索引方法:df.iloc[]基於位置的索引;df.loc[]基於標籤的索引\
pd.concat([])預設豎向(即0向)相連結\
df.drop()也是預設刪除豎向的值(即0向),讓0向的維度減少\
注意區分:
df = df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)賦值的作用是將等號右邊的返回值賦給左邊,上一條因為是在地變動(inplace=True),所以賦值符右側的返回值為空(NoneType)
# 將'Cabin'因子化
dummies_Cabin = pd.get_dummies(data_train.Cabin, prefix='Cabin')
# 將'Embarked'因子化
dummies_Embarked = pd.get_dummies(data_train.Embarked, prefix='Embarked')
# 將‘Sex’因子化
dummies_Sex = pd.get_dummies(data_train.Sex, prefix='Sex')
# 將‘Pclass’因子化
dummies_Pclass = pd.get_dummies(data_train.Pclass, prefix='Pclass')
# 將生成的多維啞變數與原資料集連線,並且去掉原一維的分類變數
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass],axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
類別變數因子化完成!
5.3 特徵值縮放
觀察因子化後的資料框,發現Age和Fare兩個屬性與其他的屬性相比,其變化幅度大很多,
這有什麼影響呢?參考:梯度下降法
將範圍明顯過大的兩個值進行縮放,可以應用的方法,見:資料縮放方法總結
可以用np.ndarray給Series賦值\
values是pandas資料的屬性,而不是方法,使用values,而不是values()
age_scale = preprocessing.scale(df.Age.values)
fare_scale = preprocessing.scale(df.Fare.values)
df.loc[:,'Age'] = age_scale
df.loc[:,'Fare'] = fare_scale
縮放成功!
到此為止,資料集的預處理,包括缺失值處理、類別特徵處理、變化範圍異常特徵
標準化處理全部完成!
六 邏輯迴歸建模
就像擬合缺失值過程中使用隨機森林模型一樣,LogisticRegression模型也需要np.ndarray
格式的無標籤資料,即pandas資料.values。
# 先使用df.columns找到列名的列表,然後取出所需要的列
train_df = df[['Survived', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin_No',
'Cabin_Yes', 'Embarked_C', 'Embarked_Q', 'Embarked_S', 'Sex_female',
'Sex_male', 'Pclass_1', 'Pclass_2', 'Pclass_3']]
# 將DataFrame轉化成np.ndarray
train_np = train_df.values
# y即Survival的結果
y = train_np[:, 0]
# X即特徵值
X = train_np[:, 1:]
# 匯入線性模型中的邏輯迴歸模型
from sklearn.linear_model import LogisticRegression
# 定義邏輯迴歸分類器
clf = LogisticRegression()
# 擬合模型
clf.fit(X, y)
clf得到邏輯迴歸模型:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)接下來就是將測試集中的特徵資料匯入該模型進行預測了!首先,測試資料集需要和訓練資料集
進行一樣的預處理!
# 匯入測試集放入資料框中
data_test = pd.read_csv('test.csv')檢視基本資料資訊:

與訓練集不同的是,連續型數值變數包括Age和Fare,檢視Fare統計量:
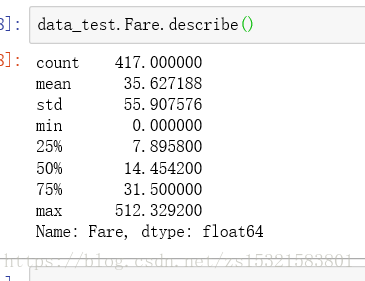
將Fare缺失的一項設定成中位數:
data_test.loc[data_test.Fare.isnull(), 'Fare'] = data_test.Fare.median()# 對測試集進行與訓練集相同的預處理
# 現在就可以看出編寫函式、建立模型的好處了:可以重複利用!
# 用訓練集訓練出來的隨機森林迴歸模型擬合填充缺失的年齡值
data_test.loc[data_test.Age.isnull(), 'Age'] = rfr.predict(data_test.loc[data_test.Age.isnull(),['Fare', 'Parch', 'SibSp', 'Pclass']].values)
# 用set_Cabin_type()來分類Cabin值
data_test = set_Cabin_type(data_test)
# 將分類變數因子化,即將一維分類變數變成多維啞變數
dummies_Cabin = pd.get_dummies(data_test.Cabin, prefix='Cabin')
dummies_Embarked = pd.get_dummies(data_test.Embarked, prefix='Embarked')
dummies_Sex = pd.get_dummies(data_test.Sex, prefix='Sex')
dummies_Pclass = pd.get_dummies(data_test.Pclass, prefix='Pclass')
# 橫向聯結並且橫向去除分類變數
df = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass],axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
# 縮放範圍明顯過大的特徵值
df.Age = preprocessing.scale(df.Age)
df.Fare = preprocessing.scale(df.Fare)在應用之前擬合出來的模型時,要特別注意測試特徵的排序要與訓練特徵的排序相同!
# 取出需要投入邏輯迴歸模型的預測特徵並轉為np.ndarray
test_df = df[['Age', 'SibSp', 'Parch', 'Fare', 'Cabin_No', 'Cabin_Yes',
'Embarked_C', 'Embarked_Q', 'Embarked_S', 'Sex_female', 'Sex_male',
'Pclass_1', 'Pclass_2', 'Pclass_3']]
test_np = test_df.values
# 預測
predicted_np = clf.predict(test_np)
# 將預測結果放入資料框,與passengerId對應起來,ID是唯一的,與訓練集也不能重複
# 注意:資料框中字典的內容應該是列表或是矩陣
# 獲救情況是整型,將預測結果astype(np.int32)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].values,'Survived':predicted_np.astype(np.int32)})# 將結果匯出到csv檔案,不帶索引
result.to_csv('predictions.csv', index=False)
在Kaggle上提交了結果,比上次的準確率提高了一個百分點,排在6K名,總參賽人數不到12K,也即是說我的結果還沒到50%,
沒關係,這只是一個baseline!
七 邏輯迴歸系統優化
7.1 模型係數關聯分析
我們使用的邏輯迴歸分類模型是線性分類模型,模型中隱含著一個成本函式,其形式是多
遠線性方程。模型確定的過程就是要使這個成本函式獲得最小值的各個特徵(也就是成本
函式的自變數)的係數的確定過程。這個方程的係數有什麼實際意義呢?如果係數為
正,該特徵與結果呈正相關,反之,呈負相關,越接近0,相關性越低。如果可以列出特徵和
其對應的係數,那麼我們就可以直觀的瞭解各特徵對結果的影響,這也是應用線性模型的好處
之一。
# 線性模型的係數是模型的屬性,是一個1*n的矩陣
# list()可以將多維資料變成一維,才可以做字典的內容
coefficients = pd.DataFrame({'columns':list(train_df.columns[1:]),'coef_':list(clf.coef_.T)})

7.2 交叉驗證
在實際訓練中,模型通常對訓練資料表現好,對非訓練資料擬合程度較差,通過將訓練集本身
隨機分成K份,相當於有了多對訓練集和測試集,同一個模型可以產生多個準確率,比較多個可能
的模型進行交叉驗證的結果的準確率方差後,可以比較各個模型的泛化能力。
K折交叉驗證:
from sklearn import model_selection
from sklearn import linear_model
# 將訓練集分成5份,4份用來訓練模型,1份用來預測,這樣就可以用不同的訓練集在一個模型中訓練# 定義邏輯迴歸分類器clf = linear_model.LogisticRegression()# 定義特徵集和結果集
X = train_df.values[:,1:]
y = train_df.values[:,0]
print(model_selection.cross_val_score(clf, X, y, cv=5))[0.81564246 0.81005587 0.79213483 0.78651685 0.81355932]7.3 學習曲線
有一個很可能發生的問題是,通過不斷的進行特徵工程,產生的特徵越來越多,用這些
特徵去訓練模型,會對我們的訓練集擬合的越來越好,同時也可能在喪失泛化能力,從
而在待預測的資料上,表現不佳,也就是發生過擬合現象。
從另一個角度上說,如果模型在待預測的資料上表現不佳,除掉上面說的過擬合問題,
也有可能是欠擬合,也就是說,即使在訓練集上也表現得不那麼好。
在機器學習問題上,對於過擬合和欠擬合兩種情形,我們優化的方式是不同的。
對於過擬合而言,通常以下策略對結果優化是有用的:
A 做一下特徵選擇,挑出較好的特徵的子集來做訓練
B 提供更多的資料,從而彌補原始資料的偏差問題,學習到的模型也會更準確。
而對於欠擬合,我們通常需要更多的特徵,更復雜的模型來提高準確度。
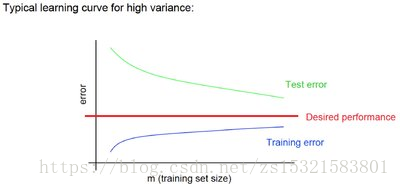
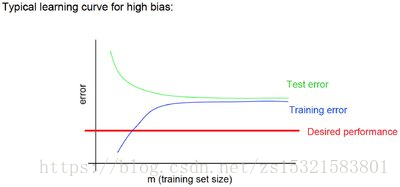
著名的學習曲線(learning curve)可以幫助我們判定我們的模型現在所處的狀態。我們以
樣本資料為橫座標,訓練和交叉驗證集上的錯誤率為縱座標,兩種狀態分別如下:
過擬合(overfitting/high variance):
欠擬合(underfitting/high bias):
畫出之前的baseline模型的learning curve:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib畫出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
畫出data在某模型上的learning curve.
引數解釋
----------
estimator : 你用的分類器。
title : 表格的標題。
X : 輸入的feature,numpy型別
y : 輸入的target vector
ylim : tuple格式的(ymin, ymax), 設定影象中縱座標的最低點和最高點
cv : 做cross-validation的時候,資料分成的份數,其中一份作為cv集,其餘n-1份作為training(預設為3份)
n_jobs : 並行的的任務數(預設1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"訓練樣本數")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"訓練集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉驗證集上得分")
plt.legend(loc="best")
plt.draw()
plt.show()
plt.gca().invert_yaxis()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
plot_learning_curve(clf, u"學習曲線", X, y)
八 模型融合(model ensemble)
模型融合的含義:當我們手頭上有一堆在同一份資料集上訓練得到的分類器(比如logistic regression,SVM,KNN,random forest,神經網路),那我們讓他們都分別去做判定,然後對結果做投票統計,取票數最多的結果為最後結果。
模型融合可以比較好地緩解,訓練過程中產生的過擬合問題,從而對於結果的準確度提升有一定的幫助。
首先,需要訓練出多個同時具有可用性的模型。
思路是可以應用多個演算法模型,或者是對同一個演算法模型用不同的資料集進行訓練(bagging)。
BaggingRegressor含義:
A Bagging regressor is an ensemble meta-estimator that fits base
regressors each on random subsets of the original dataset and then
aggregate their individual predictions (either by voting or by averaging)
to form a final prediction. Such a meta-estimator can typically be used as
a way to reduce the variance of a black-box estimator (e.g., a decision
tree), by introducing randomization into its construction procedure and
then making an ensemble out of it.
from sklearn.ensemble import BaggingRegressor
# fit到BaggingRegressor之中
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(X, y)
predictions = bagging_clf.predict(test_np)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].values, 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_bagging_predictions.csv", index=False)將模型融合後的結果再次上傳到kaggle中:

準確率沒有什麼進步!側面反映了原來的基線模型並沒有過擬合。
總結
本文中用機器學習解決問題的過程大概如下圖所示:

作者: 寒小陽
這已經是第二次認真學習這篇博文了,上一次是在接近兩個月以前,很多知識都不懂,很頭痛,而且沒有整理筆記。
這次相當於複習。這遍看起來輕鬆多了。不得不說複習和練習對於掌握技能太重要了!
這位作者的此篇博文內容非常豐富詳實,其中包含了一個完整資料探勘專案實現的大體思路、工具和技巧。
我這篇文章是為了加深理解,外加將自己學習過程中補充的其他知識或者心得整理記錄下來。