
介面效能測試方案
一、 效能測試術語解釋
1. 響應時間
響應時間即從應用系統發出請求開始,到客戶端接收到最後一個位元組資料為止所消耗的時間。響應時間按軟體的特點再可以細分,如對於一個 C/S 軟體的響應時間可以細分為網路傳輸時間、應用伺服器處理時間、資料庫伺服器處理時間。另外客戶端自身也存在著解析時間、介面繪製呈現時間等。 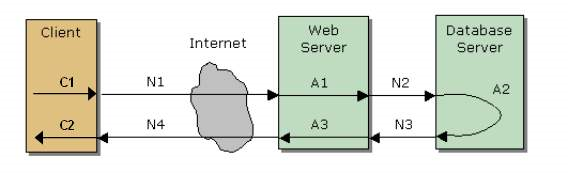
響應時間主要站在客戶端角度來看的一個性能指標,它是使用者最關心、並且容易感知到的一個性能指標。
2. 吞吐率
吞吐率指單位時間內系統處理使用者的請求數,從業務角度看,吞吐率可以用每秒請求數、每秒事務數、每秒頁面數、每秒查詢數等單位來衡量。從網路角度看,吞吐率也可以用每秒位元組數來衡量。
吞吐率主要站在服務端的角度來看的一個性能指標,它可以衡量整個系統的處理能力。對於叢集或者雲平臺來說,吞吐率指標反映的是伺服器叢集對外整體能夠承受的壓力,該指標比使用者數更容易對比。
備註:吞吐量 = 吞吐率 * 單位時間
3. 使用者數
對於伺服器叢集或者雲平臺,幾乎都是多使用者系統,系統能提供給多少使用者正常使用,也是一個非常重要的度量指標。我們把這些使用者按照使用系統的時機不同,做如下區分。
系統使用者數(System Users):指系統能夠儲存的使用者量。
線上使用者數(Online Users):指使用者通過身份確認後,處於能正常使用狀態的使用者個數。
併發使用者數(Concurrent users):指在某個時間範圍內,同時正在使用系統的使用者個數。
嚴格併發使用者數(Strictly the number of concurrent users):指同一時刻都操作某個業務的使用者數。
在效能測試過程中,我們要去模擬實際使用者來發請求。但是為了吐伺服器產生更大的壓力,我們模擬的使用者操作和實際的使用者操作存在一定的差異(比如模擬的使用者請求比實際使用者的請求更頻繁),而且返種模擬的使用者數和實際的使用者數也難以相互換算。所以在度量伺服器叢集能力時,吞吐率指標比使用者數指標更實用。
二、 效能測試方法及目標
1. 效能測試方法
1.1 基準測試(Benchmark Testing)
基準測試是基於一定規模的資料量上進行單業務或按實際使用者操作同比例組合業務的測試,目的在於量化響應時間、吞吐率的指標,便於後續比對。
方法是做多組不同場景的測試,觀察結果,抽取出幾個關鍵資料做好記彔,用於以後進行效能對比和評價。
1.2 效能測試(Performance Testing)
通過模擬生產執行的業務壓力量和使用場景組合,測試系統的效能是否滿足生產效能要求。
特點:
(1) 主要目的是驗證系統是否具有系統宣稱的能力。
(2) 需要事先了解被測系統的典型場景,並具有確定的效能目標。
(3) 要求在已確定的環境下執行。
1.3 負載測試(Load Testing)
通過在被測系統上不斷增加壓力,直到效能指標,例如“響應時間”超過預定指標或者某種資源使用已經達到飽和狀態。
特點:
(1) 主要目的是找到系統處理能力的極限。
(2) 需要在給定的測試環境下進行,通常也需要考慮被測系統的業務壓力量和典型場景,使得測試結果具有業務上的意義。
(3) 一般用來了解系統的效能容量,或是配合效能調優使用。
1.4 壓力測試(Stress Testing)
測試系統在一定飽和狀態下,例如CPU、記憶體等在飽和使用情況下,系統能夠處理的會話能力,以及系統是否會出現錯誤。
特點:
(1) 主要目的是檢查系統處於壓力情況下是應用的表現。
(2) 一般通過模擬負載等方法,使得系統的資源使用達到較高水平。
(3) 一般用於測試系統的穩定性。
1.5 配置測試(Configuration Testing)
通過對被測系統的軟/硬體環境的調整,瞭解各種不同環境對系統性能影響的程度,從而找到系統各項資源的最優分配原則。
特點:
(1) 主要目的是瞭解各種不同因素對系統性能影響的程度,從而判斷出最值得進行得調優操作。
(2) 一般在對系統性能狀況有初步瞭解後進行。
(3) 一般用於效能調優和規劃能力。
1.6 併發測試(Concurrency Testing)
通過模擬使用者的併發訪問,測試多使用者併發訪問同一個應用、同一個模組或者資料記錄時是否存在死鎖或者其他效能問題。
特點:
(1) 主要目的是發現系統中可能隱藏的併發訪問時的問題。
(2) 主要關注系統可能存在的併發問題,例如系統中的記憶體洩露、執行緒鎖和資源爭用方面的問題。
(3) 可在在開發的各個階段使用,需要相關的測試工具的配合和支援。
1.7 可靠性測試(Reliability Testing)
通過給系統載入一定的業務壓力(例如資源在70%~90%的使用率)的情況下,讓應用持續執行一段時間,測試系統在這種條件下是否能穩定執行。
特點:
(1) 主要目的是驗證系統是否支援長期穩定的執行。
(2) 需要在壓力下持續一段時間的執行。
(3) 需要關注系統的執行狀況。
1.8 失效恢復測試(Failover Testing)
針對有冗餘備份和負載均衡的系統設計的,可以用來檢驗如果系統局部發生故障,使用者是否能夠繼續使用系統;以及如果這種情況發生,使用者將受到多大程度的影響。
特點:
(1) 主要目的是驗證在區域性故障情況下,系統能否繼續使用。
(2) 還需要指出,當問題發生時“能支援多少使用者訪問”的結論和“採取何種應急措施”的方案。
(3) 一般來說,只有對系統持續執行指標有明確要求的系統才需要進行這種型別的測試。
2. 效能測試目標
概況來說,可分為4個方面:
2.1 能力驗證
在系統測試或驗收測試時,我們需要評估系統的能力,衡量系統的效能指標。系統的能力可以是容納的併發使用者數,也可能是系統的吞吐率;系統的效能指標可以是響應時間,也可以選擇 CPU、記憶體、磁碟、網路的使用情況。
特點:
(1) 要求在已確定的環境下進行。
(2) 需要根據典型場景設計測試方案和用例。
一般採用的方法是:效能測試、壓力測試、可靠性測試、失效恢復測試。
2.2 能力規劃
評估某系統能否支援未來一段時間內的使用者增長或是應該如何調整系統配置,使得系統能夠滿足增長的使用者數的需要。
特點:
(1) 屬於一種探索性的測試
(2) 可被用來了解系統的效能以及獲得擴充套件效能的方法,例如系統擴容規劃。系統容量可以是使用者容量,也可能是資料容量,或者是系統的吞吐量(系統的處理能力)。對於叢集服務我們更多的是用吞吐率作為容量。
方法是①先對各子系統、元件進行效能測試,找出它們之間的最優配比;②然後再通過各環節的水平擴充套件,計算出整體的擴容機器配比。
一般採用的方法是:負載測試、壓力測試、配置測試。
2.3 效能調優
為了更好的發揮系統的潛能,定位系統的瓶頸,有針對性的進行系統優化。
方法是在進行系統調優時,我們需要做好基準測試,用以對比效能資料的變化,並反覆調整系統軟硬體的設定,以使系統發揮最優效能。當然在進行系統優化時,我們會選取關鍵的指標進行優化,返時可能要犧牲其他的效能指標。如目標是優化響應時間,我們可能選取的策略是以空間換時間,以犧牲記憶體或擴大快取為代價,還需要我們在各個效能指標中找到平衡點。
一般對系統的調整包括以下3個方面:
(1) 硬體環境的調整
(2) 系統設定的調整
(3) 應用級別的調整
一般採用的方法是:基準測試、負載測試、壓力測試、配置測試和失效恢復測試。
2.4 發現缺陷
和其他測試一樣,效能測試也可以發現缺陷。特別是嚴格併發訪問時是否存在資源爭奪導致的響應時間過慢,或大量使用者訪問時是否導致程式崩潰。
方法是設定集合點,實現嚴格併發使用者訪問;或者設定超大規模使用者突發訪問等這樣的效能測試用例進行測試。
一般採用的方法是:併發測試。
三、 效能需求分析
1. 效能需求獲取
1.1 功能規格說明書
1.2 系統設計文件
1.3 運營計劃
1.4 使用者行為分析記錄
2. 效能關鍵點選取
主要從以下4個維度進行選取:
2.1 業務分析
確定被測介面是否屬於關鍵業務介面或先分析出關鍵業務以間接獲取該業務所訪問的介面。
2.2 統計分析
若介面系統訪問行為存在日誌分析記錄,則直接獲取日訪問量高的介面;否則根據介面釋出型別,選擇第3方日誌分析工具間接獲取。
(1) IIS日誌分析工具:Log Parser 2.2 + Log Parser Lizard GUI
下載地址:
(2) Tomcat日誌分析工具:AWStats v7.3
下載地址:http://www.awstats.org
(3) Nginx日誌分析工具:GoAccess v0.9
若IIS或Tomcat等介面應用伺服器使用Nginx進行負載,則日誌訪問量要以負載為準,因避免介面在Nginx設定快取(即未進行透傳)而導致統計不正確。
下載地址:http://www.goaccess.io
2.3 技術分析
(1) 邏輯實現複雜度高的介面(如判斷分支過多或涉及CPU/IO密集型運算等)
(2) 對系統(記憶體、CPU、磁碟IO)及網路IO等硬體資源耗用高的介面
備註:若介面因邏輯修改而重構,則需重新分析。
2.4 運營分析
由於運營推廣活動導致日訪問突增高的介面。
備註:若運營計劃調整,則需重新分析。
3. 效能指標描述
3.1 響應時間
在一般情況下,弱互動類介面平均響應時間不超過1秒,強互動類介面平均響應時間不超過200毫秒。
3.2 成功率
在一般情況下,介面響應成功率需達到99.99%以上。
3.3 系統資源
若為最佳負載,則系統CPU及記憶體使用率建議區間[50%,80%],否則建議不超過50%。
3.4 處理能力
立項申請書明確要求:在XX壓力下(併發數)TPS需達到XX或 介面系統可支撐XX萬實時線上訪問。
3.5 穩定性
在實際系統執行壓力情況下,可穩定執行N*24(一般 N >= 7 )小時。 在高於實際系統執行壓力1倍的情況下,可穩定執行12小時。
3.6 特性指標
例:
四、 效能測試範圍
1. 業務範圍
關鍵業務功能點描述。
2. 設計範圍
網路接入層、介面層、中介軟體、儲存層等被測元件及拓撲結構描述。
五、 併發數計算方法
做過一些效能測試的童鞋剛開始比較糾結某個或某一類介面的併發數如何計算,其實併發數可以從使用者業務和伺服器的2個角度來看。
1. 80/X原則
適用範圍:無限制
以一專案為案例,母親節當天介面伺服器訪問量分佈如下所示,如何計算當天平均併發數和高峰併發數? 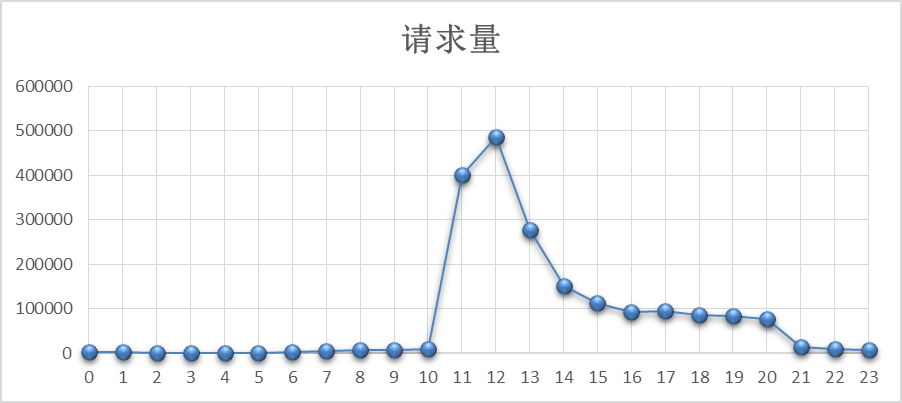
通過百度統計平臺 http://tongji.baidu.com/ 檢視母親節當天UV曲線分佈 與 請求量呈線性關係,如下所示:
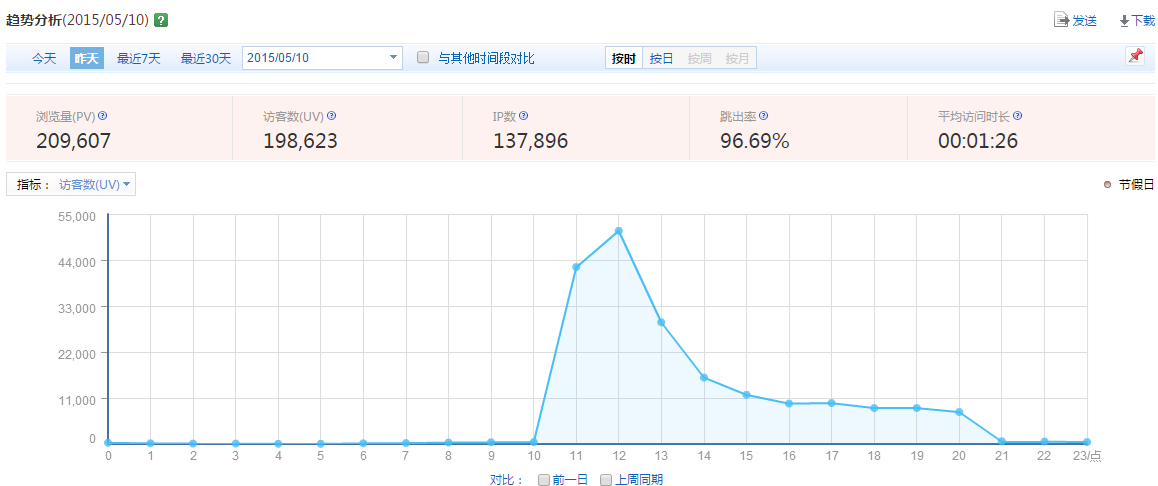
採用微積分的思想,將每個時間點視為一個矩形,可以通過求和的方式求出整個分佈圖的面積,如下所示:
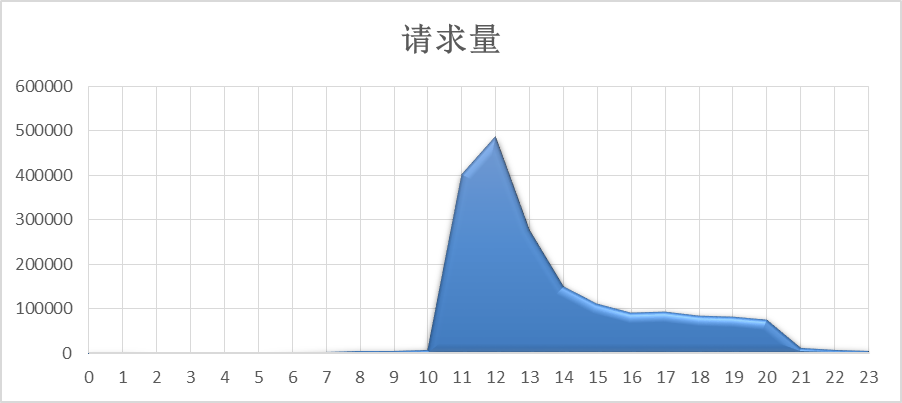
其實每個矩形的長度均為1(1小時),故求面積時只需考慮寬度,即考慮每小時請求量即可。
根據80/X原則,找出佔據總體面積80%的時間,選擇儘可能大的點計算出佔據總體面積80%的時間,發現點的個數是7,意味著此時間長度佔總時間長度30%,則80/X原則轉換成80/30原則,如下所示:
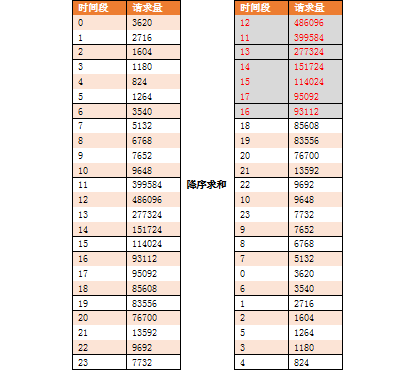
故,平均併發數(每秒平均請求數)= 80% * 日請求量 / 1天 * 30%
進而計算出最高峰值與平均併發數的倍數 = 2.25
故,高峰併發數(每秒高峰請求數)= 2.25 * 平均併發數 =
2.25 * 80% * 日請求量 / 1天 * 30% = 6 * 日請求量 / 1天
因UV與請求量曲線分佈呈線性關係,日請求量 = 9.25 * 日UV
故,高峰併發數 = 6 * 9.25 * 日UV / 1天 = 55.5 * 日UV / 1天
2. 公式法
適用範圍:Web類訪問
公式(1)計算平均併發使用者數:C = n * L / T
C是平均的併發使用者數;n是login session的數量;L是login session的平均長度;T指考察的時間段長度。
公式(2)計算併發使用者數峰值: C’≈ C+3根號C
C’指併發使用者數的峰值,C就是公式(1)中得到的平均的併發使用者數。該公式的得出是假設使用者的login session產生符合泊松分佈而估算得到的。 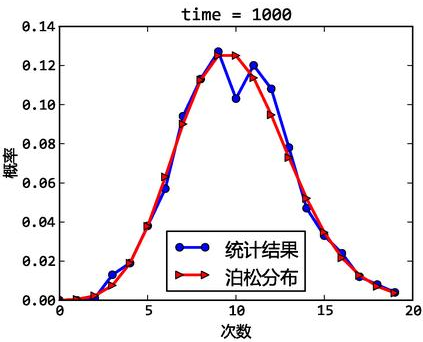
例1:
假設有一個OA系統,該系統有3000個使用者,平均每天大約有400個使用者要訪問該系統,對一個典型使用者來說,一天之內使用者從登入到退出該系統的平均時間為4小時,在一天的時間內,使用者只在8小時內使用該系統。
C = 400 * 4 / 8 = 200
C’≈ 200 + 3 * 根號200 = 242
為了更好地理解上述公式,將其轉換為如下公式:
公式(3)併發使用者數 = 吞吐率 * 場景業務時間 / 單位時間段
例2:
一個OA系統,1小時內有8000使用者登入系統。使用者每次登入系統,需啟動登入頁面,然後輸入使用者名稱和密碼,進入首頁。一般情況下,使用者在上述操作過程中需耗時5秒,且要求從點選登入按鈕到首頁完全展現,需控制在5秒內。
分析:
吞吐率 = 8000 * 2(整個業務操作需載入2次頁面才能完成)
場景業務時間 = 5 + 5 = 10 秒
單位時間段 = 1小時 = 3600 秒
併發使用者數(登入場景) = (8000 * 2)* 10 / 3600 = 45
通過以上方法得到業務併發數後,我們可以進一步分析業務訪問了哪些介面,我們只要模擬這些介面呼叫方式和呼叫時序就行了。
有時我們需要計算某一個或某一類介面的併發數,我們可以按如下步驟進行分析計算:
(1) 梳理出被測介面被訪問的業務場景和每個業務場景訪問的次數
(2) 通過上述方法計算出業務場景的併發使用者數
介面併發數 = 場景1 併發使用者數 * 業務場景介面呼叫次數1 + 場景2併發使用者數 * 介面呼叫次數2 + …
假如一個系統需支撐10萬線上使用者數訪問,如何通過效能需求分析來計算併發使用者數?大家可以通過以上內容學習,獨立思考下?
六、 效能測試用例與場景
- 指令碼模板
- 場景模板
七、 效能測試工具選擇
1. 資料建模工具
DataFactory是一種強大的資料產生器,它允許開發人員和QA很容易產生百萬行有意義的正確的測試資料庫,該工具支援DB2、Oracle、
Sybase、SQL Server資料庫,支援ODBC連線方式,無法直接使用MySQL資料庫,可間接支援。
2. 指令碼開發工具
(1) 若考慮指令碼執行效率,則可考慮底層開發語言C或支援非同步通訊的語言JS,我們可以分別選擇:Loadrunner 或 Node.js 的IDE環境進行開發。
(2) 若考慮指令碼開發效率,則可考慮程式碼複用性,可以選擇面嚮物件語言C#或Java,為此我們可以分別選擇:VS2008及以上版本 + 對應LR.NET控制元件
或者 Eclipse4.0及以上版本 + JDK1.7及以上版本。
HTTP、Socket等協議介面效能測試指令碼開發過程,請詳見附件:
HTTP介面效能測試之指令碼開發與效能問題分析.pdf
利用LR.Net控制元件完成效能測試指令碼編寫方法.pdf
node.js學習入門手冊.pdf
3. 壓力模擬工具
(1) 若為Java類介面且單機併發數控制在500內,則可選擇Jmeter或者 Loadrunner。
(2) 若為WebService類介面且單機併發數控制在500內,則可選擇SoapUI或者Loadrunner。
(3) 若單機併發數超過500且控制在5000內,則可選擇Loadrunner。
(4) 若單機併發數超過5000,則建議採用負載叢集,即採用“中控(Control Center)+ 多機部署(Load Generator)”方案。
4. 效能監控工具
4.1 監控工具
無論Windows或Linux平臺,一般存在的是一個或一組程序例項,我們可以選擇Loadrunner 或 Nmon 來監控。有時為了獲取被測應用的一些特性指標,可以選擇被測元件自帶的效能工具集或監控系統。常見應用伺服器監控工具推薦如下: 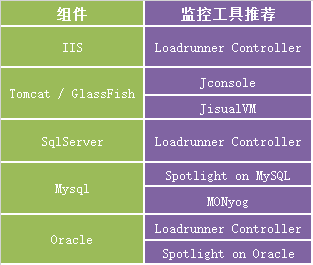
4.2 監控平臺
監控機器主要對被測叢集伺服器的服務或資源使用情況進行監控,比如各種開源的監控工具,MRTG:流量監控;CACTI:流量預警,效能報告Smokeping:IDC 質量監控;綜合監控:Nagios、Zenoss、Ganglia 、Zabbix、Sitescope、Hyperic HQ 等,如下所示: 
4.3 第三方監控雲服務(APM)
APM提供端到端應用效能管理軟體及應用效能監控軟體解決方案,包含移動,瀏覽器,應用,基礎設施,網路,資料庫效能管理等,支援Java、.NET、PHP、Ruby、Python、Node.js、iOS、Android、HTML5等應用效能監控管理,主流雲服務包括聽雲、OneAPM等,如下所示:
八、 效能測試結果分析
1. 指標分析
效能測試的指標可分為產品指標和資源指標兩類。對測試人員而言,效能測試的需求來自於使用者、開發、運維的三方面。使用者和開發關注的是與業務需求相關的產品指標,運維人員關注的是與硬體消耗相關的資源指標。 
(1) 從使用者角度關注的指標
使用者關注的是單次業務相關的體驗效果,譬如一次操作的響應快慢、一次請求是否成功、一次連線是否失敗等,反映單次業務相關的指標包括:
a.成功率b.失敗率c.響應時間
(2) 從開發角度關注的指標
開發人員更關注的是系統層面的指標。
a.容量:系統能夠承載的最大使用者訪問量是多少?系統最大的業務處理量是多少?
b.穩定性:系統是否支援7*24小時(一週)的業務訪問。
(3) 從運維角度關注的指標
運維人員更關注的是硬體資源的消耗情況。 
以上說明了測試人員在選擇指標時需站在使用者角度去思考,另外為了後續能夠更好地分析問題,更需掌握與被測元件特性或執行原理相關的效能指標。
舉例來說,通常介面系統均會直接或間接地訪問資料庫層介質(如Mysql、Oracle、SQLServer等),此時我們需考慮由介面系統產生壓力下儲存介質的效能情況,通常我們會選擇分析指標如下:
(1) 連線數(Connections)
(2) 每秒查詢數/每秒事務數(QPS/TPS)
(3) 每秒磁碟IO數(IOPS)
(4) 快取命中率(Buffer Hits)
(5) 每秒發生的死鎖數(Dead Locks/sec)
(6) 每秒讀/寫位元組數(Read/Write Bytes/sec)
對於Windows或Linux平臺具體指標監控及分析方法,請詳見附件:
《Windows作業系統效能監控工具和指標分析V1.0》.pdf
《Linux作業系統效能監控分析手冊V1.0》.docx
2. 建模分析
2.1 理髮店模型 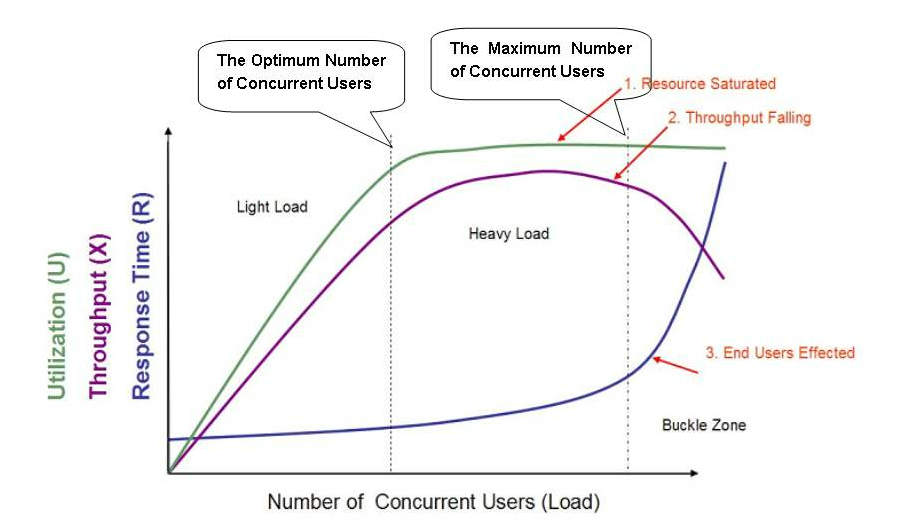
圖中展示的是1個標準的軟體效能模型。在圖中有三條曲線,分別表示資源的利用情況(Utilization,包括硬體資源和軟體資源)、吞吐量(Throughput,這裡是指每秒事務數)以及響應時間(Response Time)。圖中座標軸的橫軸從左到右表現了併發使用者數(Number of Concurrent Users)的不斷增長。
在這張圖中我們可以看到,最開始,隨著併發使用者數的增長,資源佔用率和吞吐量會相應的增長,但是響應時間的變化不大;不過當併發使用者數增長到一定程度後,資源佔用達到飽和,吞吐量增長明顯放緩甚至停止增長,而響應時間卻進一步延長。如果併發使用者數繼續增長,你會發現軟硬體資源佔用繼續維持在飽和狀態,但是吞吐量開始下降,響應時間明顯的超出了使用者可接受的範圍,並且最終導致使用者放棄了這次請求甚至離開。
根據這種效能表現,圖中劃分了三個區域,分別是Light Load(較輕的壓力)、Heavy Load(較重的壓力)和Buckle Zone(使用者無法忍受並放棄請求)。在Light Load和Heavy Load 兩個區域交界處的併發使用者數,我們稱為“最佳併發使用者數(The Optimum Number of Concurrent Users)”,而Heavy Load和Buckle Zone兩個區域交界處的併發使用者數則稱為“最大併發使用者數(The Maximum Number of Concurrent Users)”。
當系統的負載等於最佳併發使用者數時,系統的整體效率最高,沒有資源被浪費,使用者也不需要等待;當系統負載處於最佳併發使用者數和最大併發使用者數之間時,系統可以繼續工作,但是使用者的等待時間延長,滿意度開始降低,並且如果負載一直持續,將最終會導致有些使用者無法忍受而放棄;而當系統負載大於最大併發使用者數時,將註定會導致某些使用者無法忍受超長的響應時間而放棄。所以我們應該保證最佳併發使用者數要大於系統的平均負載。
2.2 壓力變化模型 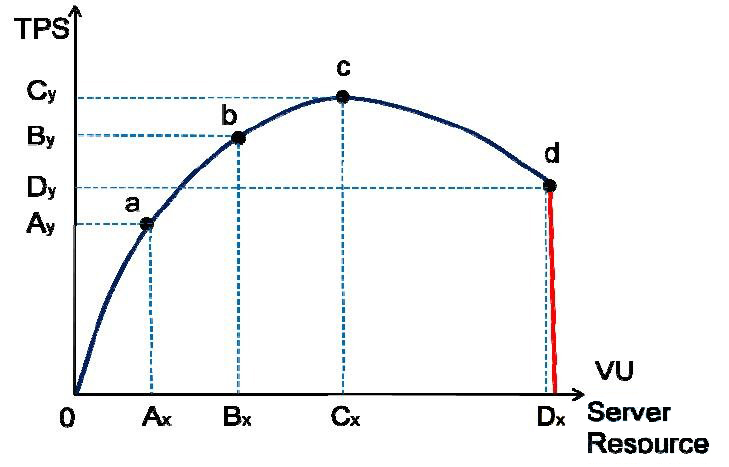
隨著單位時間流量的不斷增長,被測系統的壓力不斷增大,伺服器資源會不斷被消耗,TPS 值會因為這些因素而發生變化,而且符合一定的規律。
圖中:
a 點:效能期望值
b 點:高於期望,系統資源處於臨界點
c 點:高於期望,拐點
d 點:超過負載,系統崩潰
2.3 容量計算模型
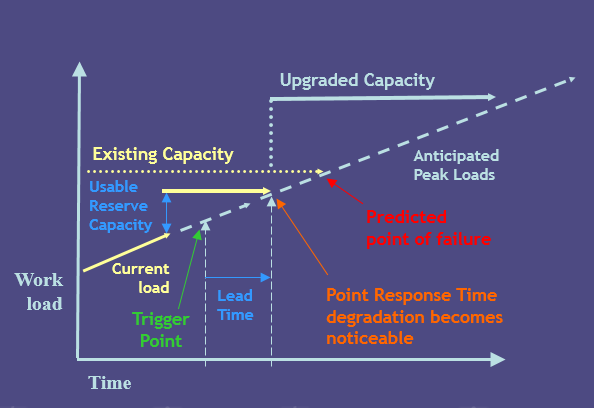
以一網站效能測試為案例:
1. 通過分析運營資料,可以知道當前系統每小時處理的PV數
2. 通過負載測試,可以知道系統每小時最大處理的PV數
即整理得
系統每小時PV處理剩餘量 = 系統每小時最大處理的PV數 — 系統每小時處理的PV數
假設該網站使用者負載基本呈線性增長,現有系統使用者數為70萬,根據運營推廣計劃,1年內該網站發展使用者將達到1000萬,即增長了14倍。即整理得:
系統每小時PV處理增加量 = 當前系統每小時處理的PV數 * 14 — 當前系統每小時處理的PV數
每天系統負載增加率 = 100% / 365 = 2.74 % (備註:此處將未來系統使用者數達到1000萬的負載定義為 100% )
系統每天PV處理增加量 = 系統每小時PV處理增加量 * 每天系統負載增加率 * 24
所以,我們可以知道在正常負載條件下:
系統可支援正常執行天數 = 系統每小時PV處理剩餘量 * 24 / 系統每天PV處理增加量
假設該網站後續部署升級天數已知,這樣我們可以知道提前升級的天數:
系統可支援正常執行天數 — 部署升級天數。
九、 效能測試通過標準
1. 所有計劃的測試已經完成。
2. 所有計劃收集的效能資料已經獲得。
3. 所有效能瓶頸得到改善並達到設計要求。
十、 效能測試書籍推薦




十一、 效能測試報告模板
詳見附件:
效能測試報告模板.doc