
python 計算機發展歷史,初識併發
########################總結##################
#一 作業系統的作用:
1:隱藏醜陋複雜的硬體介面,提供良好的抽象介面
2:管理、排程程序,並且將多個程序對硬體的競爭變得有序
#二 多道技術:
1.產生背景:針對單核,實現併發
ps:
現在的主機一般是多核,那麼每個核都會利用多道技術
有4個cpu,運行於cpu1的某個程式遇到io阻塞,會等到io結束再重新排程,會被排程到4個
cpu中的任意一個,具體由作業系統排程演算法決定。
2.空間上的複用:如記憶體中同時有多道互相獨立的程式
3.時間上的複用:複用一個cpu的時間片
強調:遇到io切,佔用cpu時間過長也切,核心在於切之前將程序的狀態儲存下來,這樣
才能保證下次切換回來時,能基於上次切走的位置繼續執行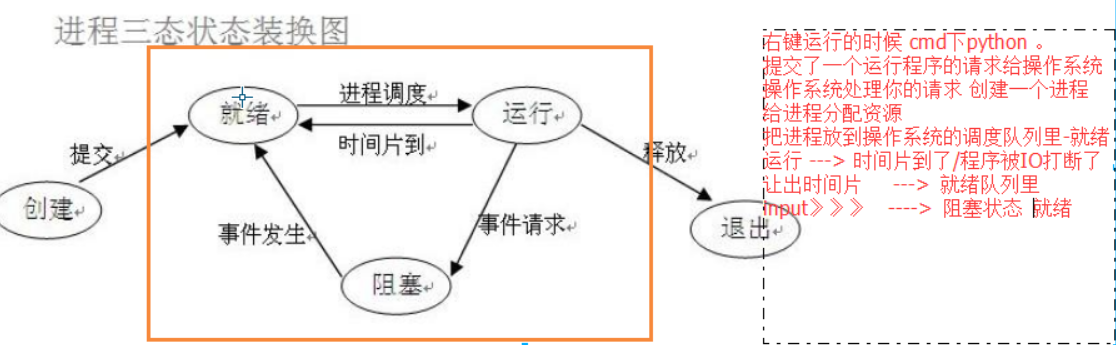
(1)就緒(Ready)狀態
當程序已分配到除CPU以外的所有必要的資源,只要獲得處理機便可立即執行,這時的程序狀態稱為就緒狀態。
(2)執行/執行(Running)狀態當程序已獲得處理機,其程式正在處理機上執行,此時的程序狀態稱為執行狀態。
(3)阻塞(Blocked)狀態正在執行的程序,由於等待某個事件發生而無法執行時,便放棄處理機而處於阻塞狀態。引起程序阻塞的事件可有多種,例如,等待I/O完成、申請緩衝區不能滿足、等待信件(訊號)等。

同步和非同步
所謂同步就是一個任務的完成需要依賴另外一個任務時,只有等待被依賴的任務完成後,依賴的任務才能算完成,這是一種可靠的任務序列
所謂非同步是不需要等待被依賴的任務完成,只是通知被依賴的任務要完成什麼工作,依賴的任務也立即執行,只要自己完成了整個任務就算完成了。至於被依賴的任務最終是否真正完成,依賴它的任務無法確定,所以它是不可靠的任務序列。
第一種 :選擇排隊等候;
第二種 :選擇取一個小紙條上面有我的號碼,等到排到我這一號時由櫃檯的人通知我輪到我去辦理業務了;
阻塞與非阻塞
繼續上面的那個例子,不論是排隊還是使用號碼等待通知,如果在這個等待的過程中,等待者除了等待訊息通知之外不能做其它的事情,那麼該機制就是阻塞的,表現在程式中,也就是該程式一直阻塞在該函式呼叫處不能繼續往下執行。
相反,有的人喜歡在銀行辦理這些業務的時候一邊打打電話發發簡訊一邊等待,這樣的狀態就是非阻塞的,因為他(等待者)沒有阻塞在這個訊息通知上,而是一邊做自己的事情一邊等待
- 同步阻塞形式
效率最低。拿上面的例子來說,就是你專心排隊,什麼別的事都不做。
- 非同步阻塞形式
如果在銀行等待辦理業務的人採用的是非同步的方式去等待訊息被觸發(通知),也就是領了一張小紙條,假如在這段時間裡他不能離開銀行做其它的事情,那麼很顯然,這個人被阻塞在了這個等待的操作上面;
非同步操作是可以被阻塞住的,只不過它不是在處理訊息時阻塞,而是在等待訊息通知時被阻塞。
- 同步非阻塞形式
實際上是效率低下的。
想象一下你一邊打著電話一邊還需要擡頭看到底隊伍排到你了沒有,如果把打電話和觀察排隊的位置看成是程式的兩個操作的話,這個程式需要在這兩種不同的行為之間來回的切換,效率可想而知是低下的。
- 非同步非阻塞形式
效率更高,
因為打電話是你(等待者)的事情,而通知你則是櫃檯(訊息觸發機制)的事情,程式沒有在兩種不同的操作中來回切換。
比如說,這個人突然發覺自己煙癮犯了,需要出去抽根菸,於是他告訴大堂經理說,排到我這個號碼的時候麻煩到外面通知我一下,那麼他就沒有被阻塞在這個等待的操作上面,自然這個就是非同步+非阻塞的方式了。
很多人會把同步和阻塞混淆,是因為很多時候同步操作會以阻塞的形式表現出來,同樣的,很多人也會把非同步和非阻塞混淆,因為非同步操作一般都不會在真正的IO操作處被阻塞。
模組的使用
import time from multiprocessing import Process #mou t p ruang sai seng
def f1(): time.sleep(3) print('111111') def f2(): time.sleep(3) print('222222') if __name__=='__main__': p1=Process(target=f1,) p2=Process(target=f2,) p1.start() p2.start()
###################
222222
111111
for 迴圈建立程序
import time from multiprocessing import Process def f1(i): time.sleep(2) print(i) if __name__ == '__main__': for i in range(20): p1=Process(target=f1,args=(i,)) p1.start()
####################
1
2
0
6
10
7
4
12
5
16
8
18
9
17
15
13
11
14
3
19
程序(傳參方法)和建立方式
##方法一 from multiprocessing import Process #演示兩種傳參方式 def f1(n): print(n) if __name__=='__main__': # p1=Process(target=f1,args=('大力出奇跡')) p1 = Process(target=f1, kwargs={'n': '大力'}) # 建立程序物件 p1.start()#給作業系統傳送了一個建立程序的訊號,後續程序的建立都是作業系統的事兒了
###############
大力
#程序的建立方式2 class MyProcess(Process): def __init__(self,n): super().__init__() #別忘了執行父類的init self.n = n def run(self): print('寶寶and%s不可告人的事情'%self.n) if __name__ == '__main__': p1 = MyProcess('高望') p1.start()
##################
寶寶and高望不可告人的事情
join 方法
import time from multiprocessing import Process def f1(): time.sleep(2) print('111111111') def f2(): time.sleep(2) print('22222222') if __name__ == '__main__': p1=Process(target=f1,) p1.start() p1.join()#主程序等子程序執行完成才能執行 print('開始p2拉') p2 = Process(target=f2,) p2.start() p2.join() print('我要等了...等我的子程序...') print('我是主程序!!!')
######################
111111111
開始p2拉
22222222
我要等了...等我的子程序...
我是主程序!!!
__main__
#windows系統下必須寫main,因為windows系統建立子程序的方式決定的,開啟一個子程序,這個子程序 會copy一份主程序的所有程式碼,並且機制類似於import引入,這樣就容易導致引入程式碼的時候,被引入的程式碼中的可執行程式被執行,導致遞迴開始程序,會報錯 if __name__ == '__main__': # # p1 = Process(target=f1,) p2 = Process(target=f2,) # p1.start() p2.start()