
更加深入剖析Kafka--Producer篇(上)
背景
Kafka誕生於Linkedin,以可靠性和巨量吞吐著稱,網上清一色將它歸為訊息佇列,使用者可以按主題釋出及訂閱流經Kafka的資料,從這角度看它確實是訊息佇列,但這僅僅是它的一個方面,在這之上它首先是流式資料傳輸管道。
管道對實時分析的價值是巨大的,首先它是實時分析系統的天然緩衝屏障,可以通過固定的消費頻率避免被突如其來的流量峰值擊垮;其次它架起了業務系統到分析系統的資料路徑,也將分析和業務兩個系統在一定程度上解耦。僅從資料角度看,管道成了分析系統的入口。
為什麼是更深入
經過我過人的”視野“洞察後,我決定踢開”百撕不得其姐“的Spark,改從入口的Kafka突破。小卡也的確很貼心,Producer端完全java化了,我也逐漸了適應了Idea煩人的快捷鍵和介面,看起原始碼來開始得心應手。其實一開始我也沒打算看原始碼,買了本厚厚的書,期待它能像《深度理解Java虛擬機器》一樣開啟我的智慧,結果它光只貼原始碼了,我一直認為真正的懂是撇開程式碼能講清楚一件事,所以決定還是一行行的閱讀程式碼,然後儘可能分析得比書更深入,所以就叫《更加深入剖析Kafka》,這一週會陸續補完生產者篇。
資料整合
資料整合從領域/系統整合角度看很類似早期的資料庫表介面,有過這種經歷的都會明白其中的痛苦,suffer a lot,這也是為什麼業界在反思後更多主張依賴抽象的介面整合方式。理論上對任何事物做抽象後都是資料,所以資料整合架構可以解決任何事情,但這種解決是建立在人對資料有所定義上,當資料的生產和消費不是一個人時就很容易出現問題。
訊息系統也有類似問題,如果由源系統定義訊息結構,訊息的任何變動就需要充分評估,這就像回到了關係整合的時代,要改表尤其修改某個欄位語義變得幾乎不可能,先召集大家開會,再製定改動方案,而往往是即使做了充分的事前評估,落地時還是一堆問題,幾乎永遠評估不到這份資料的使用全貌。因此往往源系統定義的訊息都會欄位超多,因為只能加欄位而無法改和刪。如果在協作上由下游系統定義訊息結構,它就會更類似是個抽象介面,但在下游系統很多且共通性很小時這也變得幾乎不可能。所以訊息只能帶來鬆耦合而無法換來高內聚,源系統開發一定會是想拿刀捅死膽敢要求修改訊息結構的那群人,呲牙瞠目的喊“How dare u,fucker”
我不是反對訊息以及資料整合,只是反思這種方式,也不主張介面萬歲,沒有一種整合方式是萬能的。整合方式應該基於團隊協作方式制定,比如提供web服務那肯定是介面比訊息更適合。
地圖
我喜歡摳程式碼細節會比較囉嗦,所以光生產者篇就會很長。我覺得架構設計就是細節,系統設計撇開細節只談願景是無意義的。比如Spring Ioc,原型上很簡單,不就是個反射嗎,很多人也跟我這麼說過,但是深入到細節裡就會發現其擴充套件性之優秀、配置可描述性之完備以及場景豐富度支撐之多等都是看到後會真心發出”挖草“的。Kafka也是這樣的優秀中介軟體,很多細節處理得都特別精妙,簡直就是極盡所能在榨乾工程師智慧獲得性能和穩定性上的一點一點提升。
概念
Broker,Server,Producer和Consumer是Kafka的四個關鍵概念,每個中介軟體都有自己特有的一套術語命名方式,用大白話講它們分別就是節點、服務端、訊息生產者和訊息消費者。
生產者
生產者泛指一切訊息源,KafkaProducer並不是Kafka的生產者實現,而是提供給生產者使用的程式設計API。生產者使用KafkaProducer.send實際只是將訊息暫存至待發送批次,而在此之前它會依次被過濾、序列化和分割槽。
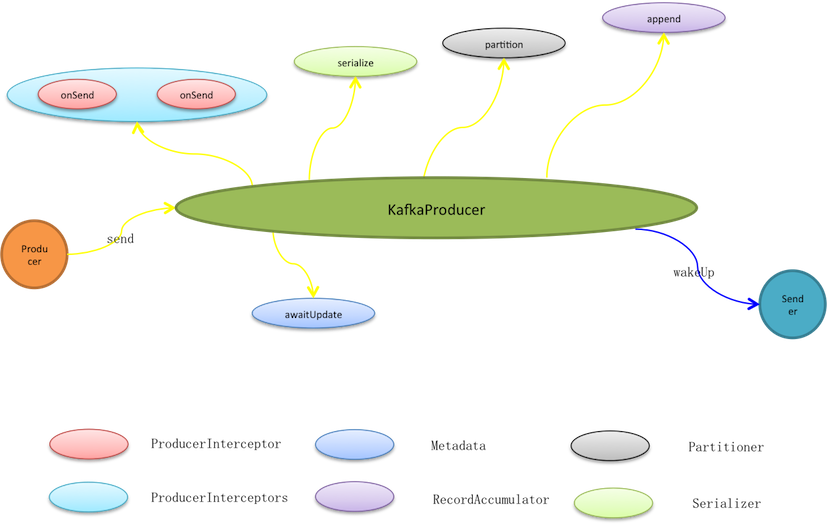
* 過濾是鏈式動作,通過interceptor.classes可以指定多個ProducerInterceptor型別的過濾器,按預定義順序它們被編排入過濾鏈(ProducerInterceptors)。訊息傳送、異常以及ack動作都會觸發過濾鏈的相應過濾動作,過濾器再根據編排順序被依次呼叫。訊息傳送就會先過濾再處理,過濾器可以修改訊息內容,但無法終止訊息傳送甚至無法中斷過濾鏈,因為過濾鏈catch所有異常且不丟擲只log記錄。
* 訊息被傳輸之前是暫存在預分配的ByteBuffer上,因此需要將訊息序列化成Byte陣列。KafkaProducer按照使用者預定義的key.serializer和value.serializer序列化方式進行序列化,將鍵和值都轉成Byte陣列。
傳送者
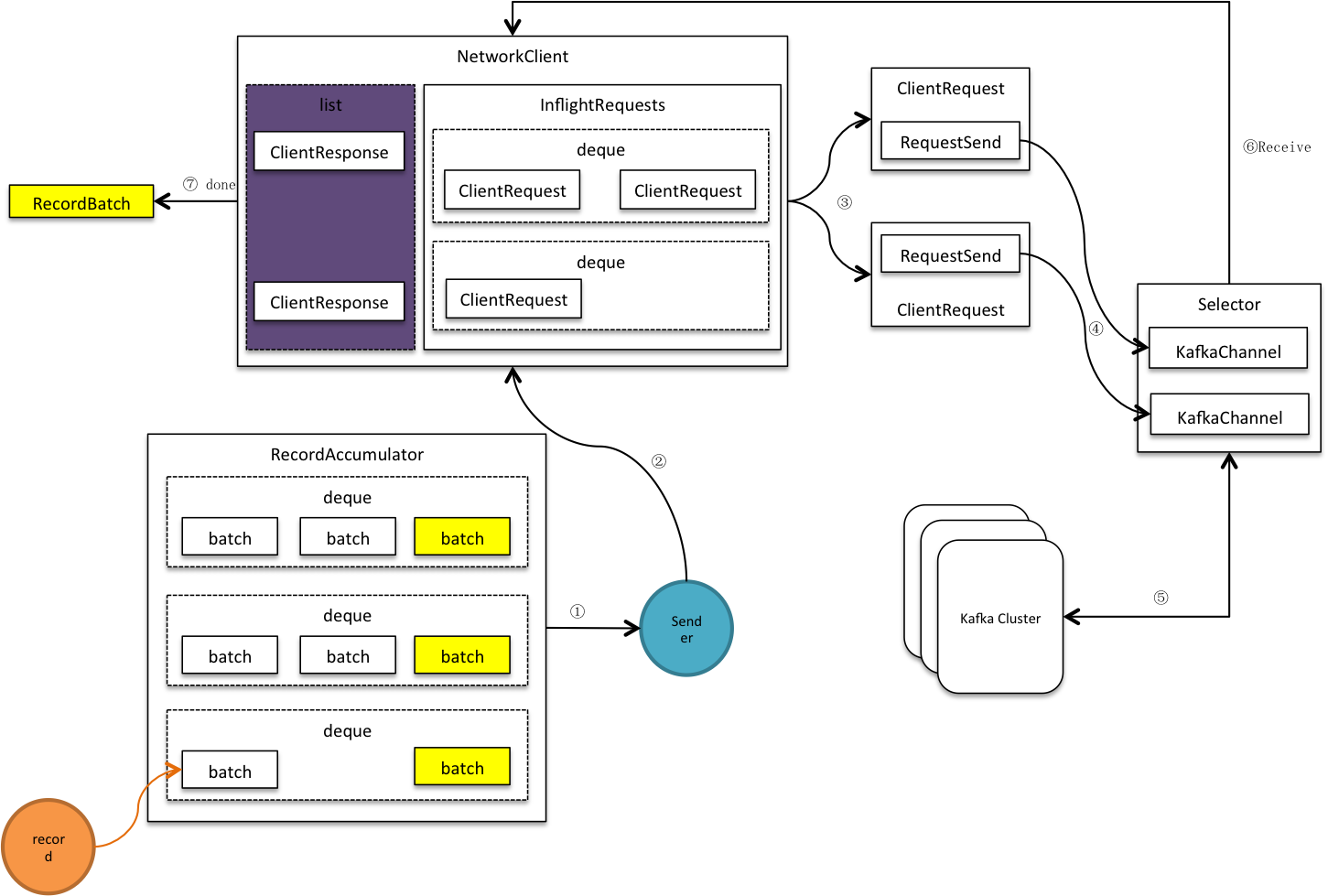
傳送者是個守護執行緒,它1)收集可傳送批次,將傳送到相同節點的多個批次合併到同個請求,這些請求被放入<處理中請求(InFlightRequests)>,接著再寫進網路通道。2)客戶端開始網路輪詢,傳送通道中的緩衝資料,同時接收服務端應答資料。3)移除InFlightRequests中的完成請求,並進行客戶端響應,關閉相關批次,釋放批次所佔記憶體。
叢集
叢集是對完整能力的縱向切分,目標是將流量均攤而且能水平擴充套件。Kafka在縱向以外又對叢集橫向切分。兩個維度的交叉切分形成網格化的精細布局,資料被填入網格中,使讀寫甚至清理都效率很多,同時還能有效避免Hadoop的單點困境,領袖網格在各個節點均勻分佈,流量也相應被切分平攤。
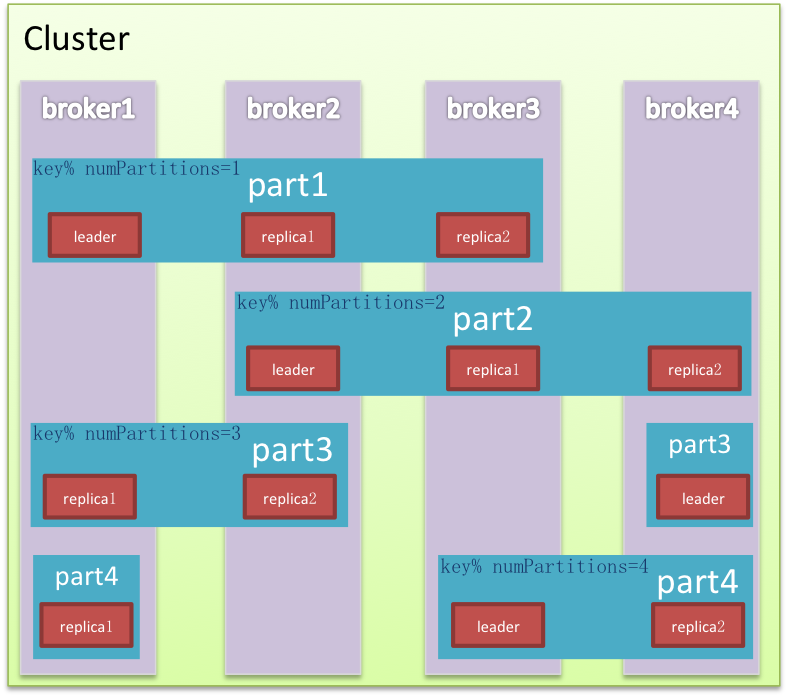
節點Node是叢集的物理組成單元,也是垂直切分後的計算單元。Kafka除極少數以外的服務能力均由領袖提供,是非典型中心化叢集,因為Kafka會盡量保證領袖的均勻分佈,這樣中心流量就被均勻打散。
分割槽是邏輯儲存單元,是水平切分的產物,資料相對均勻的分散在各個分割槽,磁碟I/O處理效率也會因此大大提升。同時為保證叢集高可用,分割槽內節點以及角色也是相對動態的,Kafka在分割槽內做冗餘備份有多份Replica,在leader/follower故障的情況下自動做備援轉移到可用節點。
元資料
節點、分割槽以及領袖、備份的分佈等叢集拓撲資訊被稱為元資料Metadata,元資料會動態變化,例如單點Broker故障,又或者使用Admin刪除topic,…… ,因此客戶端需要不斷更新以及時感知這些變化。
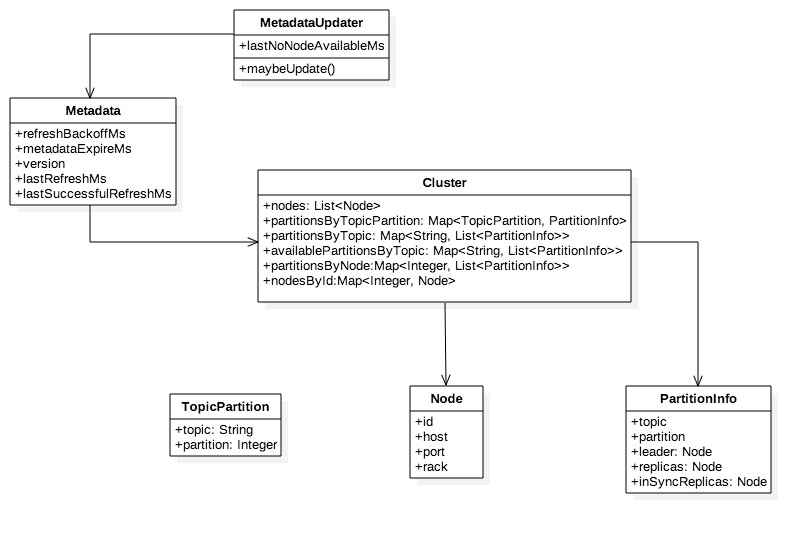
+ MetadataUpdater是重新整理元資料的外觀類,是KafkaClient組成部分,它嘗試發起元資料更新,如果滿足更新條件則立即發起更新請求。
+ Metadata的refreshBackoffMs和metadataExpireMs分別代表重新整理週期和失效延時,lastRefreshMs和lastSuccessfulRefreshMs則分別代表上次重新整理時間和上次成功重新整理時間,注意二者區別,前者只要發生update就會被記錄無關成功與否。version代表元資料版本,每次成功更新預設加1。
+ Cluster是客戶端維護的叢集拓撲結構,可以進行多維查詢,在元資料更新成功後會被覆蓋。
+ 分割槽資訊(PartitionInfo)中的inSyncReplicas即ISR是指在同步狀態的副本,其他屬性都比較直觀不做過多說明,。
元資料更新
每個topic都是一個二維拓撲結構,對映到具體的節點和分割槽;叢集容納多個topic,因此叢集拓撲結構是三維的,對映到具體topic加節點加分割槽。更新實質就是拉取服務端的相關topics的拓撲資訊,因此每次更新都需要指定感興趣的topics。
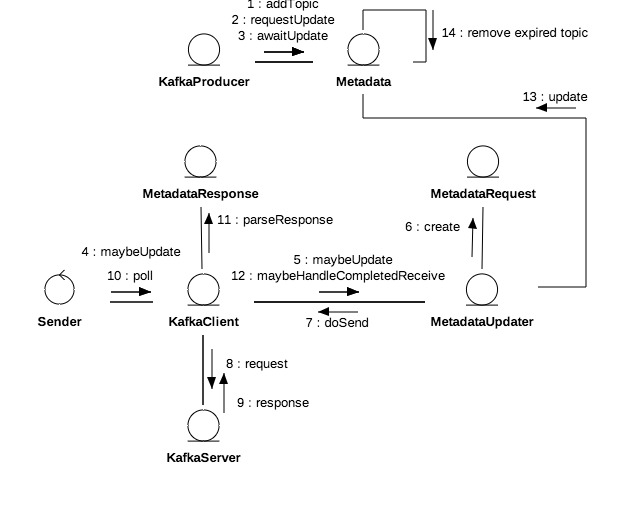
元資料更新是週期性的,客戶端每次輪詢網路都會先嚐試更新元資料。MetadataUpdater是客戶端的元資料更新元件,它會綜合元資料更新延時和重連延時判定是否需要發起更新,其公式為A=Max(元資料更新延時,重連延時)。如果A>0或者有元資料獲取正在進行中不進行更新。
1. 元資料更新延時=Max(失效時間, 更新時間),
+ 更新時間=上次重新整理時間+重新整理週期(retry.backoff.ms)-當前時間。
+ 失效時間=上次成功重新整理時間+失效延時(metadata.max.age.ms)-當前時間,如果元資料被標記為強制更新(needUpdate),則立即失效。
2. 重連延時=無可用節點發生時間+重試周期-now。
3. 元資料獲取是指請求已傳送但結果還未返回,正在等待結果獲取中。
生產者每次傳送訊息前都會強制元資料更新,它標記元資料需要更新並阻塞等待直至超時或更新成功。但這並不意味每一筆訊息都產生一次網路更新請求,參考以上更新發起條件,即使標記需要更新在更新週期以外也不會發生更新,因此同一更新週期內的多次更新會堵塞等待同一筆更新成功。
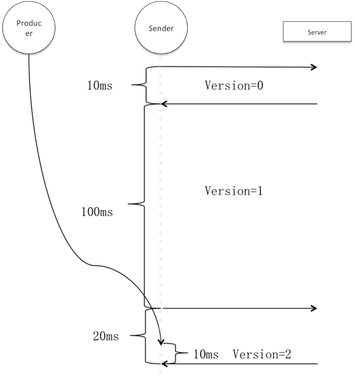
上圖假設重新整理週期是100ms,並且在第一次和第二次輪詢期間無更新請求。生產者的請求在階段3進來,此時元資料輪詢請求已經發出,因此使用者執行緒實際只阻塞了10ms。假設階段3有多個使用者執行緒,則平均等待時間應為<重新整理週期+更新請求時間/2>。
服務端的任意節點而非僅領袖節點都有完整的拓撲結構,為了獲得最快的響應速度客戶端只需請求負載最小的可用節點。負載的依據是客戶端自己發出的到每個節點處理中請求數,即inFlightRequests大小,所以其並不代表絕對意義上的最小負載。如無可用節點,客戶端會記錄下無可用節點時間lastNoNodeAvailableMs。
選出的節點若是斷開狀態但可進行重試(距離最近建立連線的時間超過reconnect.backoff.ms),則立即初始化連線。因為Non-blocking I/O建立連線不一定立即成功,所以不能立即傳送更新請求而是延到之後的執行週期。
客戶端收到服務端更新應答後對元資料更新,更新會做兩件事情:淘汰過期(預設5分鐘)topic和覆蓋客戶端拓撲結構。如果發生網路異常比如建立連線失敗、連線斷開以及連線超時,直接標記元資料需要更新,因為此時有可能是服務端拓撲結構發生變化。但這種情況更新不需要重新指定topic,因為發生連線問題不會有服務端響應則更不會有元資料更新。