
Google File System及其繼任者Colossus
Google File System及其繼任者Colossus
在CMU 16Fall學期Storage Systems的課堂上,我有幸聽了在Google Infra Team的Larry Greenfield的一個Lecture。其中,Larry對GFS的設計初衷理念、優劣勢、瓶頸、改進以及現役系統Colossus (GFS2)進行了簡要介紹。其中涉及的內容相當寶貴,故在這裡記下。
背景
遙想谷歌創業之初,還是個規模不過數十人的小公司。他們手裡有Page Rank演算法,並打算將其實現為風靡全世界的搜尋引擎。既然要做搜尋引擎,第一步自然是用爬蟲爬取整個網際網路的網頁,並將其儲存、索引起來,這意味著巨大的儲存開銷。更為糟糕的是,這種規模的儲存量遠超單機或RAID陣列可以容納的最大值,所以,分散式儲存系統的使用呼之欲出。
由於初創公司的精力、成本等因素,谷歌決定摒棄傳統的使用大而高可靠性伺服器作為儲存節點的分散式檔案系統,轉而使用最便宜、能在當時市場以最高性價比買到的普通主機作為叢集成員。由於商業主機相較於高穩定伺服器在穩定性上存在數量級的差異,谷歌自主開發了一款具有高容錯性的分散式檔案系統:Google File System (GFS)。
無論在設計理念還是應用規模上,GFS都是劃時代的。不過,從現在看來,谷歌在當初的設計充滿了簡單粗暴。為了簡化系統,GFS僅適用於以下場景:
- 檔案系統中的檔案大(GB級及以上)而少
- 對檔案操作多為順序讀取、複寫或追加,幾乎沒有隨機訪問
該場景聽上去似乎十分荒謬——開啟我們身邊桌上型電腦或膝上型電腦的檔案瀏覽器,我們能看到鋪天蓋地的數KB~MB的小檔案;而無論是用Office編輯的文件還是被應用程式使用的臨時檔案,隨機訪問都佔據大半壁江山,這也是為何硬碟韌體設計者傾其所能將隨機訪問重新編排,使其儘量類似順序訪問而優化訪問效率。然而,如果我們關注於谷歌建立GFS的目的,一切又就非常合理了:每個分散式爬蟲開啟一個檔案並不停地將爬到的內容順序追加,索引器和Page Rank演算法不停順序讀取這些大檔案並吸收他們需要的資訊。正是GFS的應用場景和谷歌核心業務的高度匹配性,才讓這個實現粗糙的檔案系統成為谷歌所有資料的脊樑。
Google File System
(熟悉的讀者可直接空降下一章節:GFSv2: Colossus)
現在我們試著從頭開始體驗GFS的建立過程。首先需要確定的是,和任何其他檔案系統一樣,GFS將檔案分塊(Chunks)儲存,從而達到更好的追加效率。而谷歌面對著上千臺主機,需要確定一個方法將資料塊合理而均勻的散佈在主機上。在之前的日誌裡,我介紹了在叢集上從頭搭建雲端儲存系統的傻瓜教程,而其中最重要且精妙的一步是利用一致性雜湊(Consistent Hash)來分佈不同檔案。在那篇文章的儲存系統中,檔案和檔案的獨立無關的;而在谷歌將要搭建的檔案系統中,儲存基本單位(資料塊)之間是相關的,不幸的是,一致性雜湊並不能很好解決不同檔案協同操作的一致性和原子性問題,故不再適用於目前的情況。GFS則採用了一個更為簡單粗暴的辦法:不知道哪個資料塊在哪裡?專門用一臺機器全部記下來不就好了!
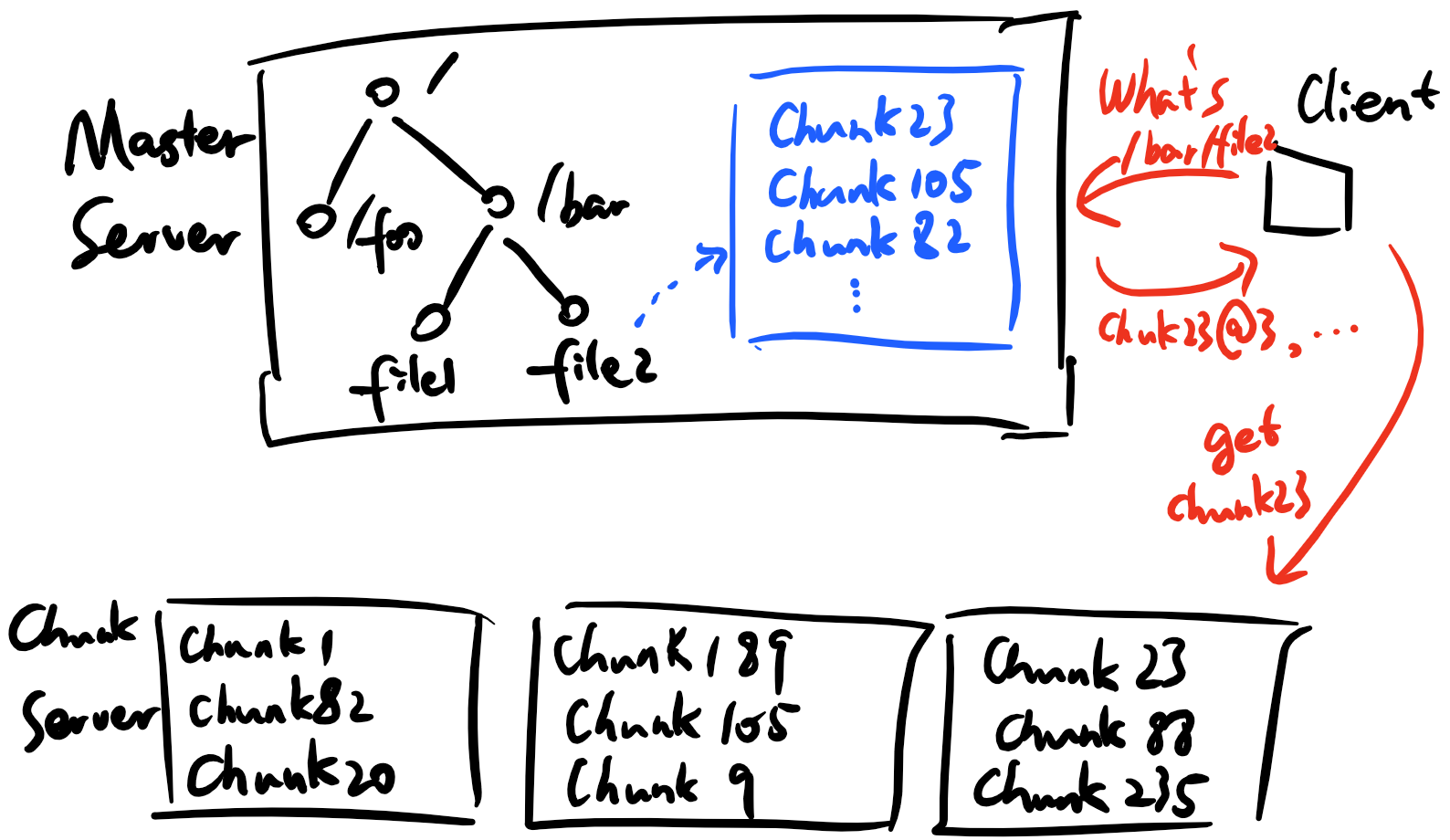
如上圖,一個GFS叢集由一個Master Server和大量Chunk Server組成,其中Chunk Server以大檔案的形式儲存檔案資料塊,每個資料塊由全域性唯一的id標識並作為該資料塊在本地檔案系統的檔名;Master Server儲存除了資料塊以外的所有資訊:檔案系統樹形結構、檔案和目錄的訪問許可權、每個檔案內容資料塊的ID列表,以及每個資料塊所在Chunk Server的位置。
該設計乍一看極不合理,似乎將所有重頭工作都交給Master進行。然而,考慮到上文適用場景中“檔案系統中的檔案大(GB級及以上)而少”的特點,Master儲存的有關檔案的資料量相當少。另外,由於客戶端每讀/寫一個數據塊都會聯絡Master Server至少一次,同時Master也需要維護每個資料塊的基本資訊,資料塊越少越能減輕Master節點的負擔——在實現中,GFS規定一個數據塊的大小為64MB,遠遠大於常規本地檔案系統4KB的資料塊尺寸,當然,相較應用場景中GB級的檔案大小,64MB依然顯得相當合適。在這裡我們再度看出,GFS正是完全針對特定應用場景而設計的檔案系統。
Master Server
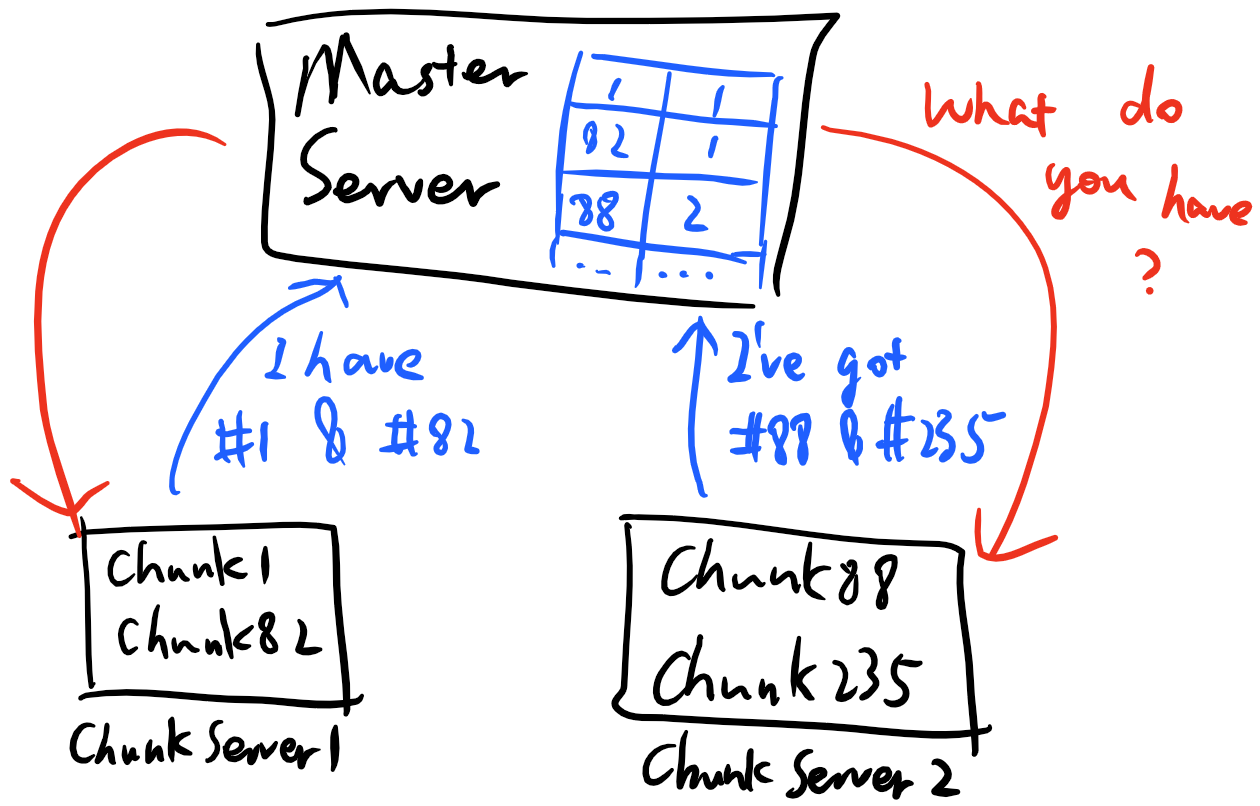
正是由於檔案數目極度有限、每個檔案也僅僅包含較小規模數量的64MB資料塊,Master Server需要儲存和維護的資料非常少,以至於被Master的記憶體全部容納還綽綽有餘。當然,對於檔案系統樹形結構、檔案和目錄的訪問許可權、每個檔案內容資料塊的ID列表等資料,由於僅由Master儲存唯一副本,Master會將其儲存在硬碟上,輔之一定的備份機制(如RAID、定期全盤備份等)以保證資料的萬無一失。但對於每個資料塊所在Chunk Server的位置資訊,Master並不會做任何措施將其永久儲存,相應的,Master會定期詢問所有Chunk Server其儲存的資料塊列表,並重建位置資訊對映表,如下圖所示:
在此架構下,常見的檔案目錄結構操作(新建目錄、改名、刪除)等均由Master完成。由於對這類資料負責的結點有且僅有一個,GFS在保證各類操作的原子性和資料一致性上有得天獨厚的效率優勢:無需複雜而昂貴的分散式事務或分散式副本管理演算法,僅依靠本地互斥鎖便可實現原子性的目錄結構修改。而這是基於一致性雜湊進行檔案劃分、建立偽檔案系統的OpenStack Swift至今也不能實現的。
Chunk Server
如前文所描述的,Chunk Server的職責僅僅在於儲存資料塊。(當然在實際系統中,Chunk Server還要負責在客戶端上傳檔案時確定資料塊儲存順序、選舉主副本等。本文將跳過這類細節,如想獲取更詳細的GFS實現,請參閱參考文獻[3]) 為了設計簡單,Chunk Server將資料塊以普通檔案的形式儲存於Linux的檔案系統中(如ext3)。當Server發起詢問時,Chunk Server會檢查自己儲存的所有資料塊檔名,(也許會檢查資料塊是否遭到損壞,)並將有效的資料塊名整理成列表回答給Server。
需要注意的是,Chunk Server並沒有自己實現任何複雜神奇的快取控制演算法,而僅僅利用OS的預設檔案快取進行有限的加速。該簡化設計不會對整個系統造成很大效能損耗,是由於適用場景中的檔案讀寫特徵決定了檔案訪問極弱的區域性性(順序讀寫+大資料塊)。這再次凸顯了GFS作為一個特定檔案系統與眾不同的地方,畢竟通用檔案系統無一例外的絞盡腦汁提出新穎精妙的快取演算法,就為了降低那麼一丟丟cache miss rate。
當錯誤來臨時 - GFS容錯性措施
前文我們提到,作為初創公司的谷歌採購了大量便宜但不可靠的商業主機作為GFS的硬體載體,這意味著各種形式的錯誤將是常見情況。這些錯誤包括但不限於:硬碟故障、宕機(CPU/記憶體故障)、網路故障、機房斷電、軟體bug,他們的影響範圍小到單個檔案、大到整個機房,錯誤後果輕則暫時無法響應任何請求、重則永久性丟失受影響的檔案。如何在這麼紛繁複雜的錯誤面前保證儲存在檔案系統的檔案不丟失,是GFS有別於之前檔案系統的最大特色。
在有關架構雲端儲存系統的日誌裡,我們提到了一個提高容錯性的基本策略:副本儲存(Replication)。該策略的原理非常簡單:即使因為錯誤丟失單個檔案的概率可觀,短時間內丟失多個副本的概率卻很低。只要我們的系統能夠在丟失一個副本時及時探測到損失並建立一個新的,丟失資料將幾乎不可能發生。具體在GFS的實現中,每個資料塊會被三臺Chunk Server儲存,在寫入資料時,資料會被同時寫到選定的三臺儲存結點的硬碟中;而當某一臺Chunk Server因為任何問題失去響應、從而無法提供資料塊時,Master會尋找正常執行並存有改資料塊副本的Chunk Server並著手將其複製到一臺新的節點上。
上述流程的問題在於,Master如何探測到一個Chunk Server失去響應、或因為任何原因丟失/損壞了某個資料塊呢?我們在前文已經給出了答案:定期詢問。定期詢問既能讓Master的Chunk ID-Chunk Server對映表保持更新,又能幫助Master及時意識到資料塊的丟失,從而啟動恢復流程。
以上提到的副本儲存、恢復策略很好的消弭了Chunk Server出錯時對整個系統帶來的影響。那麼假如Master Server出錯了又將如何?
Master Server作為整個系統的Single Point of Failure,一旦出錯對整個系統帶來的影響遠比上文所述嚴重:因為Master參與絕大部分操作,Master未響應意味著這些操作均不能完成。另外,僅存在一份副本的檔案系統元資料也會因為Master的損壞而永久丟失,而元資料一旦丟失,及時所有資料塊都存在,整個檔案系統也完全無法恢復。針對第一個問題,谷歌採用了Standby Server作為解決方案:即,設立其他伺服器並模仿Master的一舉一動,一旦Master失去響應,Standby Server充當新的Master節點。而對於第二個問題,大量傳統資料備份方案(RAID/線上備份/離線備份)會很好的解決這一點。由於Master Server畢竟佔少數,為了保證其高可靠性而採用更昂貴的措施並不會對總體開銷帶來太大額外提升。
神祕的繼任者 - GFSv2: Colossus
GFS的簡單架構介紹已經結束了,但所有人都總多少有點不盡興的感覺:畢竟GFS是一個初創公司為了節約陳本、節省時間做的一個粗糙系統,雖然在之後的日子隨著Google的壯大幾經演化,但一些結構上的不完美始終讓人耿耿於懷:中心化的Master讓整個系統始終被Single Point of Failure的陰霾籠罩;有限的檔案數目和資料塊數目限制了整個檔案系統的尺寸;而更為關鍵的是,隨著Google的各項業務逐漸完善,在設計GFS時所設立的適用場景正在逐漸瓦解,大量較小而多的檔案需求開始出現。這一切都預示著谷歌即將做出改變。
在這之前,學術界已經做了相當多相關探索。USENIX FAST每年都會出現大量分散式檔案系統的論文,其中不乏以GFS為原型,想方設法做出分散式Master Server架構、支援大目錄、多檔案等的原型系統。遺憾的是,這些檔案系統均沒有在工業界得到廣泛應用。而在開源界,大名鼎鼎的Hadoop專案下有GFS的開源實現HDFS,其從誕生至今都一直被各大公司開發、使用,雖幾經演化已與當年的GFS差距甚大,HDFS在總體架構上始終沒有重大變更,從而依然受到GFS固有缺陷的困擾。
大概從2010年起,Google用全新架構的檔案系統替換了GFS,新系統擁有分散式元資料管理、4MB的資料塊和理論上無限大的目錄規模支援:妥妥的官方逼死同人系列。讓人感嘆的是,Google對來頭如此大的新系統的架構和實現隻字不提,對外公開的僅有其令人難以捉摸的名字——Colossus。
如序言所言,由於CMU 15746 Guest Lecture,我有幸地聽從Larry Greenfield講述了並不對外公開(事實上展示用幻燈片對我們也是不開放的)的Colossus架構。由於課後手上沒有任何可供參考和回憶的資料,以下內容僅供參考,且嚴禁轉載或用於其他用途。
重構系統從改名字做起
當然這是句玩笑話(對微軟這似乎不是玩笑?) 不過在講述GFSv2之前,我們有必要理清一下新系統中的若干元件以及其與GFS相關元件的對應關係:
- Colossus File System:該系統名字的又來,本質上僅僅是分散式元資料管理子系統,但也是整個新系統的核心。對應原系統的Master Server。
- D Server:資料塊儲存伺服器,對應原系統的Chunk Server。其在具體資料塊儲存和管理方式上的改進未知,且非重點,此處不做詳細展開。
分散式Master Server: CFS
在新一代檔案系統中,最大變化、也最令人矚目的莫過於分散式元資料管理節點的實現。在CFS的實現上,谷歌向我們完美地展示瞭如何將新問題(不擇手段地)轉化為已有問題,並將架構上的暴力美學體現得淋漓盡致。
擴充套件元資料管理節點的第一步,是將原有的單節點樹形檔案系統結構儲存方式改為基於key-value store的鍵值儲存,具體原理類似於OpenStack Swift。但CFS如何在將語義上的樹形檔案系統結構實現為鍵值儲存的同時還保證相應操作的原子性,我們不得而知。所幸的是,我們也許可以在學術界找到一些線索:例如,TableFS就提出了一種方式來將檔案系統元資料表示為k-v資料表;而我在開源專案H2Cloud也利用了相似的方法在OpenStack Swift的鍵值物件儲存上建立了完整語義的檔案系統。
總之,Google將檔案系統元資料表示為了一個表。而對於一張資料表,Google有非常成熟的方法來分散式處理之:BigTable。關於BigTable的實現細節我在此處不多做描述,有興趣的讀者可以參考其開源實現Apache HBase。Google BigTable能在分散式叢集上維護一個key-value store的資料庫並提供極高的讀寫效能。通過將檔案元資料維護在BigTable上,CFS成功實現了分散式擴充套件。
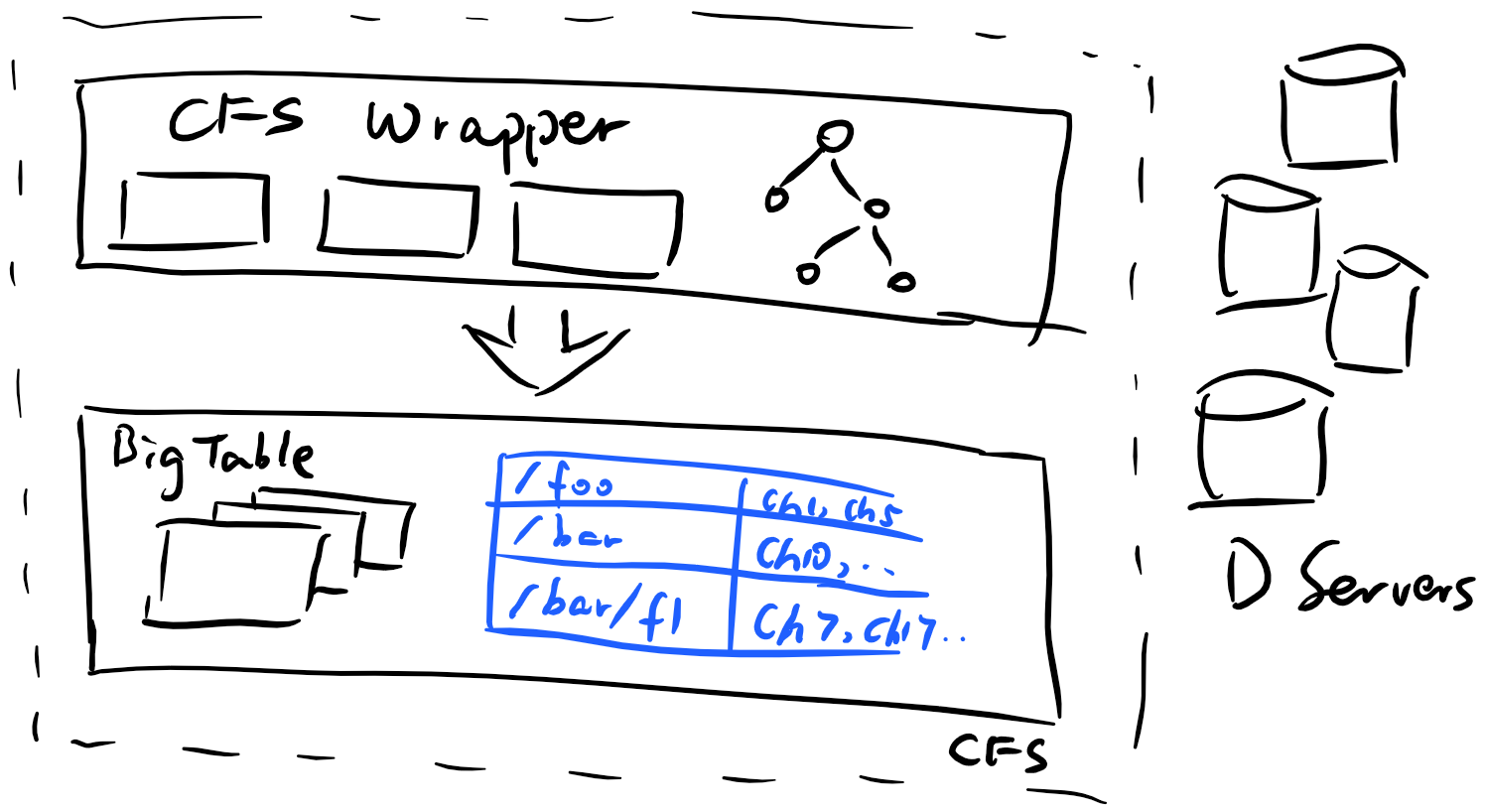
事情當然沒有這麼簡單,熟悉BigTable的讀者應該能夠反應過來,BigTable資料庫是依託GFS建立的,而這似乎形成了死結:擴充套件GFS需要依靠BigTable,而BigTable建立在GFS上。事實上事情並非如此:由於CFS儲存的元資料相較整個檔案系統非常小(大約萬分之一),一個可擴充套件性不那麼強的GFS也能夠勝任將其存下的工作。因此,Colossus通過將元資料儲存在GFS上的方式實現了比GFS大若干數量級的擴充套件水平。
當然,Google不會就此滿足。畢竟一次系統重構代價極高,若不能一次將可擴充套件性做足,勢必在不久的將來面臨再次重構的困境。既然較小的Colossus的元資料能夠存在GFS,那麼更大的Colossus元資料是否能存在一個較小的Colossus上呢?
根據這個思路一直想下去:100PB資料的元資料大約10TB,10TB資料的元資料大約1GB,1GB資料的元資料大約100KB。經過這幾層壓縮,資料量已經小到能夠放進極小規模的分散式系統甚至單機上了!
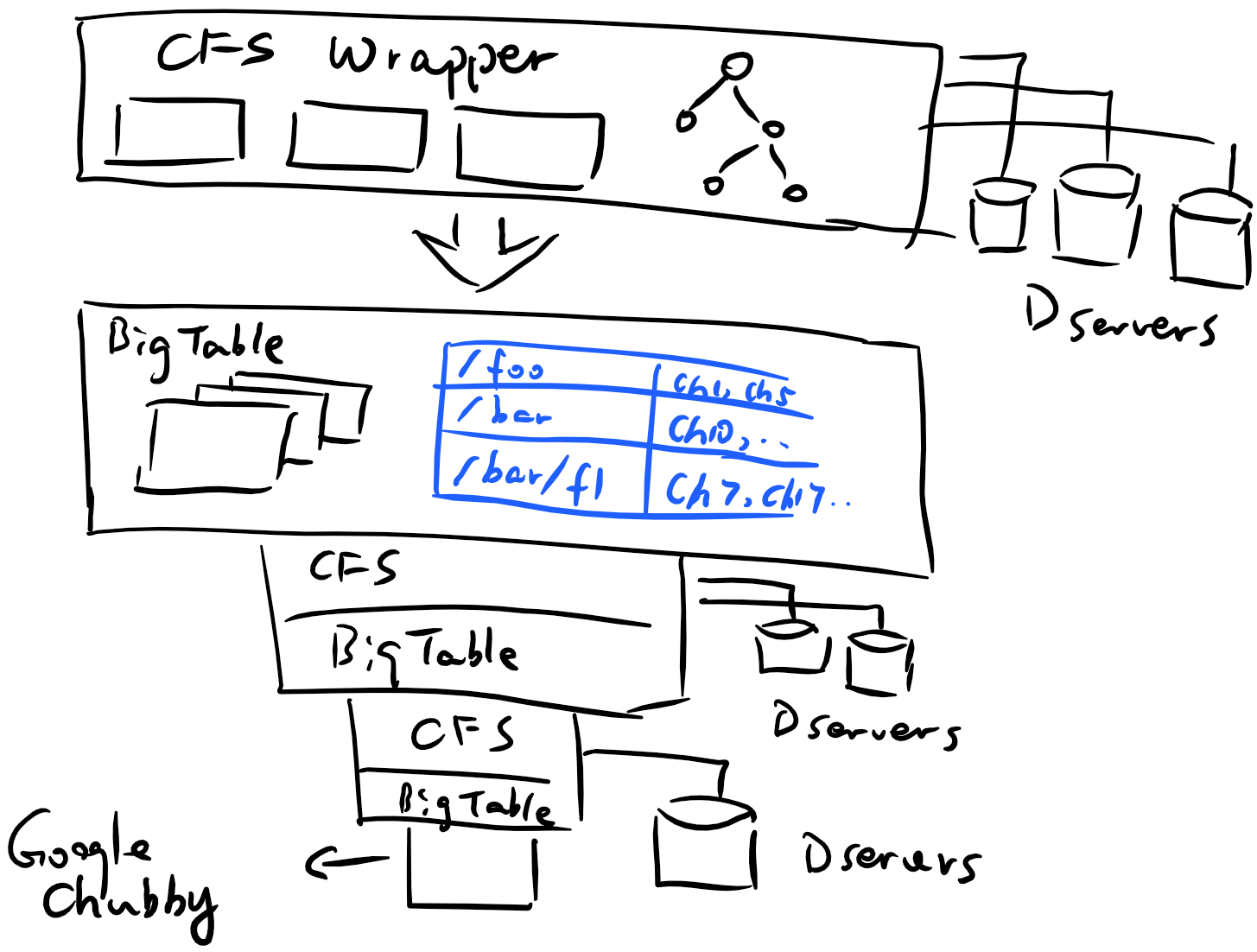
是的,這就是CFS的架構。跟我念一遍:Colossus是一個通過將元資料儲存在一個將元資料儲存在另一個將元資料儲存在Google Chubby(分散式鎖管理系統,也可理解為一個小型強一致性檔案系統)上的檔案系統上的檔案系統而獲得高可擴充套件性的分散式檔案系統。
這一套充斥著糙快猛的哲學和暴力美學的系統架構方式實在是重新整理了我的三觀。對此讀者(包括我)第一個問題很可能是:既然說Master Server是GFS的Single Point of Failure,那麼Colossus中最下層的Chubby豈不是Single Point of Single Point of Single Point of Failure,只要Chubby小叢集中的過半節點無法響應,整個巨大的Colossus檔案系統也就隨之崩壞了不是麼?
為了解答這個問題,我們需要對Google Big Table (亦或是Apache HBase)的基本原理有一定了解。Big Table最大的特性之一是採用了LSM樹固化所有修改,LSM樹將一切修改轉化為追加日誌的形式,這意味著在這種資料結構中,隨機寫操作幾乎不存在。而對於GFS/Colossus,順序寫操作僅在需要新建立資料塊的時候聯絡Master/CFS,其餘時候只需和Chunk Server/D Server做資料交換;同時,LSM樹在上層的修改合併會讓建立資料塊的操作變得更加不頻繁,從而進一步降低Big Table聯絡Master的頻率。該特性導致的直接結果是,即使Master/CFS整體失去響應,其上的Big Table仍然能夠正常讀寫相當長一段時間。根據前文提到的每層CFS對資料量的壓縮率,越向下層的BigTable/CFS,訪問頻率越是以上萬倍的速度衰減。因此,即使Chubby整體宕機,整個Colossus叢集依然能執行極長時間,而這個時間差對於Google檢測到Chubby失敗而採取回覆措施已經綽綽有餘。
其他改動
除了總體架構上的改動,Colossus還在其他若干方面做出了和老系統不同的決定:
- 資料容錯不再使用副本,轉而使用更復雜的Reed-Solomon編碼。類似於RAID-6,Reed-Solomon允許被編在同一組的4個數據塊最多丟失兩個。這樣的編碼能在不對資料丟失概率做出太多負面影響的情況下減小儲存開銷,而付出的代價則是更復雜的系統和更高的計算量。
- D Server採用更激進的快取策略,同時客戶端也採用更高併發度的方式獲取資料塊,其目的在於減少tail-latency,即最慢訪問延遲,讓”最糟糕的情況不那麼糟“。
總之,由於缺乏學術論文,Colossus的設計詳情和表現效能至今不被外人所知,Larry's Lecture也只是揭開了龐大複雜的新系統的冰山一角。儘管新系統看起來簡單粗暴,但作為系統設計者最應該清楚,一個能夠實際投入使用的系統從來都不像看上去那麼簡單——對於Colossus如此,對於GFS亦如此。正是因為實現難度遠大於設計難度,進行系統設計時才需要遵循"Simple is vital"這條黃金準則。
希望這片小博文能對讀者有所啟發。由於我學識甚淺,有任何錯誤希望大家不吝指正。
參考文獻
- CMU 15746 Storage Systems Lecture Slides, Greg Ganger and Garth Gibson
- Evolution of Google FS, Larry Green Field, 2016 (15746 Fall Guest Lecture)
- Ghemawat, Sanjay, Howard Gobioff, and Shun-Tak Leung. "The Google file system." ACM SIGOPS operating systems review. Vol. 37. No. 5. ACM, 2003.
- Ren, Kai, and Garth A. Gibson. "TABLEFS: Enhancing Metadata Efficiency in the Local File System." USENIX Annual Technical Conference. 2013.
Tags: 雲端儲存, 分散式系統, Google, 分散式檔案系統